

目次
こんにちは、Yama です。
ChatGPT の登場から AI が民衆化して、業務の中でも広く使われるようになってきました。
AI サービスも日々進化し、ますますその性能は高くなっていますね。
本日は、文書検索の精度をさらに高める Google Cloud が提供する AI ソリューション「Vertex AI Search」の検索チューニング機能についてご紹介します。
Vertex AI Search とは
Vertex AI Search は、Google Cloud のソリューションで、Web サイト、組織内のドキュメント、BigQuery データなどに基づいて、高度な検索システムを簡単に構築できるサービスです。
このサービスは、業務やビジネスの特定のニーズに合わせた情報検索を効率化するために設計されています。主な特徴はこちらとなります。
- Google のテクノロジーを活用した高性能検索
- Google の数十年の専門知識とセマンティック検索技術を基に構築
- 構造化データと非構造化データの両方に対応
- 高度な関連性のある検索結果を提供
- 生成 AI アプリケーションを支援
- RAG(Retrieval-Augmented Generation、検索拡張生成)システムとして機能
- エンタープライズ向け設計
- シームレスなスケーラビリティ
- 堅牢なプライバシー管理とガバナンス機能
- 簡単な導入とカスタマイズ性
- 数分で利用開始可能
- 検索ウィジェットの追加で、即座にウェブサイトの検索機能を向上
- 柔軟なカスタマイズ機能により、特定のニーズに対応
参考:https://cloud.google.com/enterprise-search?hl=ja
Vertex AI Search の「検索チューニング機能」とは
検索モデルをユーザー特有のデータやニーズに基づいて最適化することで、基本的な検索モデルよりも高品質で精度の高い検索結果を提供する機能です。
この機能は、特に業界固有や企業固有のクエリに対応するために設計されており、以下の特徴を備えています。
- ドメイン特化型対応
一般的な大規模言語モデル(LLM)では対応が難しい、専門性の高いクエリにも対応可能です。少なくとも 10,000 件のスニペットを準備することで、モデルの精度を高める設計となっており、クエリとスニペットのペアごとに関連度スコア(0 または 1、あるいは詳細なスコアリングで0 ~ 10)を設定することで、モデルの調整を効率化します。
- 高精度な結果生成
