

目次
こんにちは。エンジニアの山田です。
昨今ではAI(人工知能)の技術も進歩し、徐々に活用され始めていますが、例えば画像認識を使用したAIでは大量に蓄積された画像データから人の特徴や動作を学習(ディープラーニング)し、高い精度で個人を特定することができますし、ECサイトや動画配信サイトで使用されているAIでは個人の閲覧履歴を蓄積、分析し、おすすめを提示してくれます。
また、従来から自社の経営状況をデータとして蓄積し、分析することにより、既存事業の改善や新しい事業の開拓なども行われてきました。
上記の通りデータを分析し、活用することは大半の業務にとってプラスになり得ます。長々と蛇足を書きましたが、今回はそんなデータを分析するためのプラットフォームとして、Google Cloud (GCP)からフルマネージドで難しいコーディングが不要なETLツールが提供されていますので、そちらの紹介をしたいと思います。
Data Fusionとは?
Google Cloud (GCP)で提供されているフルマネージドのETL(Extract (抽出)、Transform (変換)、 Load (格納)サービスです。
主な用途は各種データソースから情報を収集、分析し、結果を必要とするシステム(そのシステムを閲覧する部署や顧客)に連携することになります。
データソースには各種クラウド(Google Cloud (GCP)、AWS、Azure)のストレージサービスに格納されたExcelやCSVといったファイル、データベースサービス(BigQuery、CloudSQL、Datastore)、またはオンプレミスに構築されているデータウェアハウスなどを指定することができます。
ETLサービスは他にもいくつかあると思いますが、Data Fusionを使用するメリットとしては以下があります。
- GUIで設定することができることから、データフローを視覚化でき、データ加工を行うための複雑なコーディングが不要になる。
- ETL処理はHadoop、Apache SparkなどのOSSが採用されたフルマネージドのDataprocサービスが自動で起動して処理を実行するため、実行環境の考慮が不要になる。
- プラグインを追加することにより、Salesforceなどのサードベンダーが提供している外部サービスとのデータ連携が可能になる。
Data Fusionの構築
まずはGCPのコンソール上で data fusionを検索します。

