

目次
BigQuery Omniを使う機会がありせっかくなので手順や所感をまとめてみました。
2022年2月8日時点の情報です。
つい最近のとある記事で「70年前の青森の写真」について取り上げられていましたが、誰の目にも触れられることのなかった写真がSNSで大きな反響があったらしくデータ活用と重ね合わせていろいろ思うところがありますね。
さて、この記事ではBigQuery Omniを使う機会がありせっかくなので手順や所感をまとめてみました。
2022年2月8日時点の情報です。
記事内容
- BigQuery Omniのメリット
- BigQuery Omniを使ってみる
- BigQuery Omniのデメリットと所感
BigQuery Omniのメリット
パブリッククラウドが登場して数年がたちました。複数のクラウドを運用することは珍しいことでは無くなってきました。 しかしこの背景でデータが散らばっているないしデータのサイロ化が発生しているんじゃないかと思います。
だからバッチ処理によるクラウド間でデータ連携(コピー)する流れが一般的にあると思いますが、 デメリットとしてデータの二重管理により追加のコストが発生します。 これを解消しようとするのがBigQuery Omniですね。
- クラウド間のデータ連携のコスト削減
- いつでも最新のデータでクエリ実行可能
- BigQueryの一本化でシステムをシンプル化
- BigQueryと連携している各サービスが利用できる
- Looker
- BigQuery GIS
- BigQuery ML
- Google Analytics 360
BigQuery Omniを使ってみる
データを用意する
- S3バケットを用意
- データを設置
※ 現在利用できるリージョンは「米国東部 (バージニア北部) us-east-1」のみです
随時利用できるリージョンが増えるというので今後に期待ですね
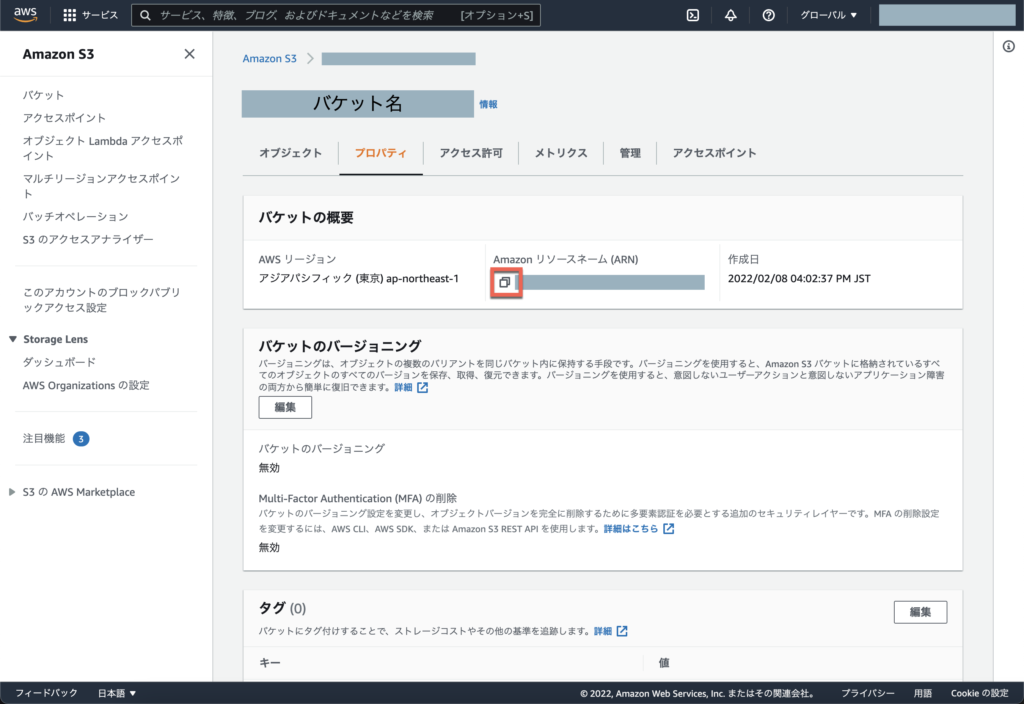
※ 用意したバケットのARNを控えておいてください。後述の「AWS IAMポリシーを作成」で利用します。
※ 用意するデータのネタが無ければ、こちら[1]を利用してみてください
こちら[1]のデータを利用する際は諸事情でStack Overflowに記載されているコマンドの実行が必要です
- [1] https://docs.aws.amazon.com/redshift/latest/dg/c-getting-started-using-spectrum-create-external-table.html
- [2] https://stackoverflow.com/questions/68824370/amazon-s3-cp-fails-with-accessdenied-when-calling-the-getobjecttagging-operati