エンドユーザーのクエリに最適化されたデータをトレーニングすることで、より的確な検索結果を提供します。ユーザーが尋ねると想定されるクエリと、それに対応するスニペット(250 ~ 500 語)のペアを用いてモデルを調整します。ランダムな否定例(negative examples)を追加して、モデルのバランスを最適化します。
検索結果の最適化手法
検索チューニング機能は、モデルを最適化するために以下の手法で行います。
1. トレーニング データの準備
まずはコーパス ファイル、クエリファイル、トレーニング ラベルファイルを用意します。
■ コーパス ファイルについて
▼ 含まれる内容
- クエリに関連する情報を含む抽出セグメント
クエリに回答するセグメントは 100 個以上必要です。クエリへの回答は複数の抽出セグメントを組み合わせることもあります。
※「セグメント」とは、ドキュメントを分割した文章のことです。
- クエリに関連しない情報を含む抽出セグメント(ネガティブ セグメント)
クエリに対して関連性がない、もしくは不適切な情報を含む文章のことを指します。
モデルに「関連する情報」と「関連しない情報」を区別させて、学習の精度を向上させます。ネガティブ セグメントは 10,000 個以上必要です。
▼ セグメントの作成ルール
- データストア内のドキュメントが 500 語未満の場合は、そのドキュメント全体をセグメントとして使用します。
- ドキュメントが 500 語以上の場合は、その中からランダムに 250 ~ 500 語のセグメントをプログラムで抽出し、コーパスファイルに追加します。
- ファイル形式は JSONL(JSON Lines)です。
- 各行には以下の 2 つのフィールドを含む必要があります:
- _id: セグメントを識別するための文字列
- text: セグメントのテキスト内容
▼ コーパス ファイル例
{"_id": "doc1", "text": "2. 本規定の改訂は、経営会議にて決定されるものとする。就業規則:エンプロイメント・アーキテクチャについて\n第1章 総則\n1. 本規則は、当社のコアエンゲージメントフレームを基盤とし、エコシステム的な業務プロト\nコルを確立することを目的とする。これにより、社員一人ひとりのスキルや資源を最大限\nに活用し、組織全体の生産性向上と持続可能な成長を目指す。○ 背景: 現代のビジネス環境では、従来のトップダウン型アプローチではなく、ネット\nワーク型の相互作用が求められる。この規則は、当社が柔軟かつ効率的に対応\nできるよう設計されている。2. 全社員は、クロスハイアラキー・オペレーションの精神を尊重し、エンプロイメント・アーキ\nテクチャの維持・発展に寄与すること。この精神は、部門や役職の壁を越えた協力を可能\nにし、組織全体のシナジーを最大化するための基盤となる。第2章 労働時間とフレキシビリティ\n1. アダプティブ・タイムフロー\n○ 労働時間は基本的にコアタイムベースのフレックスモジュールを採用する。"}