以下のように検索結果に Data Fusion が表示されますのでクリックします。

初回アクセスの場合はAPI(Data Fusion API)の有効化画面が表示されますので有効にします。
有効化が完了するとインスタンスが作成できるようになりますので インスタンスを作成 をクリックします。
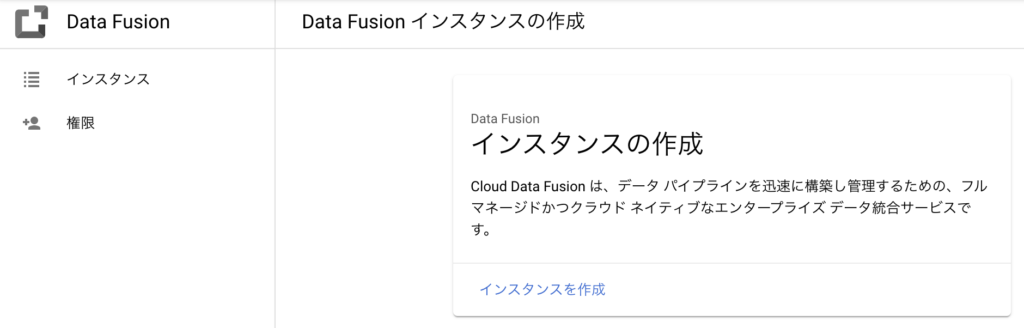
インスタンスの作成に必要なパラメータを入力欄に入力し、作成 ボタンをクリックします。
- インスタンス名:(任意のインスタンス名を入力)
- 説明:任意(Data Fusionインスタンスの用途などを入力)
- リージョン:asia-northeast1(国内利用の場合はasia-northeastを選択)
- バージョン:(デフォルトで Current relase が選択済)
- エディション:(使用用途に応じたエディションを選択 ※)
- Dataprocサービスアカウント:(デフォルトのサービスアカウントが選択済)
※ 詳細オプションを設定する場合は上記以外にも設定が必要になります。(後述)
※ エディションに関する説明は以下の公式ドキュメントに記載されています。
エディションは主に使用人数、環境(開発 or 本番)、高可用性の要否、パイプライン(Data Fusionの処理フロー)の最大同時実行数あたりとコスト感(料金)を考慮して選択する必要があります。
| エディション | ユーザー数 | ワークロード | 高可用性 | 最大同時実行数 | 料金 |
| Developer | 2(推奨) | 開発 | ゾーン | 5 | 約 $250/月 |
| Basic | 無制限 | テスト | リージョン(小容量) | 40 | 約 $1,100/月 |
| Enterprise | 無制限 | 本番 | リージョン(大容量) | 200 | 約 $3,000/月 |
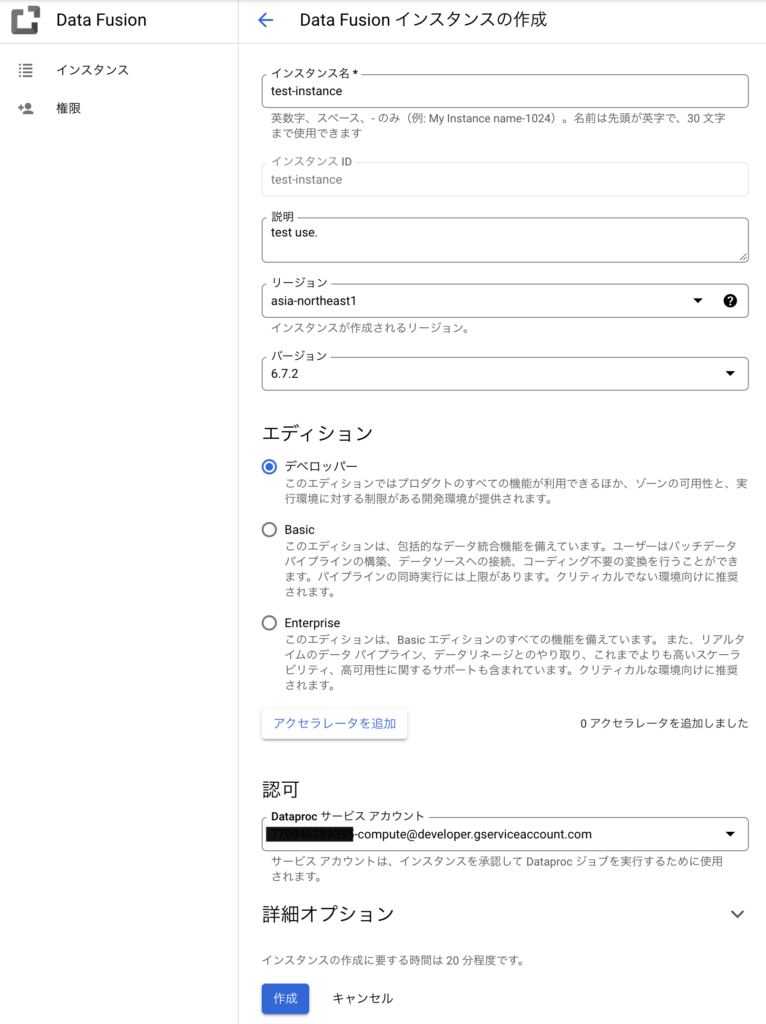
詳細オプションは必要に応じて入力する必要があります。
外部システムとの連携が不要な場合(GCP内部でのみの利用の場合)は プライベートIPを有効化 にチェックを入れて内部接続のみに制限したり、監視(アラート通知)を強化したい場合は Stackdriver Logging サービスを有効にする Stackdriver Monitoring サービスを有効にする のチェックを入れてStackdriver(監視ツール)を有効にしたりすることができます。
パイプライン(データフロー)の作成
インスタンスの作成が完了すると以下の画面が表示されますので インスタンスの表示 のリンクをクリックしてData Fusionの操作画面(GUI)を表示させます。
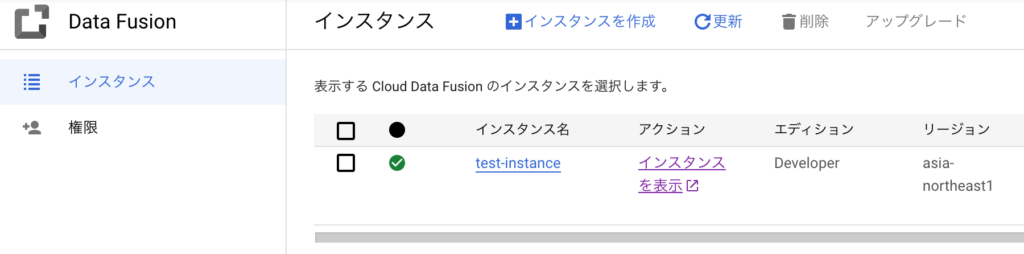
画面が表示されたら左上のハンバーガーメニューをクリックしてメニューを表示させ、Studio をクリックします。
今回はシンプルに以下のフローを作成します。
- GCS上のCSVを読み込む。
- データベースに取り込めるようにCSVのカラムをデータ型に変更する。
- 変換したデータをBigQueryに取り込む。
まず左ペインのSource からGCS をクリックします。
※ 以下の画面がデータフローを作成するGUIの操作画面になります。
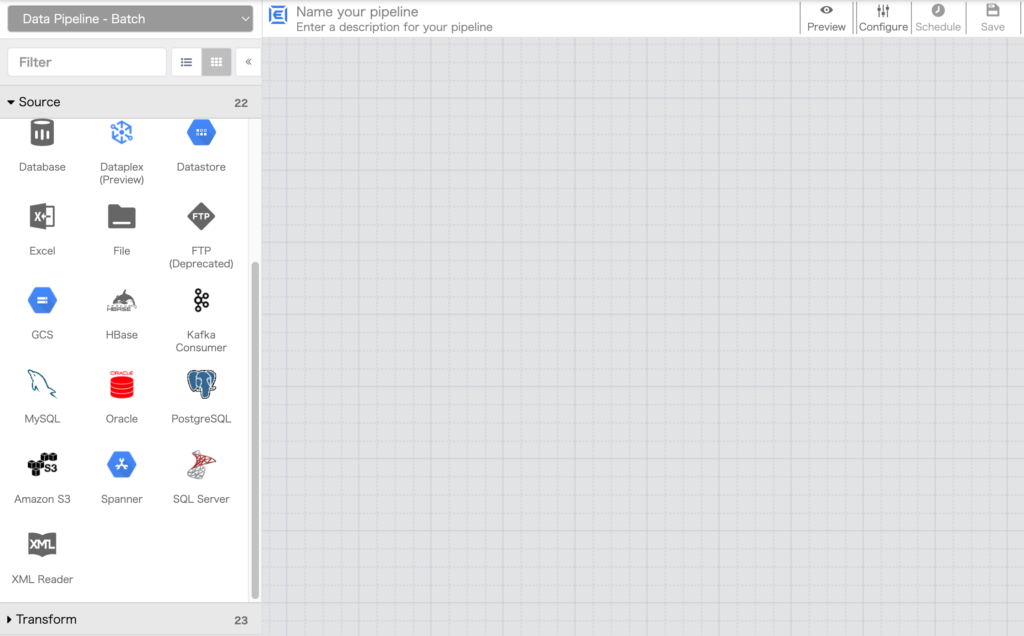
GCSのノード(パイプライン ノード)が生成されますので、ノード内の Properties をクリックします。
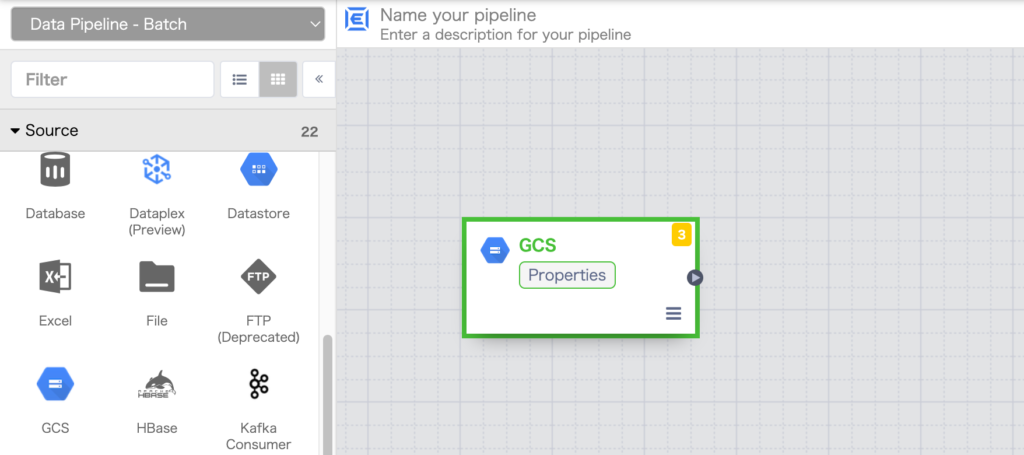
Use Connection をクリックして YES に変更し、BROWSE CONNECTIONS ボタンをクリックします。

