

boom boom! Hello Cloud!
どうも、しみちゃんでございます。
今回は Spanner のディザスターリカバリ対応方法について、紹介をしたいと思います。
Cloud Spanner とは?
ざっくりと説明すると リレーショナル データベースの構造 を持ちながら、 非リレーショナル データベースの水平スケーリング機能 を備えたフルマネージドな Google のデータベースサービスです。
公式ドキュメント: Cloud Spanner
バックアップについて
実は、下記の spanner のバックアップでは リージョンをまたいで復元ができません
gcloud spanner backups create ${instance}-${database}-${database} \
--instance=${instance} \
--database=${database} \
--retention-period=${period} \
--async
実行結果
# gcloud spanner databases restore --async \
--destination-instance=shimizu-us-recovery \
--destination-database=recovery_test \
--source-instance=shimizu \
--source-backup=shimizu-recovery_test-20200717_173700
ERROR: (gcloud.spanner.databases.restore) INVALID_ARGUMENT: Cannot create database projects/grasys-dev/instances/shimizu-us-recovery/databases/recovery_test from backup projects/grasys-dev/instances/shimizu/backups/shimizu-recovery_test-20200717_173700 because the backup and the database are in instances with different instance configurations. Database instance instance_configuration: projects/grasys-dev/instanceConfigs/nam3, Backup instance instance_configuration: projects/grasys-dev/instanceConfigs/asia1.
理由は 同じインスタンス構成じゃない からです。
リージョンが違うと、動作しないようです。
The new database must be in the same project as the backup and be in an instance with the same instance configuration as the backup. For example, if a backup is in an instance configured us-west3, it can be restored to any instance in the project that is also configured us-west3
引用: https://cloud.google.com/spanner/docs/backup#restore
じゃあ、どうすんねん
リージョンを跨いでバックアップを行うにはどうするか、というと Data Flow を使用して GCS へバックアップを行います
ディザスターリカバリ
では早速、バックアップを作成して、別のリージョンに Spanner インスタンスにインポートを行ってみましょう
コマンドラインから
GCPコンソールからでも簡単にできるのですが、 自動化したいので、 gcloud コマンドで実行を試してみましょう。
コマンドラインから実行するには、 gcloud dataflow コマンドを使用します。
DataFlowのテンプレートを使用してみます。
参照: Cloud Spanner to Cloud Storage Avro
gcloud dataflow jobs run [JOB_NAME]
–gcs-location=‘gs://dataflow-templates/[VERSION]/Cloud_Spanner_to_GCS_Avro’
–region=[DATAFLOW_REGION]