{"_id": "doc2", "text": "■ フォローアップ: 研修終了後 1か月以内にフォローアップ面談を実施。2. スキルアッププログラム\n○ 専門性向上のためのワークショップやセミナーを定期開催。■ ディープ・ダイブ型セッション: ケーススタディ分析、最新技術のトレーニン\nグ。■ 成果測定: 参加者はトレーニング後に短期的なプロジェクトで学んだ内容\nを実践。第5章 評価と報酬\n1. インセンティブ制度\n○ 種類: 金銭的報酬、表彰、昇進機会。○ 基準: イノベーションの成果、チーム貢献度。"}
:
{"_id": "doc9998", "text": "2. デバイスロケーションと追跡\n○ 貸与デバイスには、位置追跡機能を有効化し、紛失時の迅速な対応を可能にす\nる。■ 紛失時の手続き: 紛失が判明した場合、直ちにIT部門に報告し、リモート\nでのデータ消去を依頼する。3. 不正アクセスの防止\n○ 全てのデバイスに二要素認証を設定し、不正なアクセスを防止する。■ 例: スマートフォン連携による認証コードの使用。第5章 メンテナンスとサポート\n1. 定期メンテナンス\n○ IT部門は、貸与デバイスの定期的なメンテナンスを実施。■ 内容: ハードウェアの状態確認、不要ファイルの削除、セキュリティソフト\nの更新。"}
{"_id": "doc9999", "text": "2. 影響範囲の特定と封じ込め。3. 原因の調査と再発防止策の策定。4. 被害報告書の作成と関係部署への共有。○ 報告義務: 全社員はインシデントを即時にCISO(最高情報セキュリティ責任者)\nへ報告。○ 演習: 毎年一度、実際のインシデントを想定した演習を実施。2. プロアクティブ・サイバーリスクモニタリング (PCRM)\n○ 潜在的な脅威を事前に検知するための監視システムを導入。○ 技術仕様: AIを活用した脅威インテリジェンスと24/7リアルタイムモニタリング。○ アウトプット: 定期的な脅威レポートを経営陣に提供し、組織全体の防御力を向\n上。"}
{"_id": "doc10000", "text": "■ 保持期間の基準: 法規制や業務上の必要性に基づき設定。■ 削除プロセス: データ削除時には、復元不可能な形式で処理を行う。第4章 データ共有と第三者提供\n1. データシェアリング・プロトコル (DSP)\n○ 個人情報を第三者に提供する場合、以下の基準を遵守する。■ 基準1: 提供先が十分なセキュリティ対策を講じていることを確認。■ 基準2: 提供目的を明確にし、必要最小限のデータに限定する。■ 基準3: 提供前にデータ提供契約 (DPA) を締結。2. アクセスログモニタリング (ALM)\n○ データ共有時のアクセスログを記録し、不正利用の兆候をリアルタイムで監視。"}■ クエリファイル