Name 列の Cloud Storage Default をクリックします。
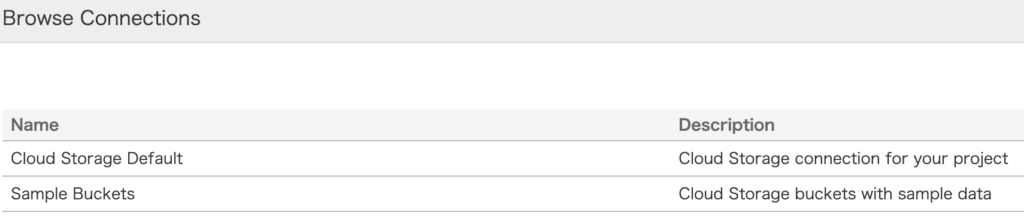
BROWSE ボタンをクリックします。

GCSのバケット一覧からファイルが格納されているバケットをクリックし、取り込む対象のcsvを選択します。
※ 今回は事前にバケットを作成し、データ取り込み用のcsvを格納してあります。(csvファイルの内容は以下)
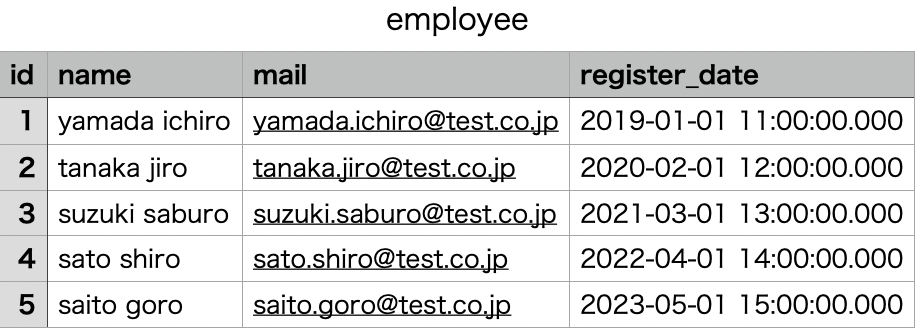

Format を csv にすると Enable Quoted Values と Use First Row as Header が表示されるのでそれぞれクリックして True に変更します。
※ Enable Quoted Values はcsvの値がクォートで囲まれている場合、Use First Row as Header はcsvの1行目をヘッダーとして利用する場合に True にする必要があります。