※ 現状のBigQuery OmniではS3を作成元とするテーブルでS3バケットの直下でワイルドカードを使うことはできず、代わりに s3://mybucket/myfolder/という表現で指定可能です
1つだけのオブジェクトであればS3バケットの直下に展開しても良いですが、複数ファイルが存在する場合はprefix(ディレクトリ)が必要です(s3://mybucket/myfolder/)
AWSのIAMでアクセス権限を設定する
- AWS IAMポリシーを作成
- AWS IAMロールを作成
※ BigQueryでクエリを実行するために必要なアクセス権は以下の通りです
- AWS IAMポリシー「s3:ListBucket」
- 上に紐付けるS3のARN
- AWS IAMポリシー「s3:GetObject」
- 上に紐付けるS3のARNとオブジェクトパスは全て(*)
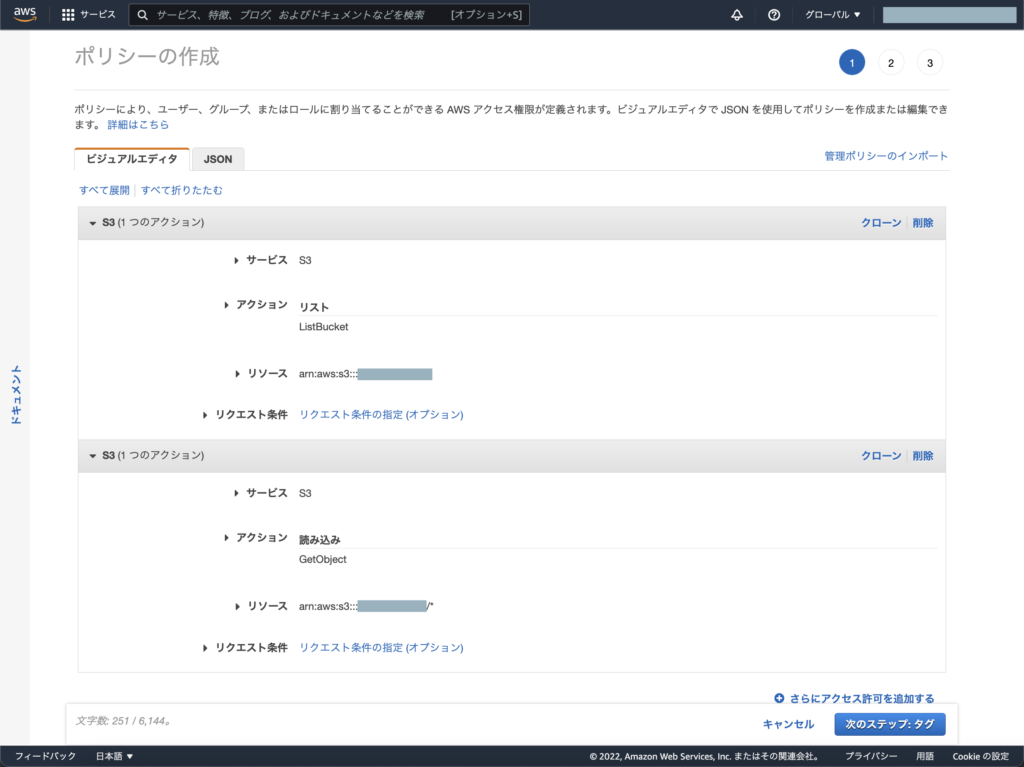
※ AWS IAMロールを作成する際に指定するパラメータの補足
- 信頼されたエンティティタイプ「ウェブアイデンティティ」
- アイデンティティプロバイダー「Google」
- Audience「00000」 ← 後述の「BigQueryの接続設定」の後に正しい値に書き換えます
- 許可ポリシーには前述で作成したAWS IAMポリシーを指定