エンドユーザーが尋ねると予想されるクエリを作成します。少なくとも 100 件の正の一致クエリを用意し、業界固有や企業の専門用語を含むものを重点的に設定します。関連性のないクエリを指定することもできます。クエリファイルは JSONL 形式となります。
▼ クエリファイル例
{"_id": "query1", "text": "この規則に基づくフレックスタイム制度の具体的な運用方法や、社員の労働時間に関する柔軟性について教えていただけますか?"}
{"_id": "query2", "text": "研修プログラムの効果を測定するために、どのような具体的な成果指標を設定していますか?"}
{"_id": "query3", "text": "「リラクゼーション・アグリゲートモデルにおける休暇取得率の具体的な改善プランはどのようなものですか?」"}
:
{"_id": "query36", "text": "「インテンシティ・スケールとホリスティック・リカバリーシステムの導入によって、具体的にどのように社員の業務負荷やストレスを軽減することが期待されますか?」"}
:
{"_id": "query110", "text": "このコンプライアンス研修には、どのようなチョコレートが提供されますか?"}
{"_id": "query111", "text": "最近の天気予報では、どの地域で雪が降る可能性が高いですか?"}
{"_id": "query112", "text": "「最近の天気はどうですか?」"}
■ トレーニング ラベルファイル
クエリと抽出セグメントを紐付け、それぞれのペアにスコアを割り当てます。
▼ カラム
- クエリの ID(query-id: クエリファイル内の _id と一致する文字列)
- 対応する抽出セグメントの ID(corpus-id: コーパスファイル内の _id と一致する文字列)
- スコア(正の整数値、デフォルトは 1 です。スコアが 0 より大きい場合、クエリに関連があることを示します。スコアが高いほど関連性が高いと判断されます)
▼ トレーニング ラベルの登録要件
クエリごとに最低 1 行必要です。クエリが複数のセグメントで回答される場合、それぞれのペアに対応する行を追加します。
▼ テストデータについて