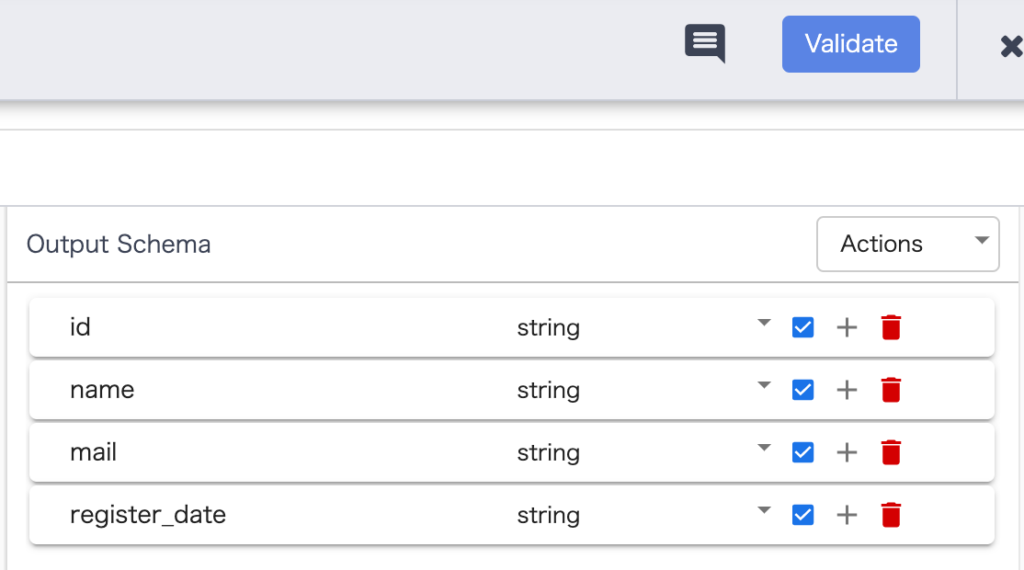
上の画面の GET SCHEMA ボタンをクリックすると画面右がCSVのヘッダー名に更新されるのですべての項目にチェックを入れます。
※ 右上の Validate ボタンをクリックすることで設定に問題がないかチェックすることができます。
右上の × でGCSのProperties画面を閉じ、Studioの画面に戻ります。
次は左ペインの Transform から Wrangler をクリックします。
Wrangler のノードが生成されますのでGCSノードの右端から矢印を引っ張り連結した上でWranglerノード内の properties をクリックします。
Wranglerではデータベースにデータとして取り込むためのデータ型変換を行います。
WranglerのProperties画面中央に Directives 項目があるので Recipe の入力欄に以下を入力します。
parse-as-datetime :register_date “yyyy-MM-dd HH:mm:ss.SSS”
※ Directives で実行可能なコマンドはCDAPで提供されています。
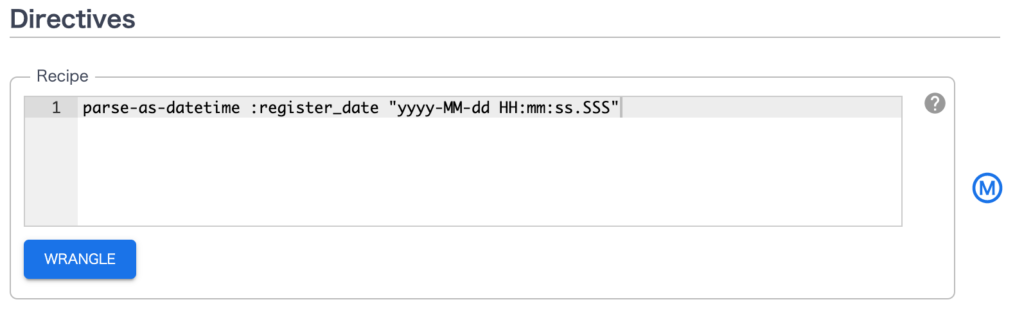
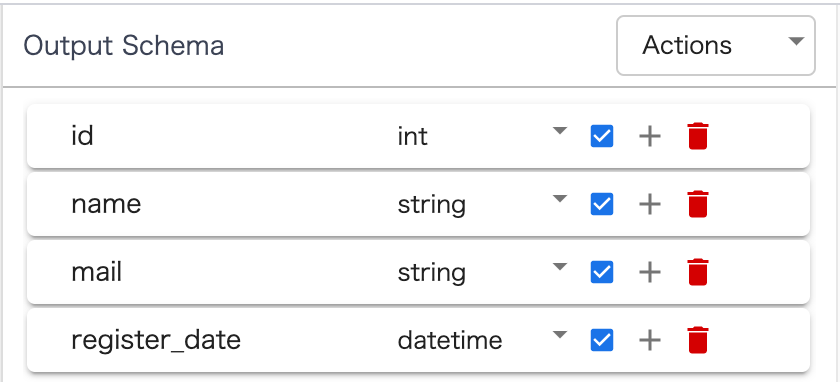
日付型についてはDirectivesでの明示的な型変換が必要になりますが、文字列型から整数型への変換については画面右の Outpu Schema のプルダウンでの変更のみで変換されます。
念のため、GCS Propertiesのときと同様に Validate ボタンで設定をチェックした上で × ボタンでProperties画面を閉じます。
最後に左ペインの Sink から BigQuery をクリックします。
BigQuery のノードが生成されますのでWranglerノードの右端から矢印を引っ張り連結した上でBigQueryノードの properties をクリックします。
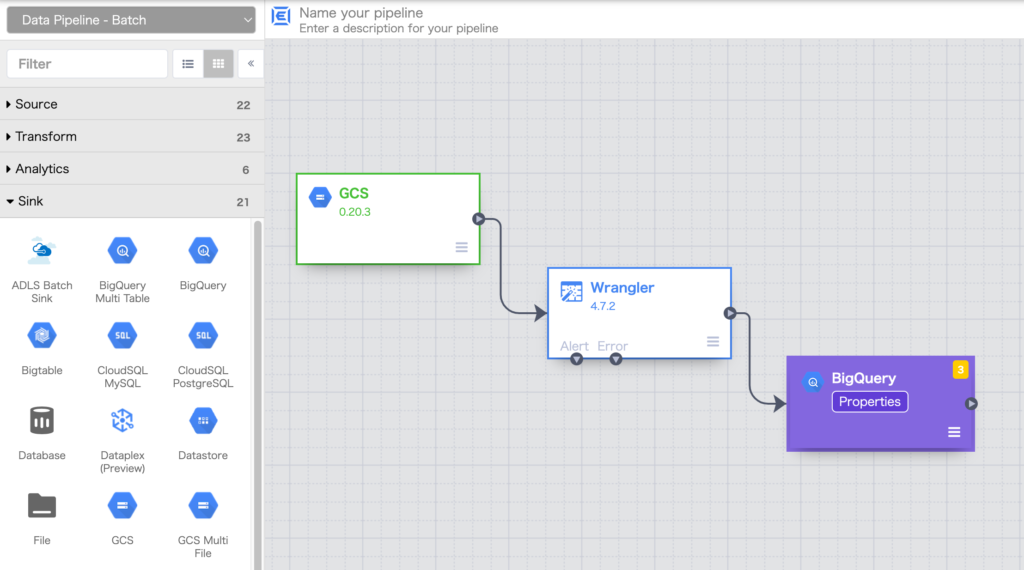
Use Connection をクリックして Yes に変更し、BROWSE CONNECTIONS ボタンをクリックします。

