

目次
データ分析をするための様々なサービスが世の中にありますが、導入までの期間やコストは気になりますよね。
手軽に卓上である程度分析することもできます。どうすればよいかこの記事で整理していきます。
必要なもの
- Windows/macOSどちらでもよいのでPython3.6以上がインストールされているPC
- Python教材!
- 分析したいデータ
必要なこと
- データを手に入れる
- データを汎用的なファイルフォーマットに変換する
- データを分析する
- 分析結果を出力する
データを手に入れる
Pythonでデータ分析をするということは取り扱うデータの大きさが大きくなるかもしれず今後のシステム化も視野に入れてCSVファイルフォーマットで手に入れたいですよね
今回はとりあえずこちらのExcelファイルフォーマットを受け取ったという話で進めていきます
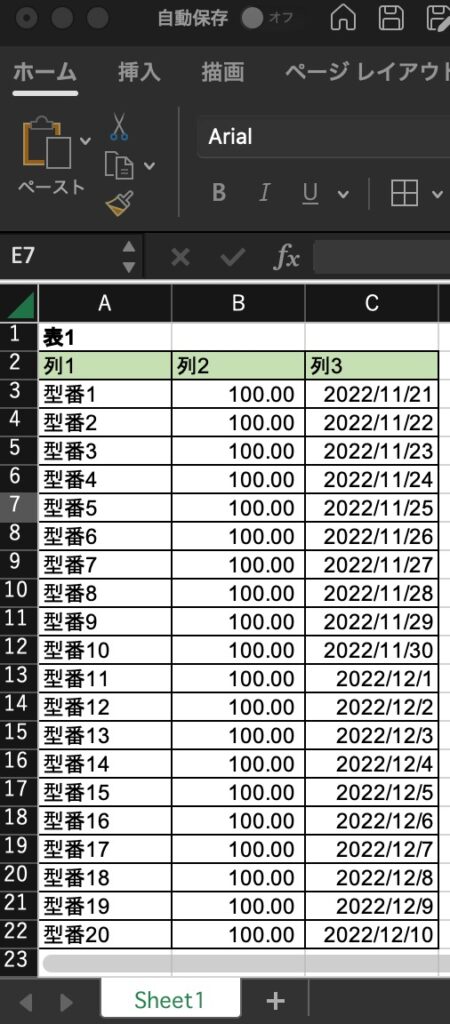
データを汎用的なファイルフォーマットに変換する
Windows、macOSどちらでも良いですがPythonがインストールされているPCでExcelファイルをPythonで読み込むツールをインストールします
pip install openpyxlこちらのツールのドキュメント(英語)はこちらです
openpyxlの特徴
- xlsx/xlsm/xltx/xltmファイル形式をPythonで読み書きするツール
- 日本語記事もたくさん見つかる有名なツール
プログラムを書き始めますが、変換処理を記述するまえにいったん動作確認しましょう
main.pyファイルを下記のように作成します
以下それぞれ書き換えてください
- file_name=にはExcelの保存場所
- sheet_name=にはExcelシートの名前
from openpyxl.cell.cell import Cell
from openpyxl import load_workbook
def load_excel(file_name, sheet_name):
wb = load_workbook(filename=file_name, read_only=True)
ws = wb[sheet_name]
for row in ws.rows:
a: Cell
b: Cell
c: Cell
a, b, c = row
print(f"a: {a.value}, b: {b.value}, c: {c.value}")
wb.close()
if __name__ == '__main__':
load_excel(file_name="/Users/nishino/Downloads/Book1.xlsx", sheet_name="Sheet1")記述が終わったらプログラムを実行します
python main.py動作しましたか?PythonがExcelシートの中身を認識して読み込めている様子が見えます
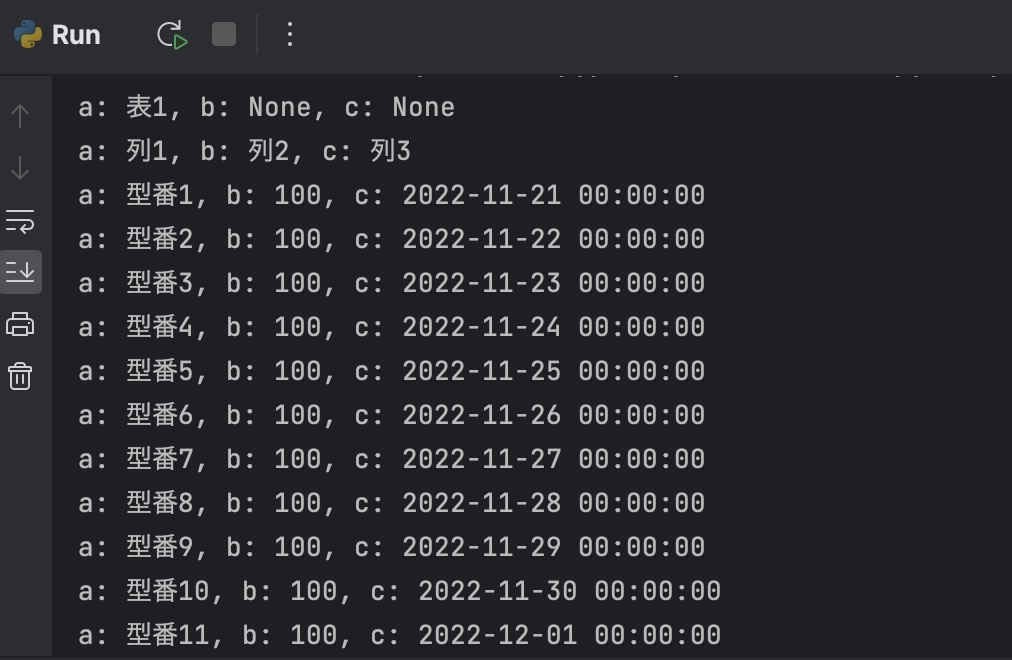
先頭の2行は表の見出し、3行目以降に分析すべきデータが表示されていますね
ファイルフォーマットと合わせて、分析に必要ない行は削除していきます
続いてファイルフォーマットを変換するためにツールを追加インストールする必要があります