テスト ラベルファイルがない場合、トレーニング ラベルファイルのクエリの 20 % を評価用に予約されますので、テスト ラベルファイルの用意は任意となります。テスト ラベルファイルの形式はトレーニング ラベルファイルと同様です。
トレーニング ラベルファイルには、少なくとも 100 個の一意のクエリ ID を含める必要があります。トレーニング ラベルファイルのクエリ ID の数とテスト ラベルファイルのクエリの数を合計した数は 500,000 未満にする必要があります。
▼ トレーニング ラベルファイル例
query-id corpus-id score
query1 doc1 1
:
query3 doc9 1
query4 doc4 0
:
query110 doc110 0
query111 doc201 0
query112 doc202 0
: ▼ ファイル形式
形式: ヘッダー付き TSV(タブ区切り値)ファイル
2. 検索モデルのチューニング
- トレーニング データを Google Cloud Storage にアップロード後、Vertex AI のチューニング機能を用いて調整します。
- 必要に応じて、テストクエリを使用して結果を確認します。
3. 制限事項
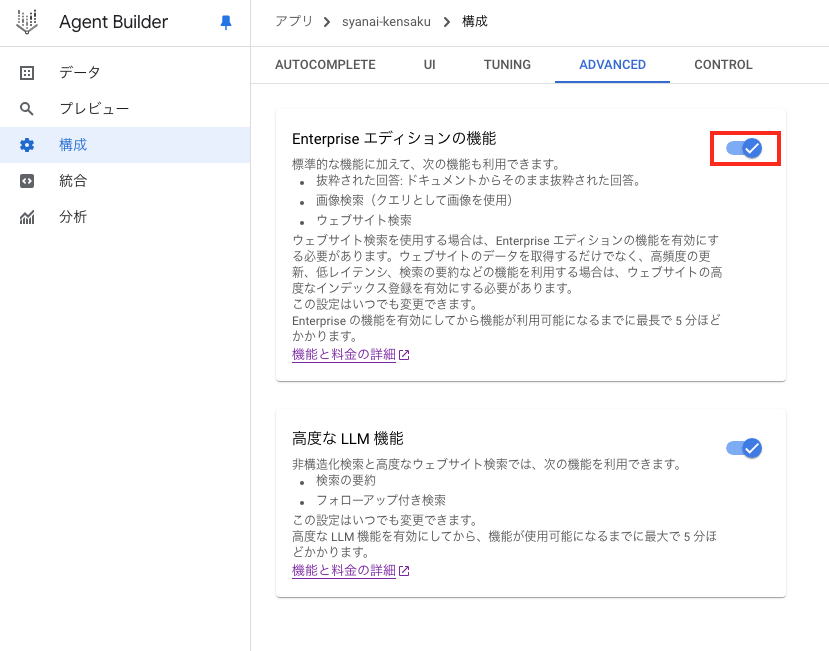
- 検索チューニング機能を使用するには Enterprise の機能を ON にする必要があります。ただし、ON にすると料金も上がるので注意してください。
- 検索チューニングは、非構造化データストアに限定されています。
- 十分なトレーニング データを用意する必要があります(最低 10,000 スニペット)
参考:https://cloud.google.com/generative-ai-app-builder/docs/tune-search?hl=ja
https://cloud.google.com/generative-ai-app-builder/pricing?hl=ja#enterprise_pricing
具体的なチューニング方法と実装例
今回は、ナレッジベースの検索のチューニングを例にとって解説していきます。
検索対象は就業規則やセキュリティ規則などが書いてある社内規定ドキュメントです。
今回は違いがわかりやすいように、用意した社内規定には以下のように難しい言葉や業界特有の用語を多く含ませました。


Step 0
まずはコーパス ファイル、クエリファイル、トレーニング ラベルファイルを「1. トレーニング データの準備」で紹介した形式で用意します。
Step 1
Cloud Storage の任意のバケットに非構造化データの検索対象としたいドキュメント、コーパス ファイル、クエリファイル、トレーニング ラベルファイルを格納します。