–parameters=‘instanceId=[YOUR_INSTANCE_ID],databaseId=[YOUR_DATABASE_ID],outputDir=[YOUR_GCS_DIRECTORY]
ほうほう。さっそく実行してみましょう
# gcloud dataflow jobs run shimizu-recovery_test-20200717_192644 \
--gcs-location=gs://dataflow-templates/latest/Cloud_Spanner_to_GCS_Avro \
--region=us-east1 \
--parameters=instanceId=shimizu,databaseId=recovery_test,outputDir=gs://shimizu_recv_test/shimizu/recovery_test
createTime: '2020-07-17T10:26:47.326894Z'
currentStateTime: '1970-01-01T00:00:00Z'
id: 2020-07-17_03_26_46-12461804407310305089
location: us-east1
name: shimizu-recovery_test-20200717_192644
projectId: grasys-dev
startTime: '2020-07-17T10:26:47.326894Z'
type: JOB_TYPE_BATCH
確認
# gcloud dataflow jobs list --region=us-east1
JOB_ID NAME TYPE CREATION_TIME STATE REGION
2020-07-17_03_26_46-12461804407310305089 shimizu-recovery_test-20200717_192644 Batch 2020-07-17 10:26:47 Running us-east1
2020-07-17_03_22_46-13106556587330949927 shimizu-recovery_test-20200717_192243 Batch 2020-07-17 10:22:47 Done us-east1
うまく動いていそうですね。
# gcloud dataflow jobs list --region=us-east1
JOB_ID NAME TYPE CREATION_TIME STATE REGION
2020-07-17_03_26_46-12461804407310305089 shimizu-recovery_test-20200717_192644 Batch 2020-07-17 10:26:47 Done us-east1
2020-07-17_03_22_46-13106556587330949927 shimizu-recovery_test-20200717_192243 Batch 2020-07-17 10:22:47 Done us-east1
では、復旧してみましょう。
GCPコンソールから簡単にできるので、それを試してみます。
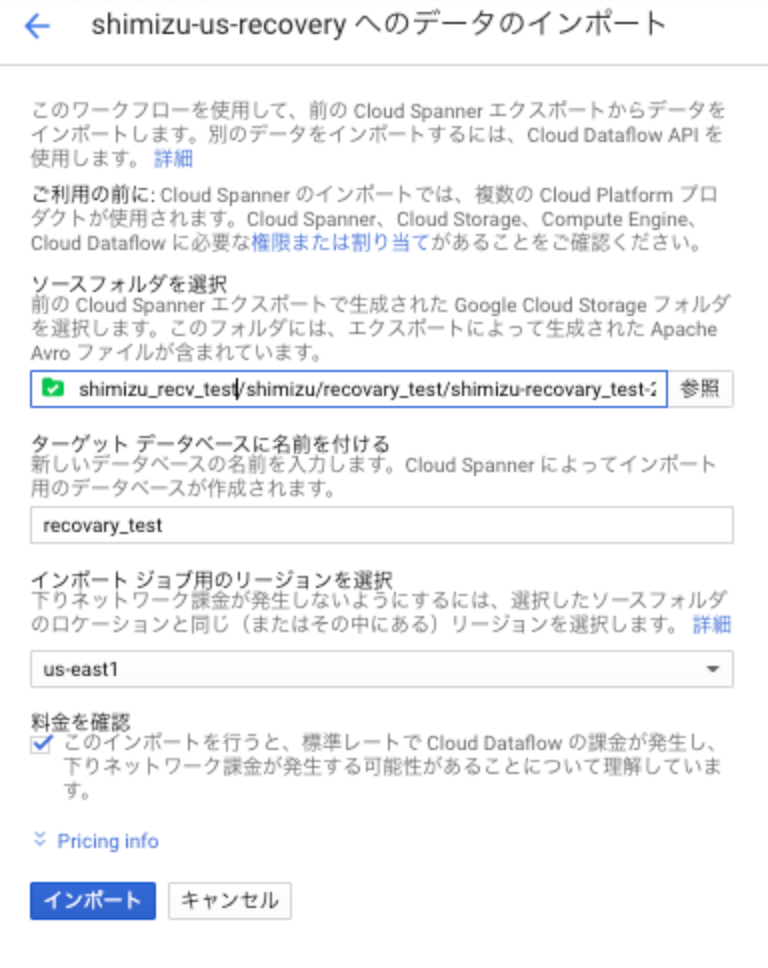
ジョブが完了したら、成功しているかチェックして終わりです
おまけ
ちなみに、コマンドラインから実行するには下記のテンプレートジョブを使用すると良いようです。
gcloud dataflow jobs run [JOB_NAME]
–gcs-location=‘gs://dataflow-templates/[VERSION]/GCS_Avro_to_Cloud_Spanner’
–region=[DATAFLOW_REGION]
–parameters=‘instanceId=[YOUR_INSTANCE_ID],databaseId=[YOUR_DATABASE_ID],inputDir=[YOUR_GCS_DIRECTORY]’
参照: Cloud Storage Avro to Cloud Spanner

株式会社grasys(グラシス)は、技術が好きで一緒に夢中になれる仲間を募集しています。
grasysは、大規模・高負荷・高集積・高密度なシステムを多く扱っているITインフラの会社です。Google Cloud (GCP)、Amazon Web Services (AWS)、Microsoft Azureの最先端技術を活用してクラウドインフラやデータ分析基盤など、ITシステムの重要な基盤を設計・構築し、改善を続けながら運用しています。
お客様の課題解決をしながら技術を広げたい方、攻めのインフラ技術を習得したい方、とことん技術を追求したい方にとって素晴らしい環境が、grasysにはあります。
お気軽にご連絡ください。