pip install pyarrowこちらのツールのドキュメント(英語)はこちらです
pyarrowの特徴
- Apache ArrowというソフトウェアのPython版
- 高性能な分析ツール
さきほどmain.pyに記述していただいた内容を下記のように書き換えます
ファイルフォーマットを変換するプログラムです
以下それぞれ書き換えてください
- output_file_name=には変換後のファイル保存場所
from openpyxl import load_workbook
import pyarrow as pa
import pyarrow.csv as csv
def load_excel(file_name, sheet_name):
wb = load_workbook(filename=file_name, read_only=True)
ws = wb[sheet_name]
a_values = []
b_values = []
c_values = []
for row in ws.rows:
_a, _b, _c = row
a_values.append(_a.value)
b_values.append(_b.value)
c_values.append(_c.value)
wb.close()
return a_values, b_values, c_values
def cleanse_data(rows1, rows2, rows3):
# テーブルの見出しなど先頭2行を除く
return rows1[2:], rows2[2:], rows3[2:]
def export_csv(rows1, rows2, rows3, output_file_name):
options = csv.WriteOptions(include_header=False)
table = pa.table([rows1, rows2, rows3], names=["A", "B", "C"])
csv.write_csv(table, output_file=output_file_name, write_options=options)
if __name__ == '__main__':
a, b, c = load_excel(file_name="/Users/nishino/Downloads/Book1.xlsx", sheet_name="Sheet1")
cleansed_a, cleansed_b, cleansed_c = cleanse_data(a, b, c)
a_rows = pa.array(cleansed_a, type=pa.string())
b_rows = pa.array(cleansed_b, type=pa.float64())
c_rows = pa.array(cleansed_c, type=pa.timestamp("s"))
export_csv(a_rows, b_rows, c_rows, output_file_name="sheet1.csv")
動作しましたか?新しいファイルが増えてるのでファイルを開いてみてください。
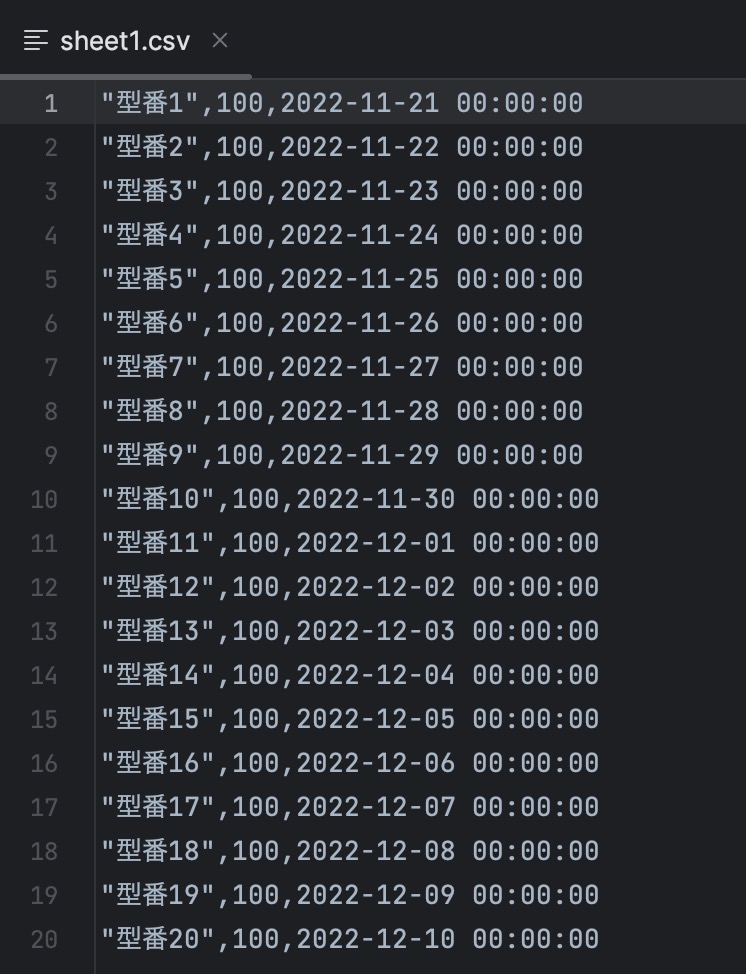
これでデータ分析の準備ができました。
前半はここまでです。
後編では実際にデータ分析をしていきます。