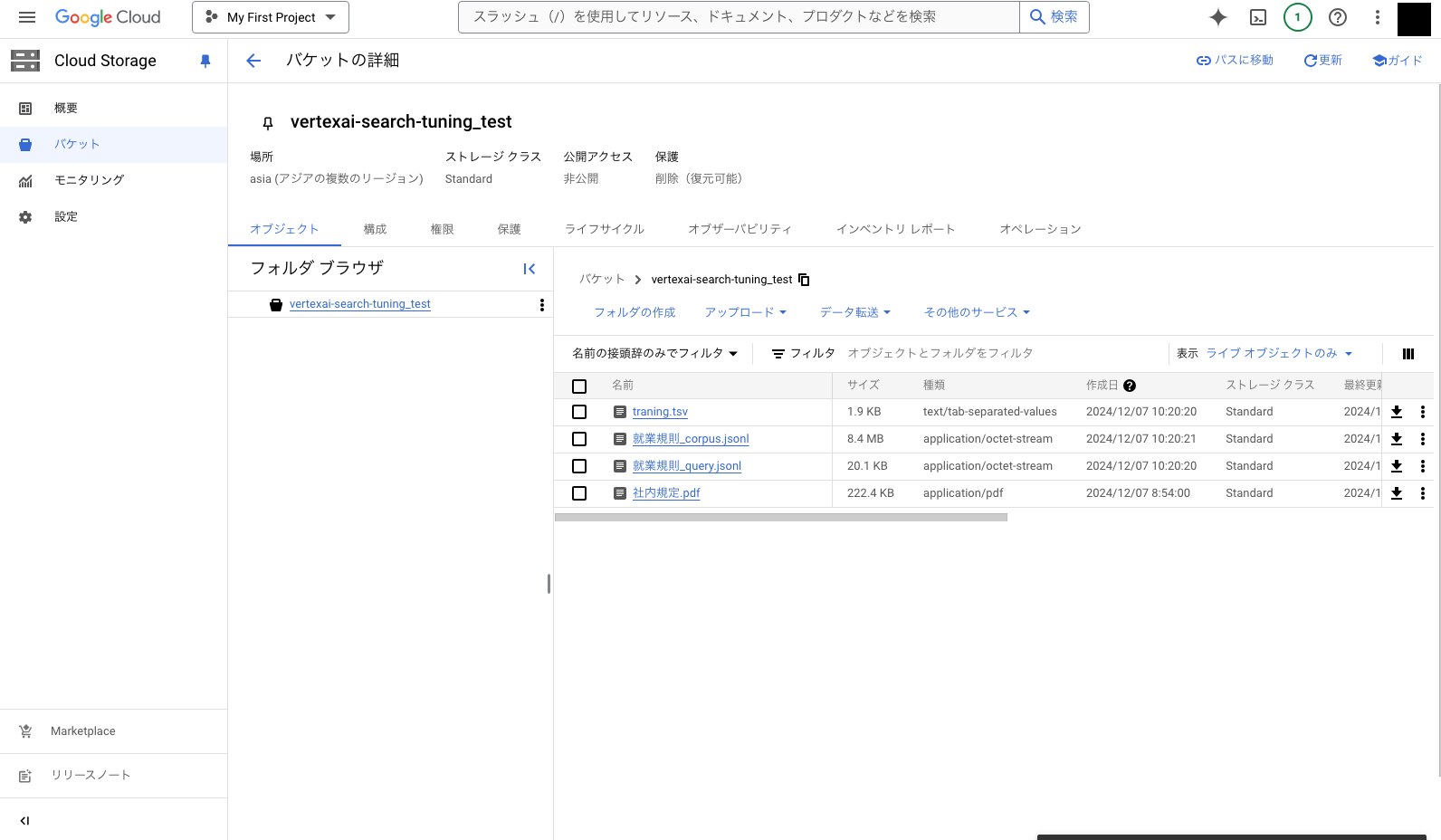
以下の Step 2 から Step 8 は、既に検索アプリを構築済みの方は飛ばしていただいて構いませんが、以下のように Enterprise エディションの機能にチェックは必ず入れてください。
Step 2
検索アプリを構築するため「Agent Builder」を選択します。
Step 3
どちらか一方の「アプリを作成する」をクリックします。
Step 4
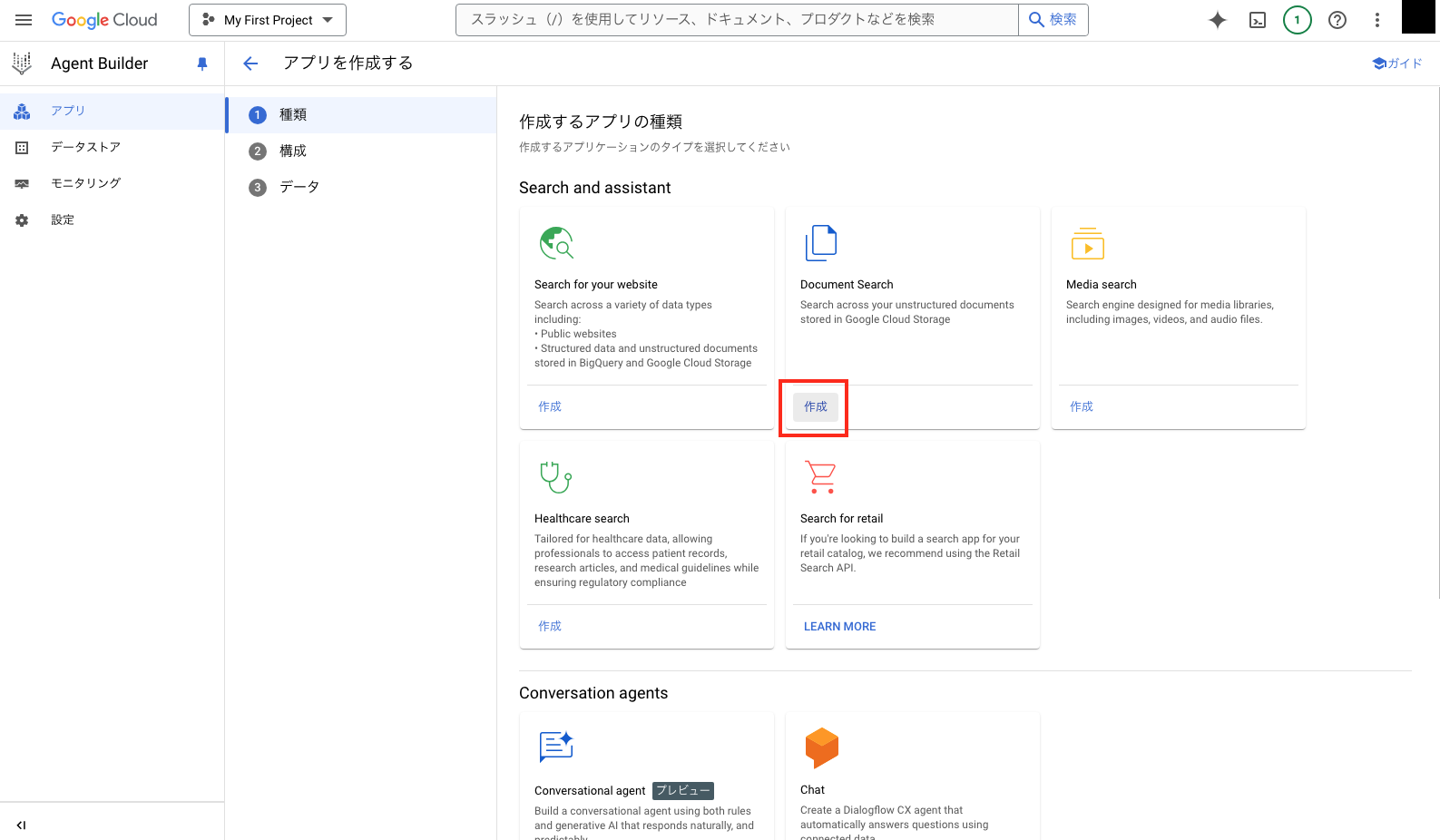
今回は検索チューニングの効果を確認したいため、Document Search の「作成」をクリックします。
Step 5
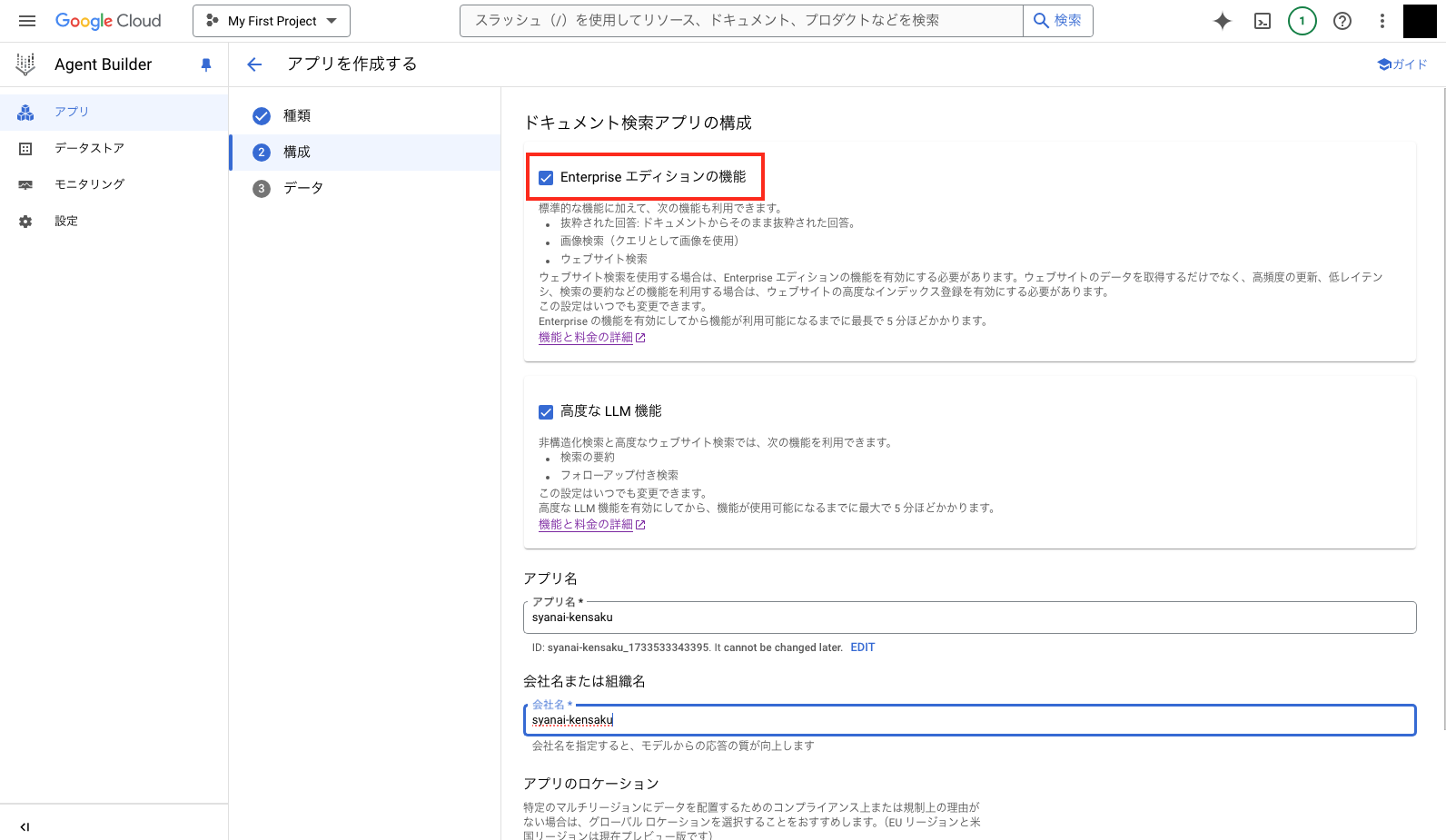
Enterprise エディションの機能にチェックが入っていることを確認してください。
Step 6
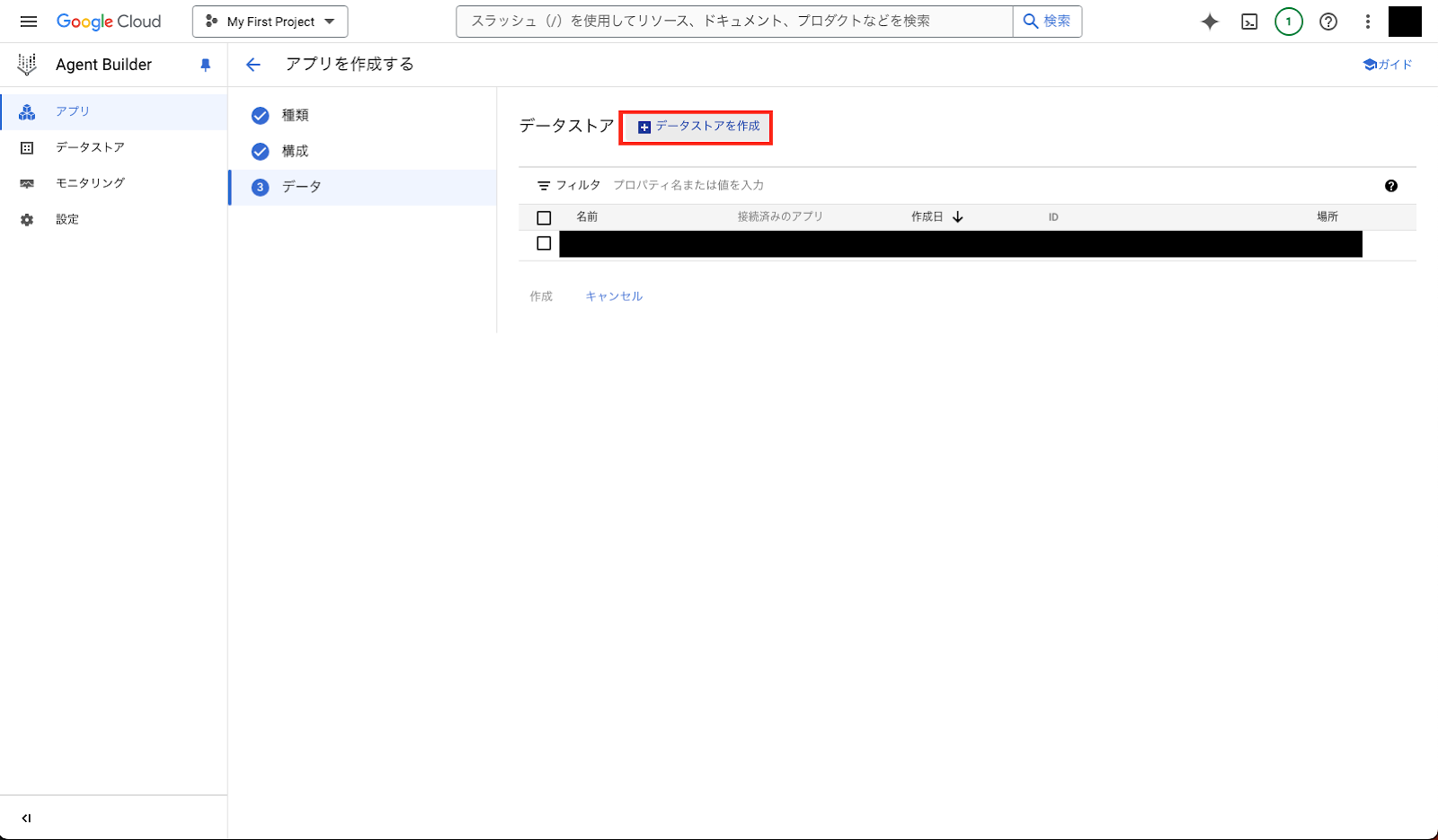
「データストアを作成」をクリックしてください。
Step 7
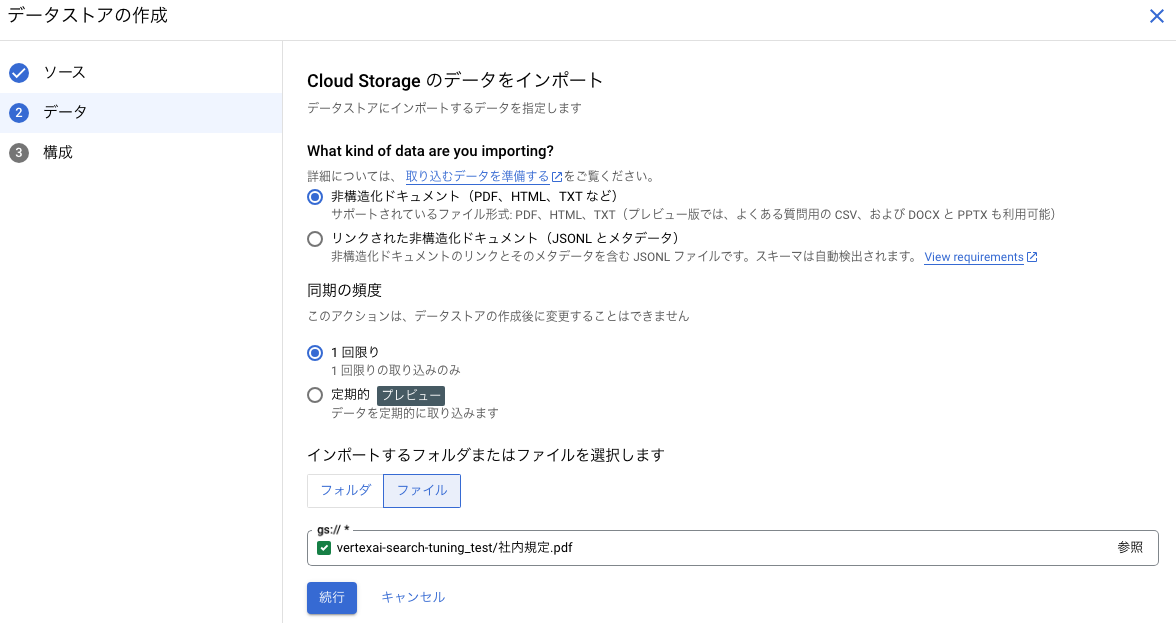
私の場合は、今回使う社内規定のファイルを Cloud Storage に保存していますので、下記のように進めます。

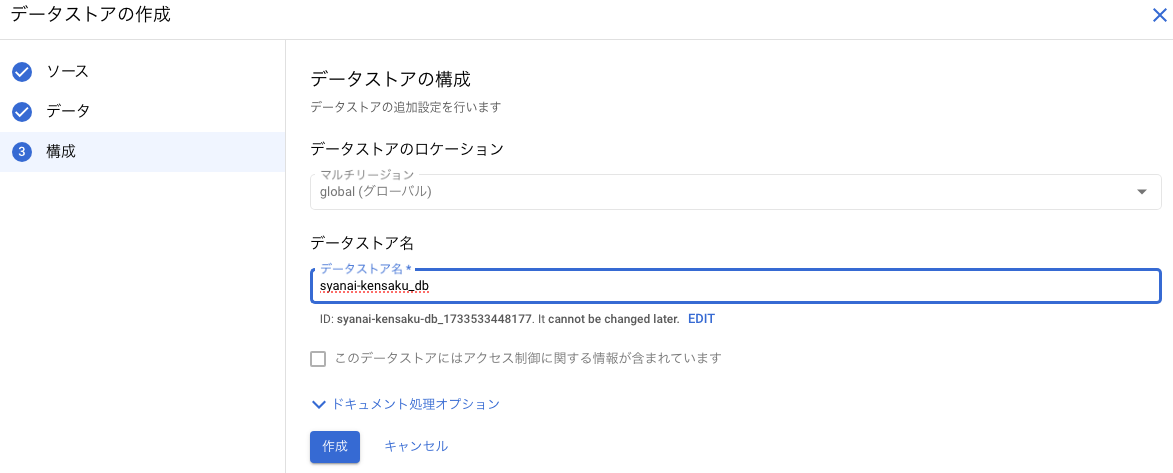
Step 8
「プレビュー」から現在のクエリに対してどのような回答が得られるかを試すことができます。
Step 9
ここからが本題の「検索チューニング」です。
以下どちらかの「ベースモデルのチューニング」をクリックしてください。
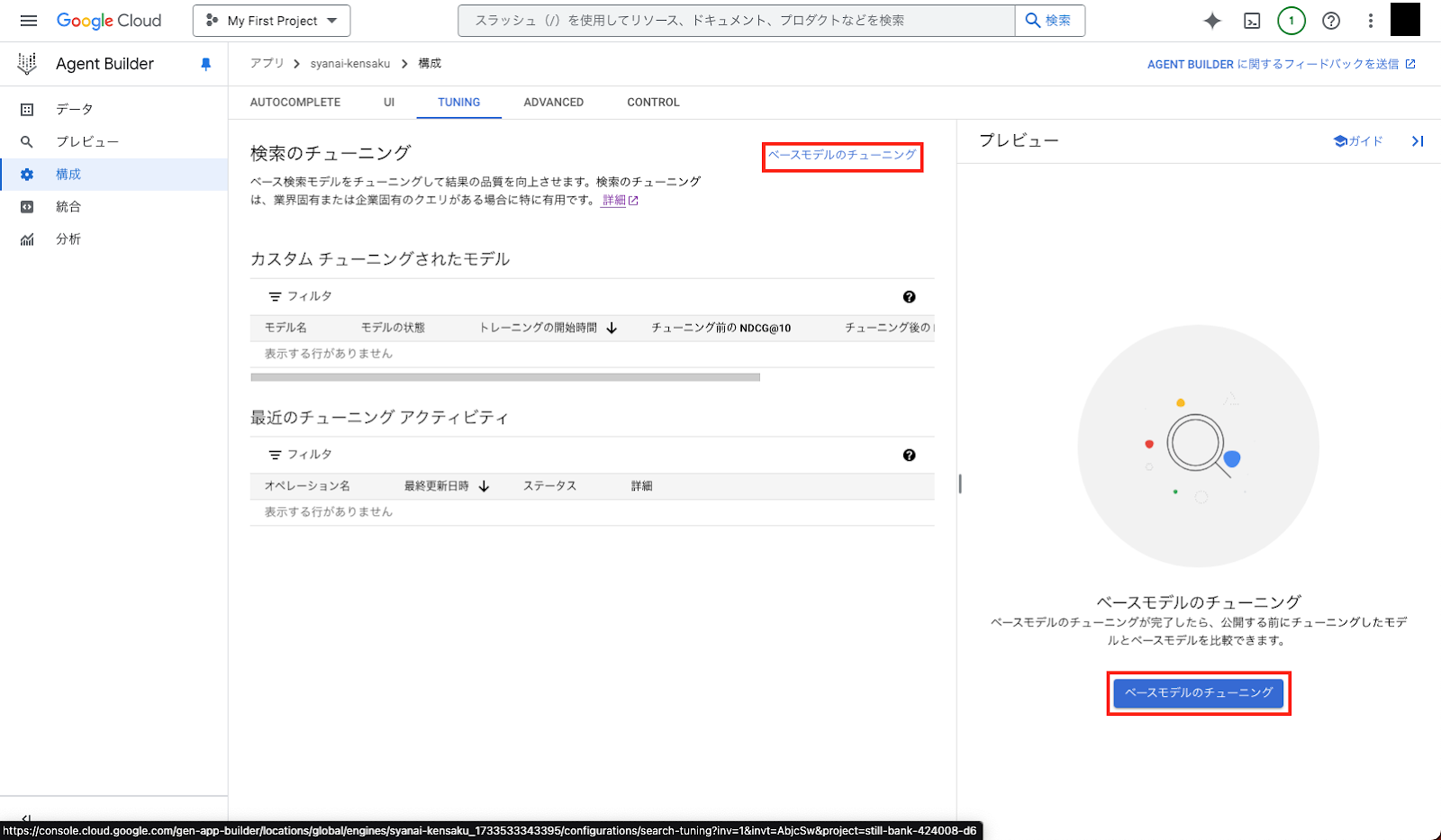
Step 10
コーパス、クエリ、トレーニングに対して下記のように、それぞれ適切なファイルを選択し、「Start Tuning」をクリックしてください。
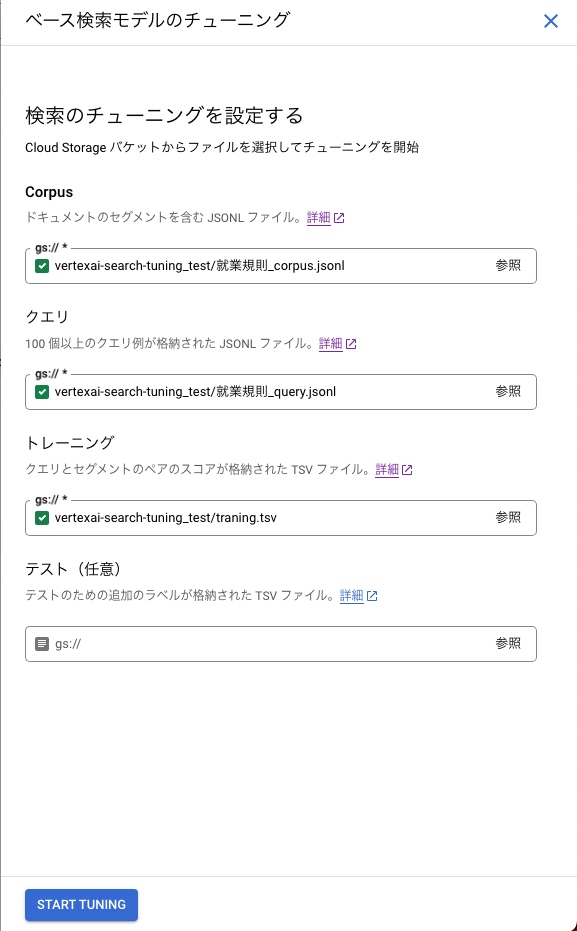
Step 11
すると以下のような画面になると思いますので、チューニングが完了するまで待ちましょう。私の場合は 1 時間程度かかりました。
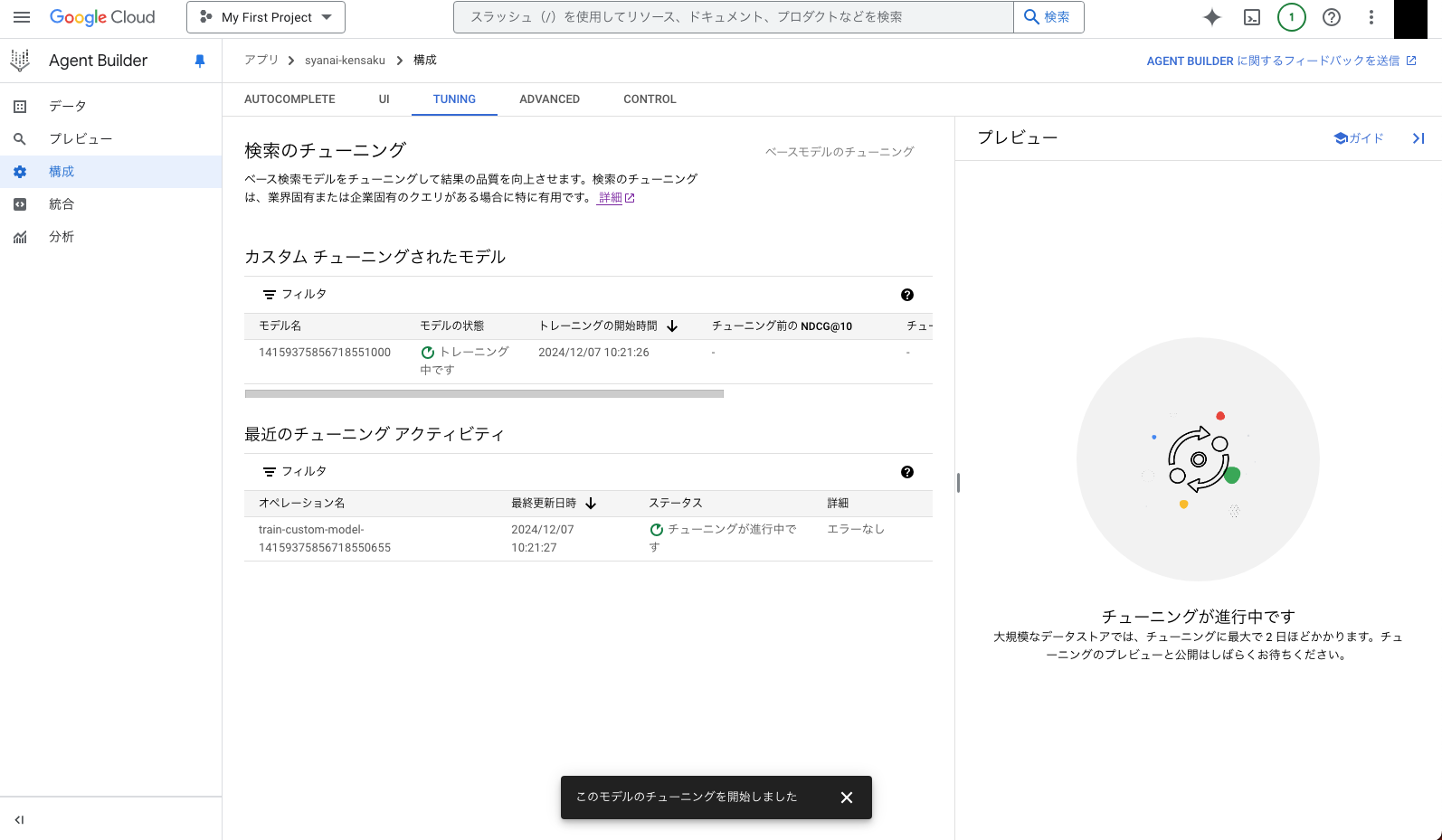
Step 12
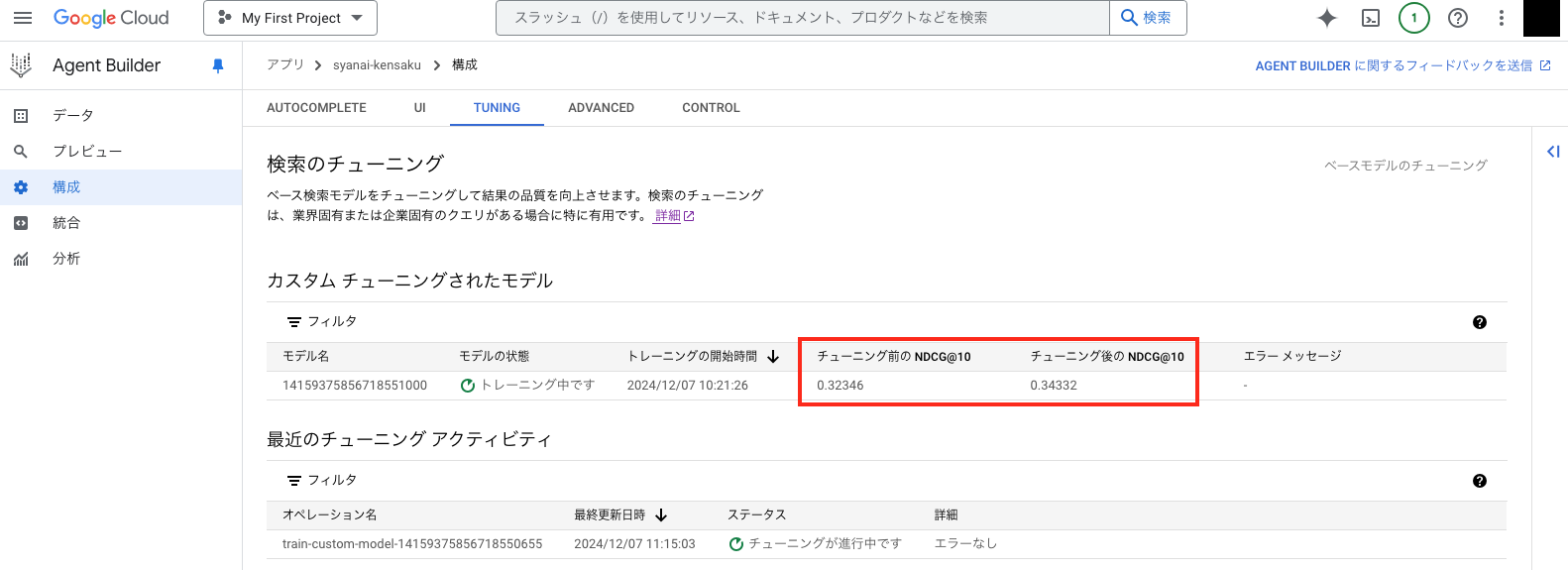
終了するとチューニング前後のスコアが以下画像の赤枠内に表示されます。
トレーニング データが正しいものであれば、チューニング後はスコアが上がっているかと思います。
(補足)NDCG@10 について簡単な説明