※ 用意したAWS IAMロールを開いて開いて最大セッション時間は「12時間」になるように編集してください
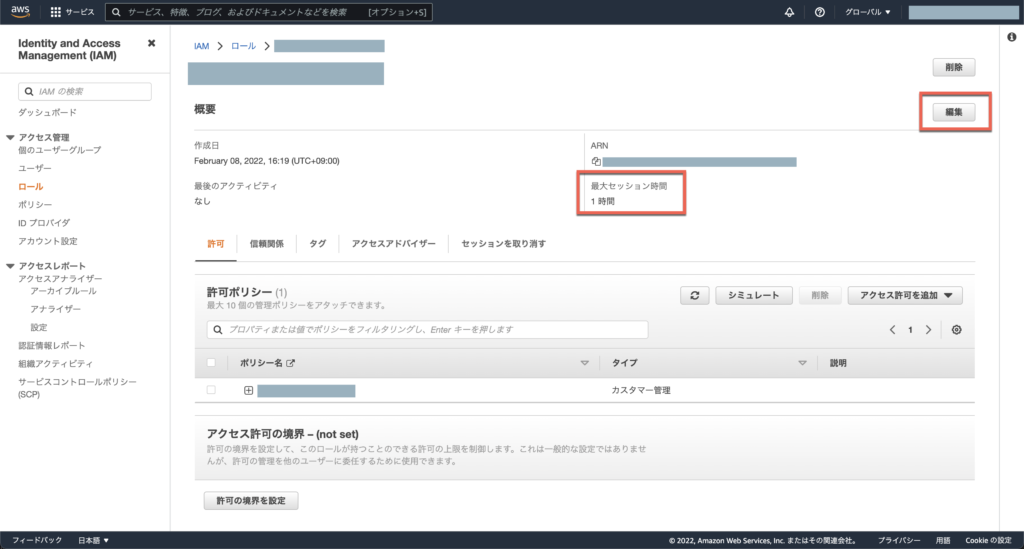
※ 用意したAWS IAMロールのARNを控えておいてください。後述の「BigQueryの接続設定」で利用します。
BigQueryを接続する
- BigQueryの接続設定
- AWS IAMロールを修正
※ BigQueryの接続設定はこちらから
※ 外部データソースの作成で指定するパラメータの補足
- 接続タイプ「AWS(BigQuery Omni 経由)」
- 接続ロケーション「aws-us-east-1」
- AWS ロール IDは前述で用意したAWS IAMロールのARNを入力
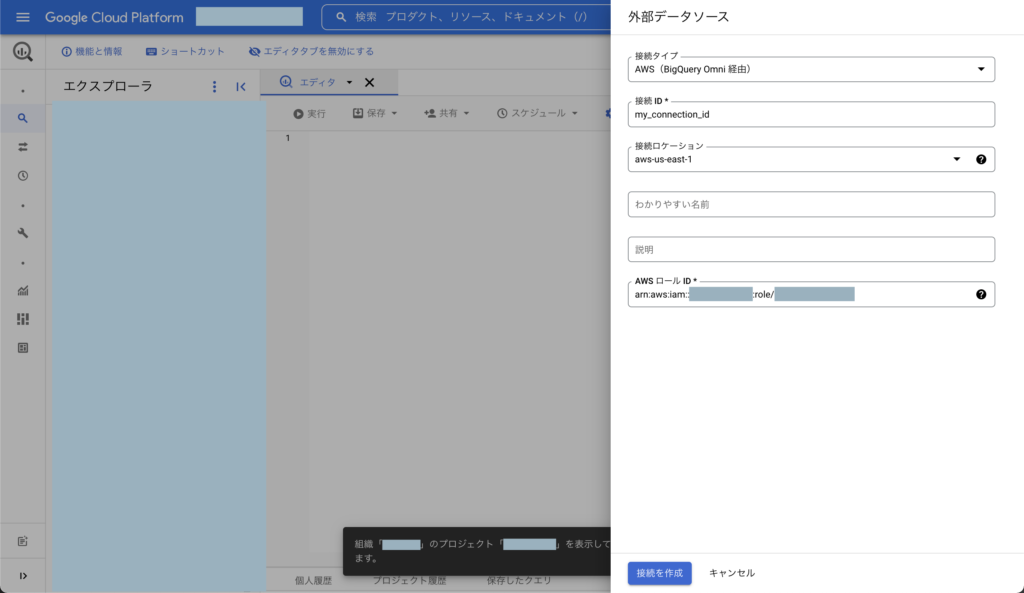
※ 新しく作成した外部データソース(外部接続)を開くとBigQuery Google IDが表示されるので控えてください
前述で用意したAWS IAMロールの信頼関係タブを開いてaccounts.google.com:audに控えたBigQuery Google IDに書き換えてください
データセットを作成する
- データセット用意
- テーブル用意
※ データセットの作成で指定するパラメータの補足
- データのロケーション「aws-us-east-1」
※ テーブルの作成で指定するパラメータの補足