Name 列の BigQuery Default をクリックします。

BROWSE ボタンをクリックします。

表示されているBigQueryのデータセット一覧から対象のデータセットをクリックし、データを投入するテーブルを選択します。

※ 今回は事前にBigQuery上にテーブルを作成してあります。(テーブルの内容は以下)
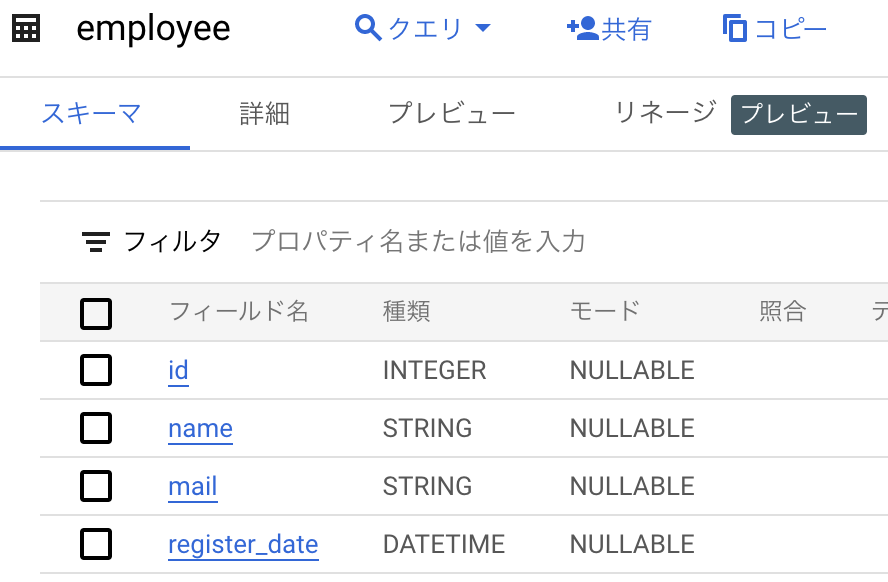
Operation で Insert を選択し、Truncate Tables を True にクリックして変更します。
※ 取り込み元のcsvの更新の仕方によっては、Truncate せず Update や Upsert の方が適している場合もあります。

画面最下部の Output Schema のすべてにチェックを入れます。

念のため、他のPropertiesのときと同様に Validate ボタンで設定をチェックした上で × ボタンでProperties画面を閉じます。
Studioの左上をクリックして入力欄を表示させ、上部にパイプライン名、下部にパイプラインの説明を記載し、Save ボタンをクリックします。
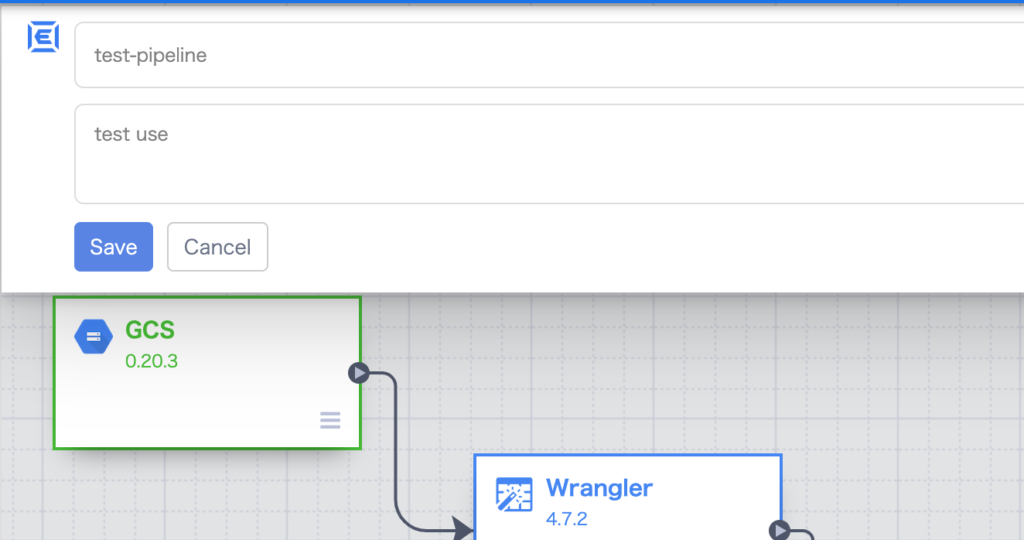
Studioの右上の Deploy をクリックします。(パイプラインとして保存されます)

画面上部の Run ボタンをクリックしてパイプライン処理を実行します。
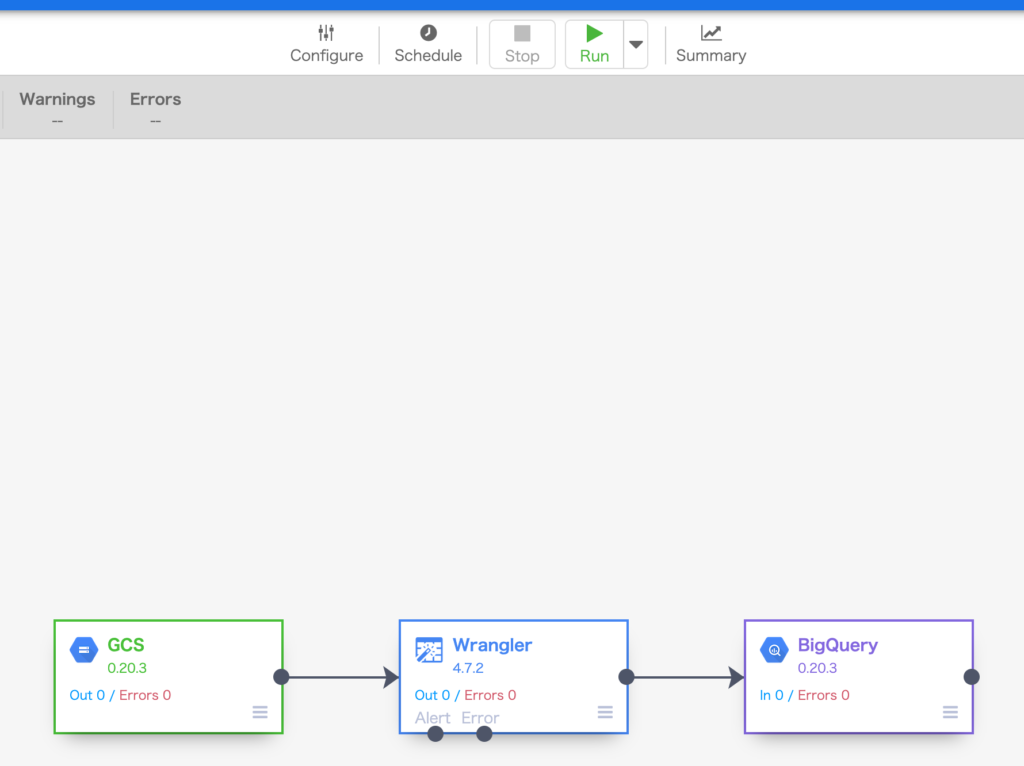
左上の Status が Succeeded になることを確認します。
※ Failed になる場合は Logs にてログを確認します。