NDCG@10(Normalized Discounted Cumulative Gain at 10)は、情報検索や推薦システムで使われる評価指標の一つで、検索結果や推薦リストの「順位付き関連性」を評価するために使われます。特に、値が 1 に近いほど、上位の関連性が高く、理想的な並びに近いことを示します。
検索結果を本棚に例えると、NDCG@10 は「目の前の 10 冊が、あなたが読みたい本の順に並んでいるか」をスコア化するようなものです。
Step 13
プレビューでも比較してみましょう。
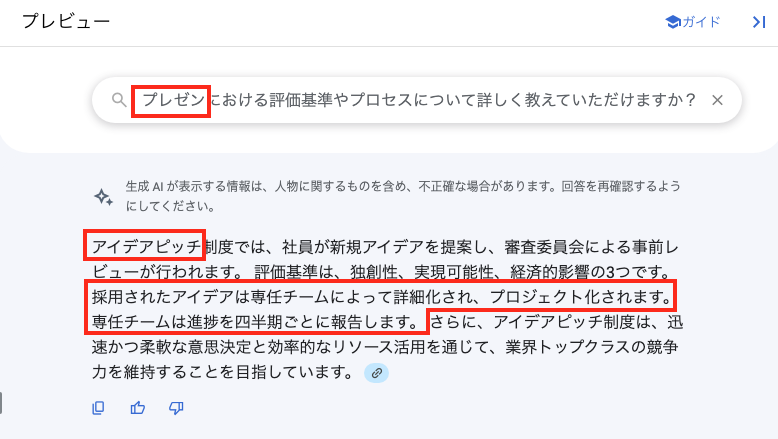
この社内規定を使っている会社にとっての「プレゼンテーション」は「アイデアピッチ」のことを指す風土があるという前提です。
▼ チューニング前
最もらしい回答は得られますが、ドキュメントに記載されている「採用されたアイデアは専任チームによって詳細化され、プロジェクト化され、専任チームは進捗を四半期ごとに報告する。」という大事なプロセスの説明が抜けてしまっています。
以下の赤枠は文書の該当箇所ではない箇所から引用された文章となっており、ハルシネーションを引き起こしています。
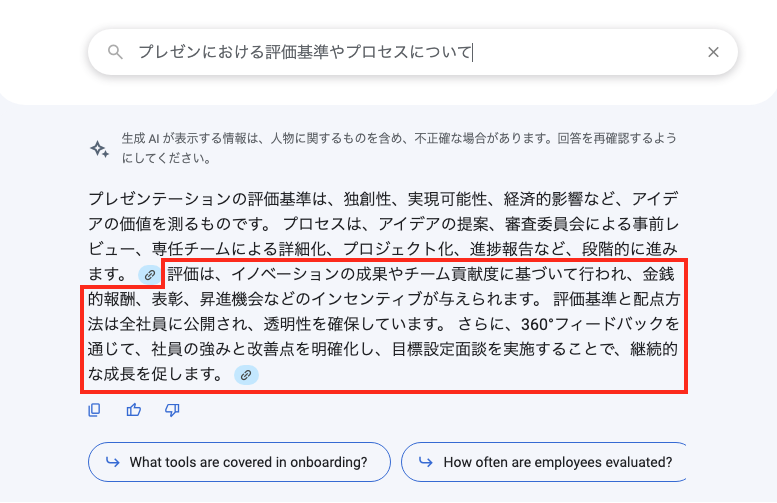
実際の文書に記載されている内容

クエリを「プレゼン」から「アイデアピッチ制度」に変更後は、正しく詳細なプロセスの説明がされていますが、「アイデアピッチ」を「プレゼン」と普段から表現している従業員からするととても使いづらく、「アイデアピッチ」という単語を忘れてしまっていた場合は目的とする情報に辿り着けないかもしれません。
「アイデアピッチ」とすると以下の赤枠のように文書に沿った回答が出力される。
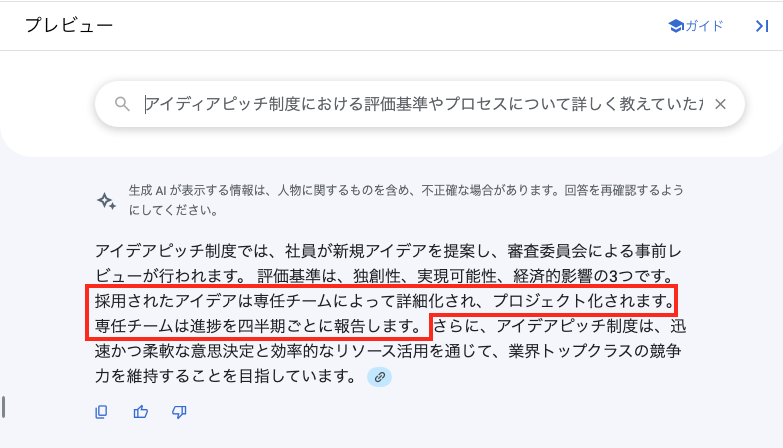
▼ チューニング後
クエリファイルで「プレゼンについて教えてください」というクエリと「アイデアピッチ制度に関する」スニペットをトレーニング ラベルファイルで結びつけることで、以下のように「プレゼン」というクエリが含まれていても正しいアイデアピッチ制度についての情報が表示されるようになりました。
検索チューニング機能を活用するメリット
ここまで見ていただいたように、チューニングをすることで、よりユーザーが求める情報と関連性が高い結果を表示できるようになります。特に、業界用語や社内で使われている言葉などを優先することで、ユーザーの意図に即した結果を提示できます。
また、検索ノイズを軽減し目的の情報に素早くアクセスすることを可能にし、ユーザーの検索時間短縮を実現し、UX の向上にも寄与します。
考慮すべきポイント