- テーブルの作成元「Amazon S3」
- S3 パスを選択「s3://bucket-name/directory-name/*」
- ファイル形式「CSV」
- 用意するデータのネタが無ければ、こちら[1]…を利用していればCSVです
- その他の場合は適切なファイル形式を選択する必要があります
※ スキーマは自動検出、または手動で定義できます
用意するデータのネタが無ければ、こちら[1]…を利用していれば[1]のページ下部にスキーマ情報が掲載されています
クエリを実行する
- BigQueryスロット コミットメントを購入
- GCPプロジェクトを予約割り当て
- クエリを実行
※ BigQueryには「オンデマンド」と「定額」 2種類の料金モデルがありますが、BigQuery Omniは定額で利用できます そのためにBigQueryスロット コミットメントを購入する必要があります こちらから購入可能です
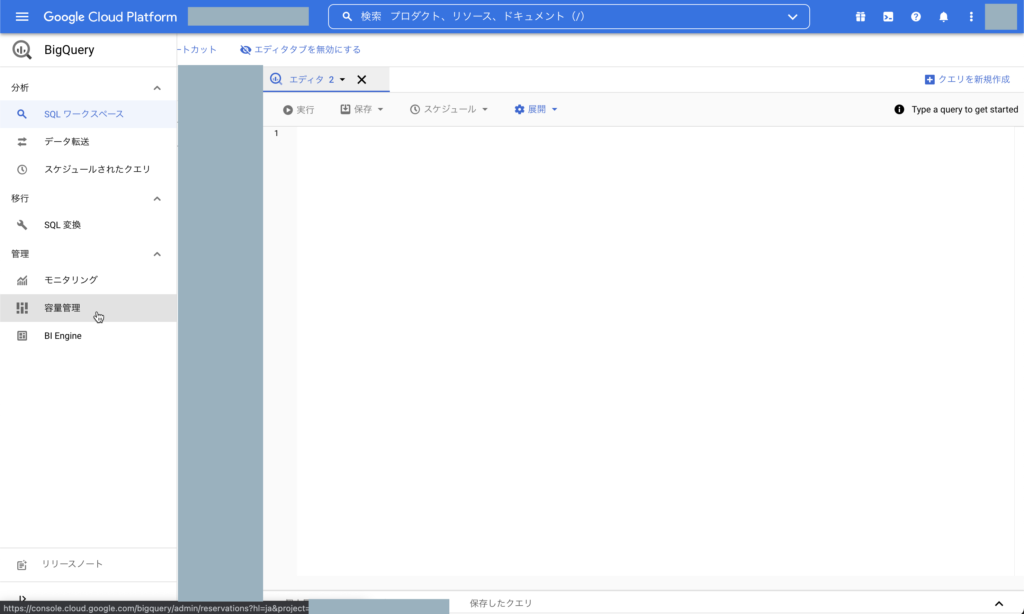
※ スロットの購入で指定するパラメータの補足
こちらのパラメータでは1時間あたり$5で利用し放題です
- コミット期間「Flex」
- ロケーション「Amazon US East (N. Virginia)」
- スロット数「100」
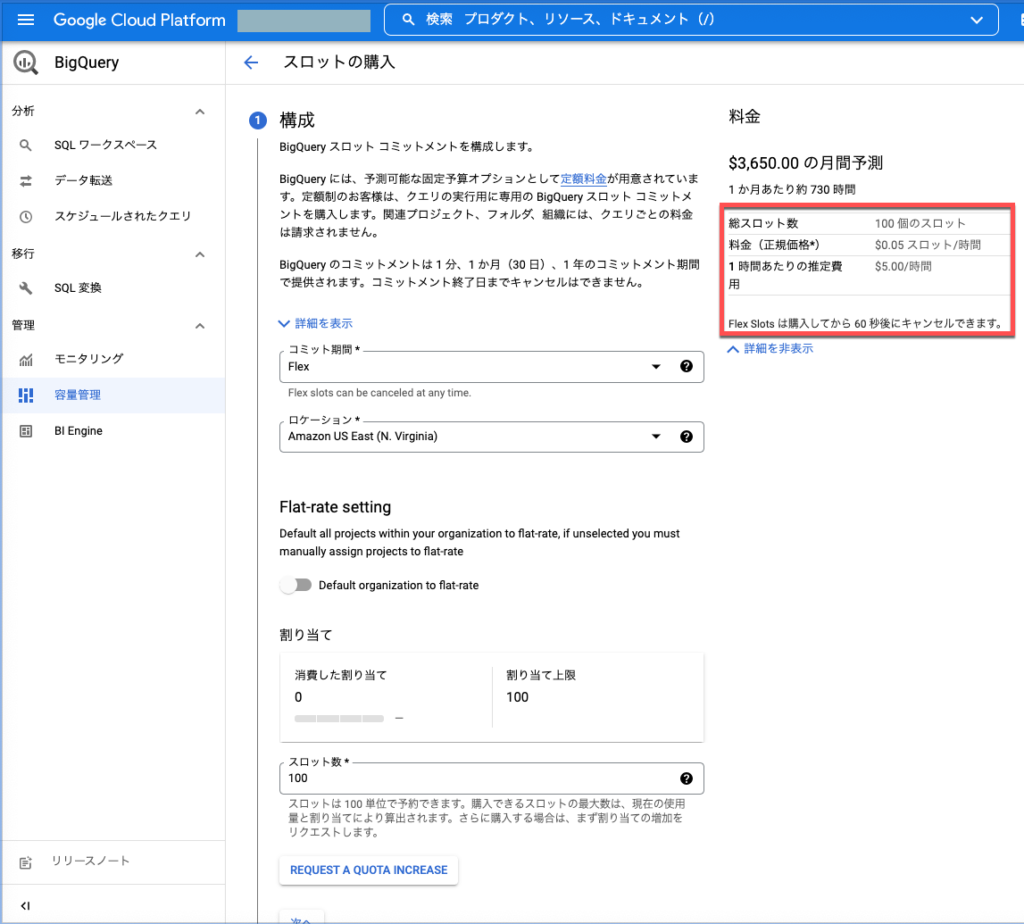
※ スロット購入後はGCPプロジェクトを予約割り当てする必要があります
