

目次
Vertex AI のモデル評価シリーズへようこそ。
Part 1 では評価の基礎を整理しました。Part 2 では、実践に入る前の「準備」を固めていきます。
今回は、評価を成功させるための 3 つの柱を扱います。
- 評価データセットの構造化
- メトリクス(評価指標)の選定
- 詳細設定(Advanced Configuration)によるチューニング
EvalTask とは何か、なぜ使うのか
EvalTask は、Vertex AI におけるモデル評価を一元的に実行・管理するための仕組みです。
評価データセットの読み込み、メトリクスの実行、結果の記録までを同じフローで扱えるため、評価プロセスを標準化できます。
特に、複数モデルの比較や継続的な改善を行う現場では、「同じ条件で評価する」ことが非常に重要です。
EvalTask を使うことで、評価の再現性・透明性が高まり、リリース前の品質判断をより確実に行えるようになります。
このシリーズでは、EvalTask を使って、実務でそのまま使える評価設計と運用方法を段階的に整理していきます。
評価データセットを準備する
評価の品質は、データセット設計でほぼ決まります。
EvalTask は複数のデータソースを受け取れますが、デフォルトでは「列名」によって各列の意味を判断します。
EvalTaskクラスで使用できるデータセット列のデフォルト名
| デフォルト列名 | 役割・説明 | 利用する場面 |
|---|---|---|
| “prompt” | モデルへの入力(質問・指示) | すべての評価(Pointwise / Pairwise)で必須 |
| “response” | 評価対象モデル(candidate)が生成した回答 | BYOR(Bring-Your-Own-Response)評価で必須 |
| “reference” | 正解データ(ground truth / golden answer) | exact_match など、正解との比較が必要なメトリクスで使用 |
| “baseline_model_response” | 比較対象モデル(例: 旧モデル)の回答 | Pairwise BYOR 評価で必須 |
| “rubrics” | 行単位で独自評価基準を定義するための列 | 上級者向けのカスタム評価で使用 |
列名が変更された場合は、マッピングを行う必要があります。これについては、このセクションの後半で説明します。
EvalTask にデータセットを読み込む
EvalTask は柔軟で、複数の方法でデータを受け取れます。代表的な方法を見ていきましょう。
Option 1: pandas.DataFrame を使う(最も一般的)
Jupyter Notebook や Colab などで試しながら開発するとき、またデータがすでにメモリ上にあるときに、最も扱いやすい方法です。
利用シーン: 小〜中規模データ、またはスクリプト内でデータセットを組み立てる場合

Option 2: ファイルパス / URI(str)を使う
本番ワークフローでは最もスケーラブルな方法です。データを共通ストレージで管理できます。
2-A) ローカルの CSV / JSONL ファイル
利用シーン: 手元データで素早く検証したい場合
my_data.csv 例:

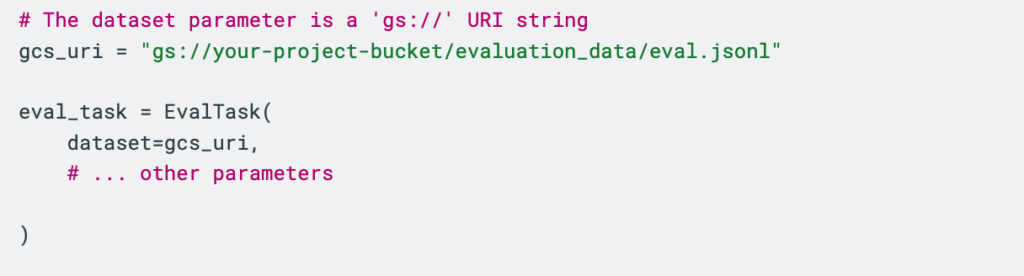
2-B) Google Cloud Storage(GCS)URI
利用シーン: クラウドネイティブ構成の標準。Vertex AI 実行環境から参照しやすい
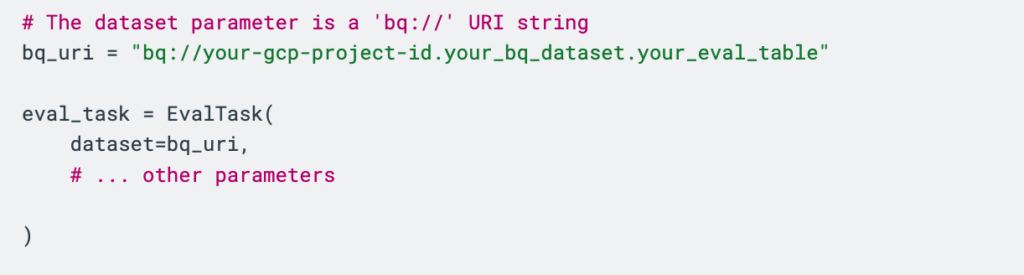
2-C) BigQuery テーブル URI
利用シーン: 大規模で構造化された評価データを BigQuery で管理している場合に最適
Option 3: dict を使う
利用シーン: ごく小規模なアドホック評価や、コード内での簡易テスト
(可読性の面では、通常 pandas.DataFrame のほうが扱いやすいです)

評価メトリクスを理解して使う
メトリクスは「何を基準に良し悪しを判定するか」を定義します。
EvalTask にはリストで渡します。

Pointwise と Pairwise の違い
| 区分 | 説明 | 代表メトリクス |
|---|---|---|
| Pointwise Metrics | 1 つの回答を単独で評価(品質・安全性・事実整合性など) | question_answering_quality, safety, exact_match, rouge_l_sum |
| Pairwise Metrics | 同じ prompt に対する 2 つの回答(candidate と baseline)を比較し、どちらが優れているか判定 | pairwise_question_answering_quality, pairwise_safety |
よく使う組み込みメトリクス
- question_answering_quality: 回答品質を総合評価(正確性・網羅性・関連性)
- safety: 有害コンテンツ(ヘイト、ハラスメント等)の観点で評価
- exact_match: 回答が reference と完全一致するかを判定
- rouge_l_sum: 回答と reference の類似度を測定(要約タスクでよく利用)
利用可能なメトリクス一覧は以下で確認できます。

EvalTask の詳細設定(Advanced Configuration)
データセットとメトリクス以外にも、評価運用を強化する重要パラメータがあります。
Vertex AI Experiments への記録(experiment)
評価結果を Vertex AI Experiments に集約でき、Cloud Console 上で実行結果の比較・追跡がしやすくなります。

列名マッピング(metric_column_mapping)
DataFrame の列名がデフォルト名と一致しない場合に必須です。
カスタム列名や Pairwise 評価で特に重要になります。

出力の GCS 保存(output_uri_prefix)
監査対応や本番運用では有効です。
詳細な評価結果やメトリクスを GCS に保存できます。

次回予告
これで、評価前に必要な準備は整いました。
データセット設計、メトリクス選定、そしてトラッキングやカスタム列対応まで、実運用に必要な土台をカバーできています。
Part 3 では、Pointwise Evaluation の実践編として、エンドツーエンドの具体例を通して実際の評価フローを動かしていきます。お楽しみに。
Vertex AI のモデル評価について他の記事も書いているので、よろしければこちらもご覧ください!
> 『Vertex AI モデル評価』シリーズ一覧