検索チューニング機能は非常に強力ですが、その実装と運用には考慮すべきポイントもあります。
この章では、検索チューニング機能を活用する際に直面しうる課題を具体的に解説します。
1. データの品質と量
トレーニング データの質と量は、チューニング結果の精度に直接影響を与えます。不適切なデータや偏ったサンプルを使用すると、検索結果の関連性が低下するリスクがあります。
- 十分なボリューム
Google は 10,000 以上の抽出セグメントを推奨しており、クエリも最低 100 件は必要です。この量を満たさない場合、モデルの汎用性が低下します。
- データの多様性
多様なクエリと関連のある抽出セグメントを用意しないと、特定の状況でのみ有効なバイアスがかかる可能性があります。
- ノイズの除去
関連性の低いセグメントや誤ったスコアリングが含まれていると、検索チューニングの精度が低下します。
2. データの維持管理
検索の精度を維持・向上するためには、最新のトレーニング データを継続的に追加する必要があります。特に、技術の進歩や規制変更が多い業界では、トレーニング データの更新頻度が重要です。古いトレーニング データを基にしたチューニングでは、ユーザーの期待に応えることが難しくなります。
期待通りの検索結果を返しているかを定期的にモニタリングする仕組みがあると良いでしょう。
3. リソースとコスト
チューニングには、トレーニング データの準備やトレーニング時間とコストがかかります。特に、データ収集、整理、スコアリングのプロセスは手間がかかるため、効率的な作業フローを設計する必要があります。
加えて、大量のデータ処理を行うため、クラウド インフラやストレージ コストも考慮が必要です。
4. 非構造化データストアへの適用制限
検索チューニングは非構造化データストアにのみ適用可能です。これにより、構造化データが多い環境では他のソリューションが必要になる場合があります。
非構造化データを活用する場合でも、検索対象が適切に整備されていないと、チューニングの効果が限定的になる可能性があります。
5. 法規制やセキュリティの考慮
チューニングに使用するデータが個人情報や機密情報を含む場合、法規制や社内セキュリティ ポリシーを遵守してください。
最後に
情報の爆発的増加により、ユーザーが必要な情報に迅速かつ正確にアクセスできる環境がますます重要になっています。
Vertex AI Search の検索チューニング機能は、その課題を解決するための強力な機能です。特に、業務効率化やユーザー体験の向上を目指す企業にとって、この機能は競争力を高める大きな武器となります。
皆さんの会社でも導入を検討してみてはいかがでしょうか。