以上でデータフローの処理は完了ですので結果としてBigQuery上にデータが投入されていることを確認します。
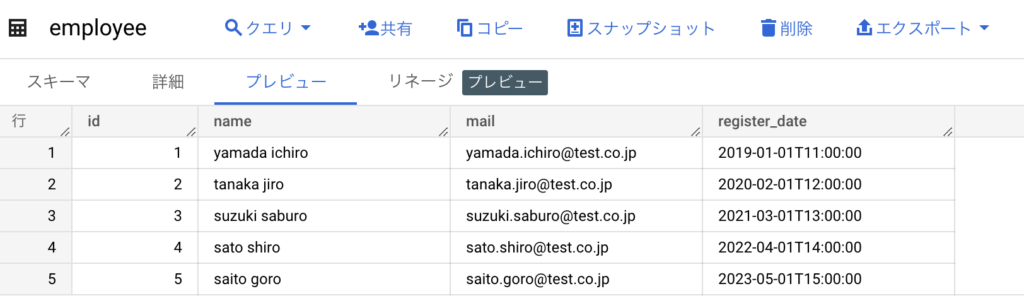
以上でETL処理用のパイプラインの作成は完了になります。
別途、Webアプリケーションを作成し、BigQueryからデータを参照できるような仕組みを作ることによって、ユーザーが必要な情報を参照できるようにすることも可能です。
補足:SQLを使用しないテーブル操作
各種データソースからデータを収集してデータベースに登録した後、そのデータを加工、集計したいといったケースもあると思いますので、その方法の一例について記載します。
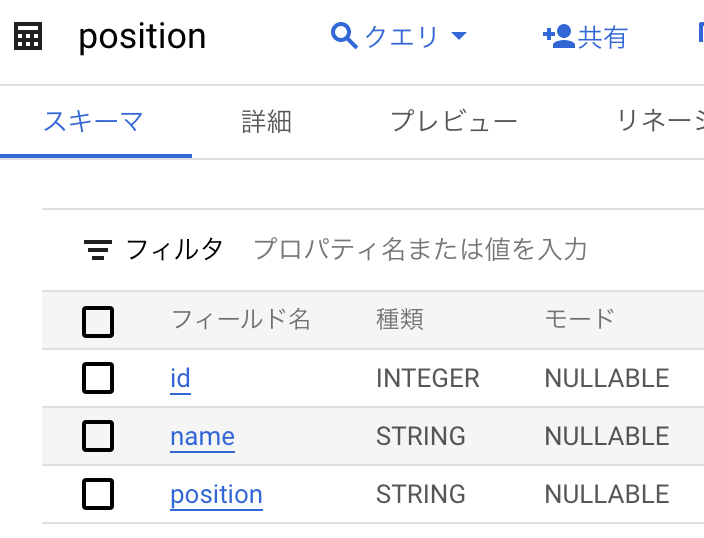
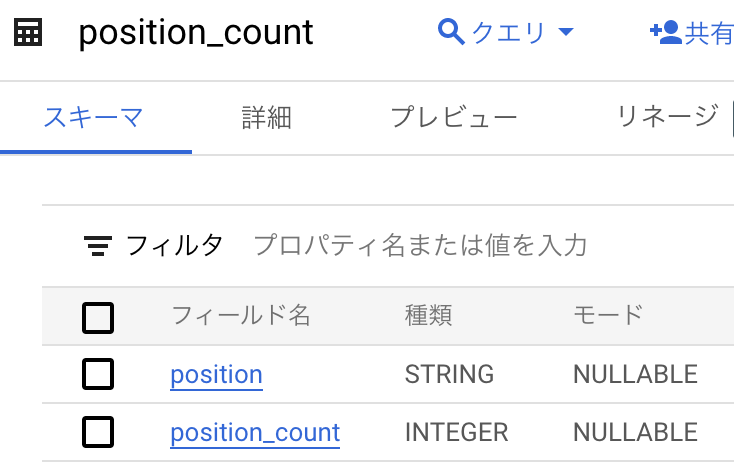
今回は以下のフローを作成し、これまでに作成した employee (社員)テーブルと position (役職)テーブルを結合、position_count (役職者数集計)テーブルに集計した結果を投入します。
- BigQueryの
employeeテーブルとpositionテーブルを読み込む。 - 読み込んだ2つのテーブルを結合する。
- 結合したテーブルの
potisionカラムの項目(役職)ごとの数をカウントする。 - カウントした結果をBigQueryの