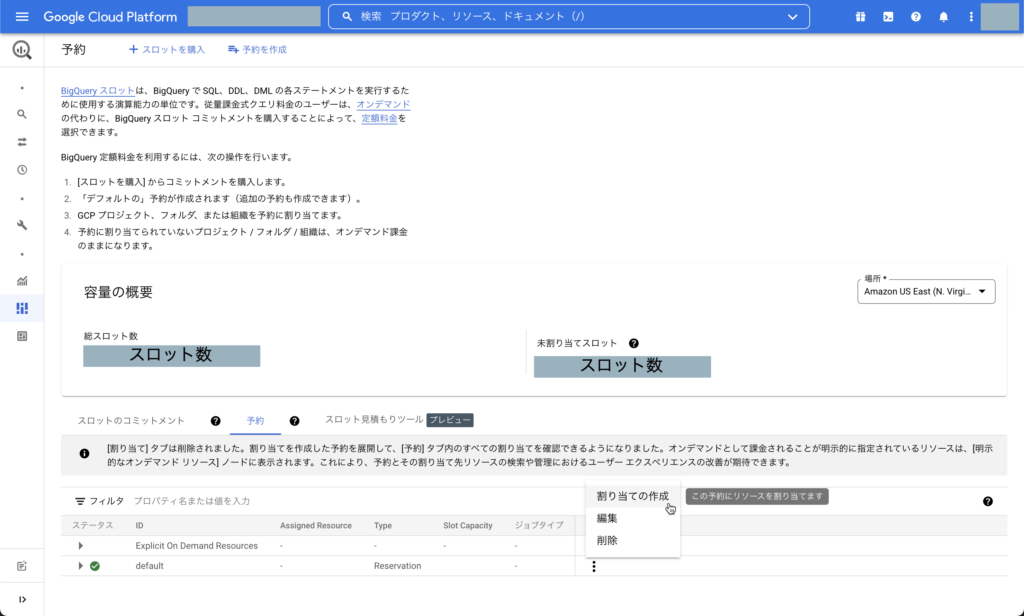
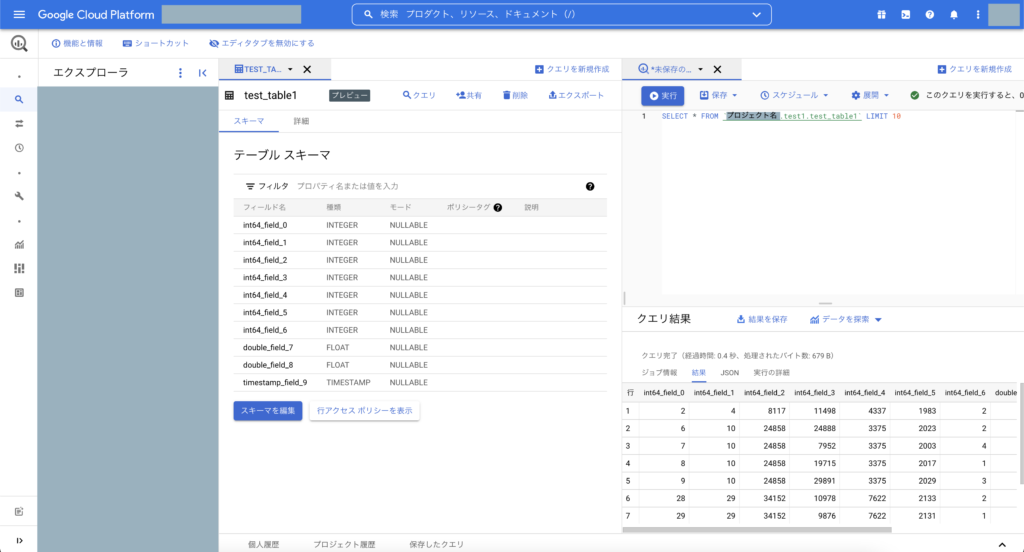
※ クエリ実行の結果イメージ
スキーマを自動検出と設定しましたが、実際に活用する際はきちんと手動でスキーマ定義したほうが良いですね
後処理
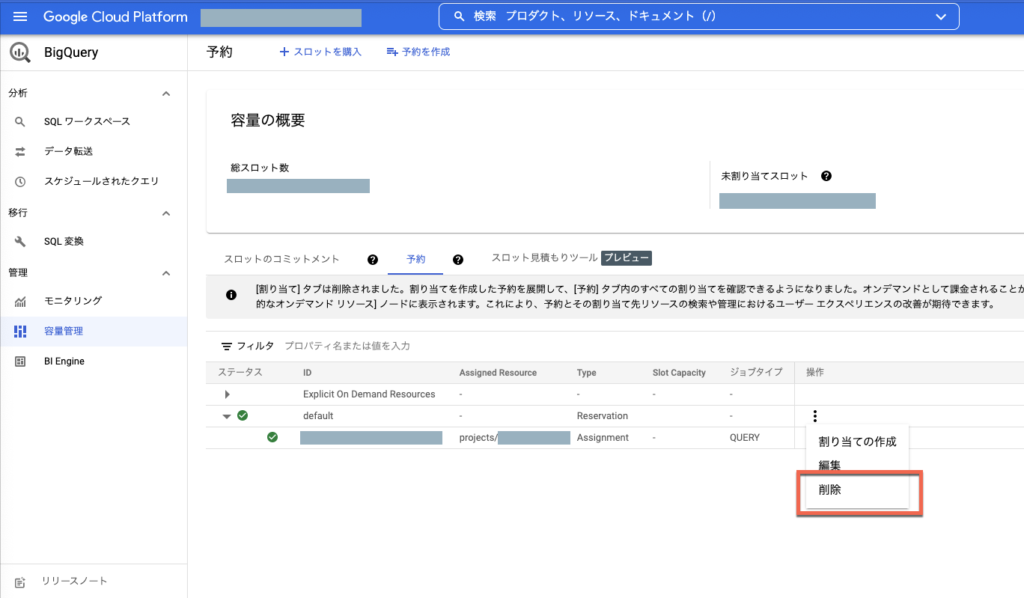
- 予約割り当ての削除
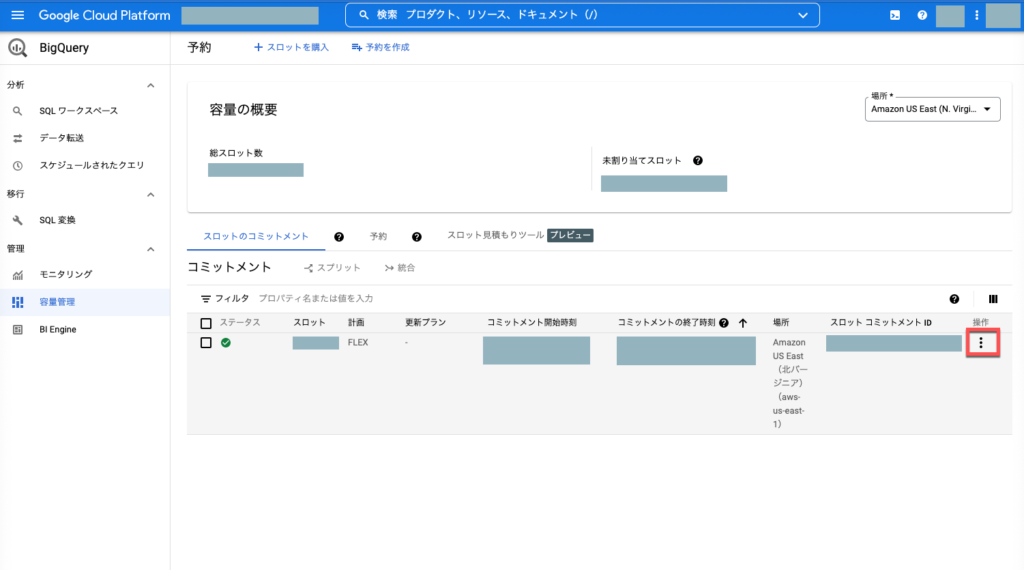
- スロット コミットメントの削除 あとでスクショ
場所は「Amazon US East (N. Virginia)」
※ 予約割当の削除はこちら
※ スロット コミットメントの削除
BigQuery Omniのデメリットと所感
唯一目立つデメリットはスロットを購入しないとBigQuery Omniでクエリを実行できないことですね
スロットを購入する意思決定を出来る人が身近にいないと活用しづらい組織的な問題が発生する可能性があります
現状(2022年2月8日時点)利用できるリージョンは米国東部(バージニア北部、us-east-1)のみでしたので、今すぐBigQuery Omniを活用するには国外へのデータ移動を認める必要があります
兎にも角にもデータの送受信を実装して分析をするというコストを削減できそうなので喜んで受け入れたいプロダクトだと思いました
※ やっぱりS3 bucketのリージョンでap-northeast-1(東京)は使えませんでした。リージョンを統一する必要があるので、今後BigQuery Omniに対応するリージョンが増えていくことできっと東京が出現するはずなので待つか、先の展開を見据えて利用するのが良さそうです
※ 各項目でも触れていますが、S3 bucketの直下(prefix無し)のオブジェクトではBigQuery Omniで利用するテーブルを作成することができません
テーブル作成時のS3パス指定の例ではうまく動作せず、Google Cloud (GCP)のサポートに問い合わせをして確認した結果前述のとおりです

株式会社grasys(グラシス)は、技術が好きで一緒に夢中になれる仲間を募集しています。
grasysは、大規模・高負荷・高集積・高密度なシステムを多く扱っているITインフラの会社です。Google Cloud (GCP)、Amazon Web Services (AWS)、Microsoft Azureの最先端技術を活用してクラウドインフラやデータ分析基盤など、ITシステムの重要な基盤を設計・構築し、改善を続けながら運用しています。
お客様の課題解決をしながら技術を広げたい方、攻めのインフラ技術を習得したい方、とことん技術を追求したい方にとって素晴らしい環境が、grasysにはあります。
お気軽にご連絡ください。