position_countテーブルに取り込む。
※ 求める結果を出すのに2つ目の結合処理は特に必要ありませんが、結合処理の紹介のためにあえて追加してあります。
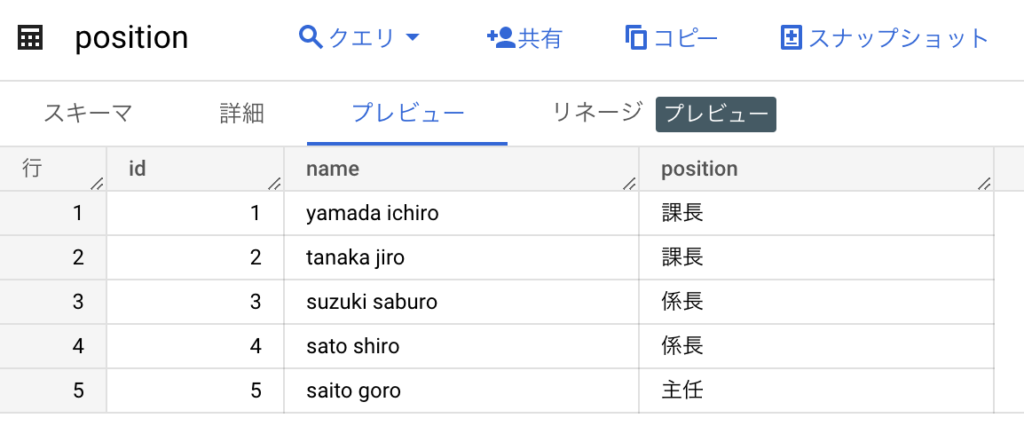
まず以下のテーブルを作成します。
position テーブルには実データも追加しておきます。
Data FusionのGUIの操作方法は記載してきましたので、ここでは完成したパイプラインをお見せします。
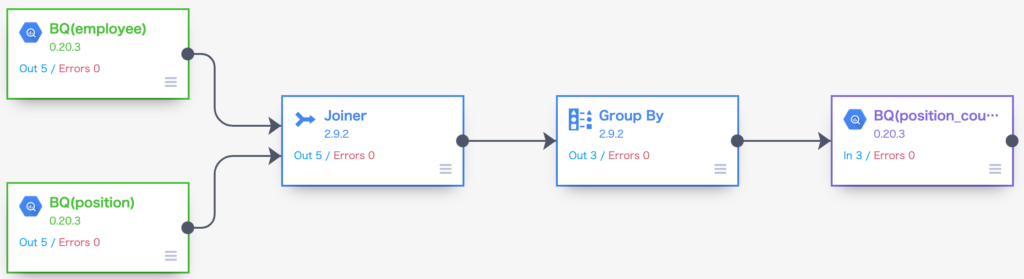
ここで登場している Joiner はSQLで言うところの内部結合(INNER JOIN)、外部結合(OUTER JOIN)の処理を行うパイプラインノードになります。Group Byはその名の通りSQLで言うところのグループ化(GROUP BY)の処理を行うパイプラインノードになります。
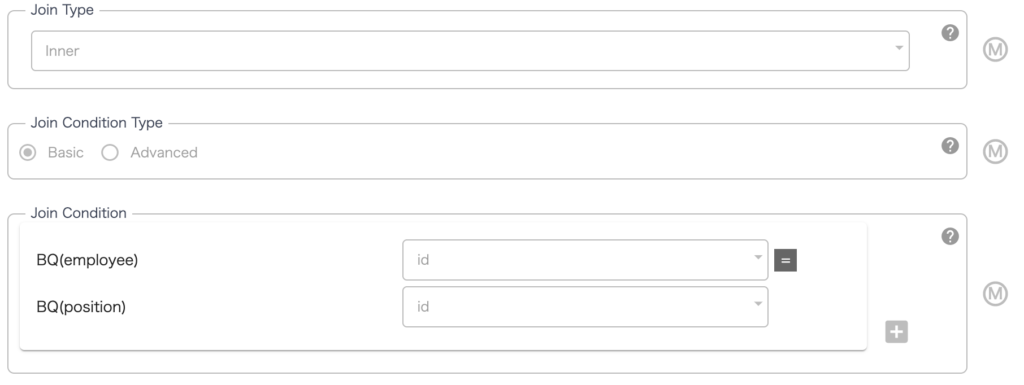
Joiner の設定ですが Join Type で inner を選択し、idのカラムを使用して結合(INNNER JOIN)するように設定しています。
カラムは employee テーブルから id name mail register_date のカラムを抽出、positionposition カラムを抽出して結合するように設定していますのでSQLで言うところの LEFT INNNOR JOIN の形式になります。
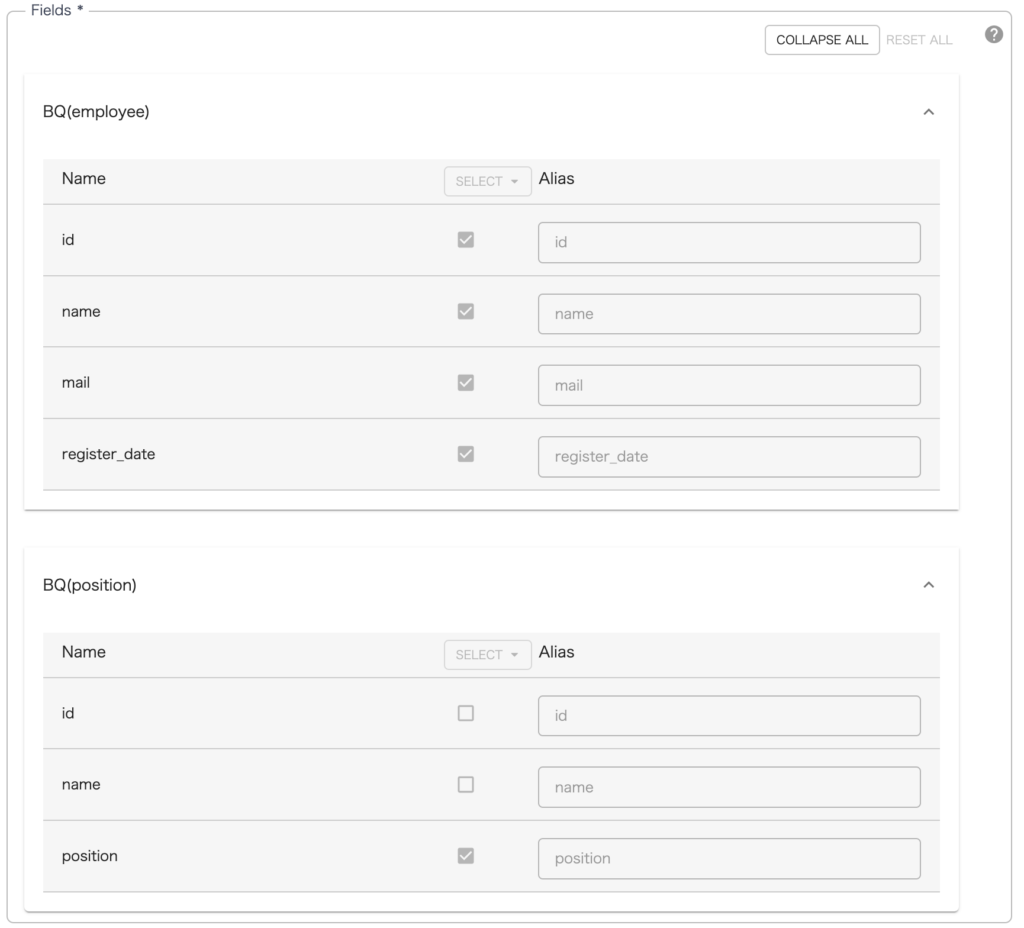
結合されたテーブルのカラムは右端の Output Schema に表示されます。
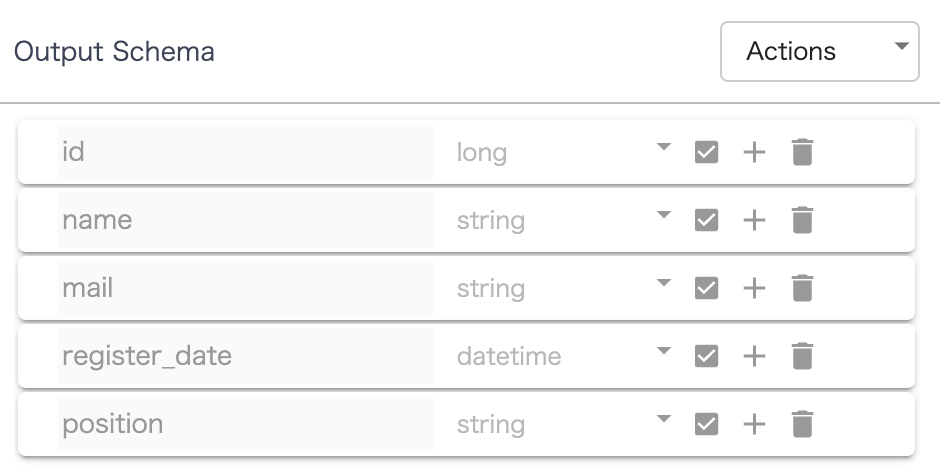
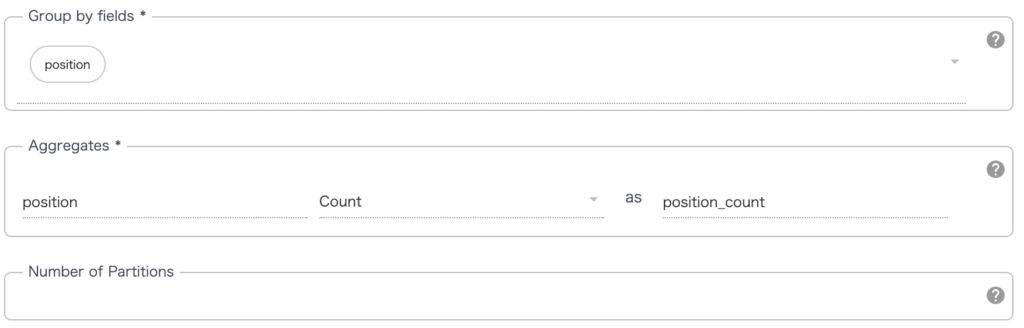
続いて Group By の設定ですが position のカラムで Group by しており、 Aggregates で position_count というカラム名を宣言して count(集計)を行なっています。
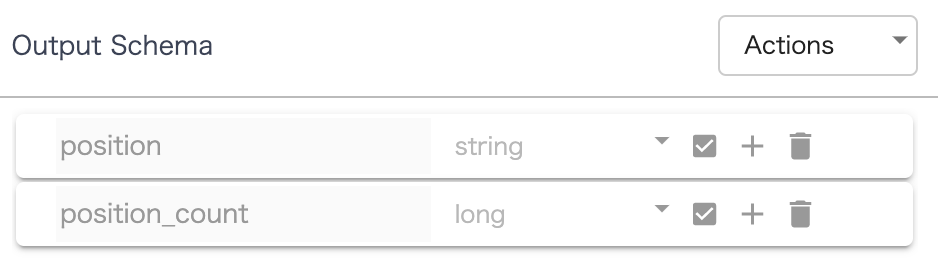
集計結果のカラムは右端の Output Schema に表示されます。
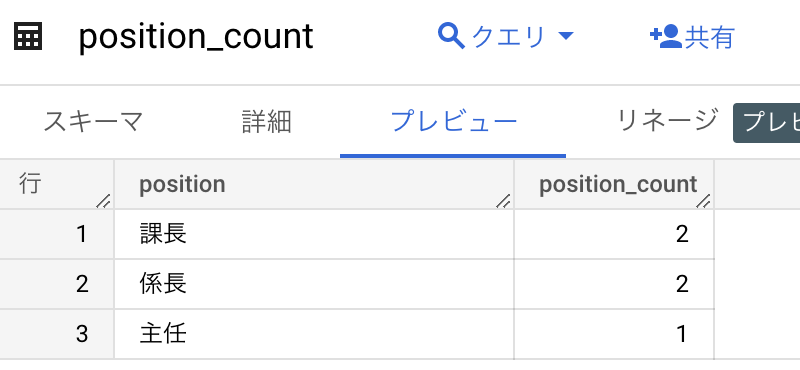
このパイプラインを実行した結果として position_count テーブルに集計結果が入ります。
以上がSQLを使用しないテーブルの操作方法になりますがいかがでしょうか?
SQLの考え方(結合、集計)自体は前提知識として必要かもしれませんが、SQL文自体を書く必要はありませんので、頭の中で構文が曖昧だったり、そもそもSQLが苦手だったりしても直感的にできてしまうと思います。



