

目次
概要
こんにちは、grasys でデータ周りのエンジニアリングをしております、t.watanabe です。
今回は whisper を用いて、speech2text の アプリ構築をしていきたいと思います。
speech2text と whisper とは?
speech2text とは、音声から文字列に起こす処理のことです。議事録や音声メモをテキストに起こす場合などあらゆる場面で使用されます。
whisper とは、speech2text を行う一種の計算モデルで OpenAI が作成しています。無料でモデルが公開されており簡単に speech2text をアプリケーションに組み込むことができます。
アプリ構築の背景
議事録などを手打ちで作成していて、つい作業に集中しすぎて話を聞き逃してしまった経験はないでしょうか。
技術の進歩により、議事録は自動で作成できるようになりつつあります。そういったサービスも沢山出てきていますね。
とは言え、議事録には機密情報も含まれるのでセキュリティが気になったり、議事録作成のサービス導入ではなくまずは自分で簡単にできたら良いなと考える方もいらっしゃるのではないでしょうか。
そんな時に、ローカルで処理するだけのシステムを自分で構築できたらと良いなと考えたわけです。
ローカルで処理するだけなので、クラウド化のセキュリティ面を熟考する必要性もなくなります。
アプリを構築するにあたり、要件を整理してみました。
- 外部への情報の送信がない
- 会議を録音し、それを後でまとめられる
- 会議内の情報を思い出せる程度の文字起こしの正確性が必要である
この 3 点を満たす必要がありました。
そこで、録音された会議中の会話から、会議の状況をある程度思い出せるようなソリューションとして whisper を用いた議事録(の補助)ツールを作成することにしました。
今回はそのツールをどなたでも作成、使用できるよう webui 化も含め解説をしていきます。
インストール
使用する環境は Linux(Debian系)、macos を想定しています。windows の方は wsl を用いて Linux 版のインストール方法をご覧ください。
以下、インストールスクリプトとして install.sh に記載してください
Linux(windows wsl)
#!/bin/bash
curl -LsSf https://astral.sh/uv/install.sh | sh
apt install ffmpeg clang cmake build-essential
source $HOME/.local/bin/env
uv python install 3.12
uv python pin 3.12macos
#!/bin/bash
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew install portaudio ffmpeg libavif libcec
brew install uv
source $HOME/.local/bin/env
uv python install 3.12
uv python pin 3.12解説
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"こちらは macos のみで、homebrew というパッケージ管理ツールをインストールしています。
$ curl -LsSf https://astral.sh/uv/install.sh | shbrew install uvこの処理で python のバージョンとパッケージ管理ツールである uv をインストールしています。
$ apt install ffmpeg clang cmake build-essential$ brew install portaudio ffmpeg libavif libcec必要なパッケージをインストールします。
source $HOME/.local/bin/env
uv python install 3.12
uv python pin 3.12あとは python で記載するのでその設定を書き込みます。
実装(python)
以下のコマンドを実行してください
uv init
uv add torch==2.3.1 accelerate>=1.1.1 ffmpeg-python>=0.2.0 numpy<2.0.0 opencv-python>=4.10.0.84 pandas>=2.2.3 scikit-learn>=1.5.2 streamlit>=1.40.0 typer>=0.13.0 transformers llama-cpp-python>=0.3.2 必要な python のパッケージをインストールします。
コードも書きましょう
webui.py
import streamlit as st
import numpy as np
import tempfile
import ffmpeg
import os
import torch
import streamlit.components.v1 as stc
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device: torch.device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
device = torch.device('mps') if torch.backends.mps.is_available() else device
# print(f"Divice is {device}")
st.title("speech2text")
model_id = st.selectbox('モデルのサイズを選んでください', ['openai/whisper-large-v3-turbo', 'openai/whisper-large-v3', 'kotoba-tech/kotoba-whisper-v2.1', 'openai/whisper-base', 'openai/whisper-small', 'openai/whisper-tiny'])
upload_audio = st.file_uploader("テキスト化するファイルをアップロードしてください(システム上に一時的にアップロードしたファイルは文字起こし後に自動で削除されます)", type=["m4a", "mp3", "webm", "mp4", "mpga", "wav"])
generate_kwargs = {"language": "japanese", "task": "transcribe"}
@st.cache_resource()
def create4speech2text(model_id: str):
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
model_kwargs = {"attn_implementation": "sdpa"} if torch.cuda.is_available() else {}
# load model
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True)
model = model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
model = pipeline(
"automatic-speech-recognition",
model=model,
torch_dtype=torch_dtype,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
model_kwargs=model_kwargs,
chunk_length_s=30,
device=device,
)
return model
s2t_model = create4speech2text(model_id)
if "done" not in st.session_state:
st.session_state["done"] = False
if "runnable" not in st.session_state:
st.session_state["runnable"] = False
if upload_audio is not None and st.button("Speech2Text run"):
st.session_state["runnable"] = True
else:
st.session_state["runnable"] = False
if st.session_state["runnable"]:
st.audio(upload_audio, format="audio/wav")
audio = upload_audio
audio = audio.getvalue()
with st.spinner('***Speech2Text を実行中です ...***'):
os.makedirs("./workspace", exist_ok=True)
with tempfile.NamedTemporaryFile(dir='./workspace', suffix='.bin') as fb:
wave_name: str = fb.name + ".wav"
fb.write(audio)
stream = ffmpeg.input(fb.name)
stream = ffmpeg.output(stream, wave_name, format="wav")
ffmpeg.run(stream)
s2t_ret = s2t_model(wave_name, generate_kwargs=generate_kwargs, batch_size=1, return_timestamps=True)
os.remove(wave_name)
text = s2t_ret["chunks"]
texts: str = "\n".join([t["text"] for t in text])
st.session_state["texts"] = texts
st.session_state["done"] = True
if st.session_state["done"]:
st.success('***Text 化を完了しました***')
text: str = st.session_state["texts"]
st.code(text)
st.session_state["runnable"] = Falsewebui を streamlit で用意します。
細かな解説は省きますがこのプログラム(webui.py)を
uv run streamlit run webui.py として実行すると
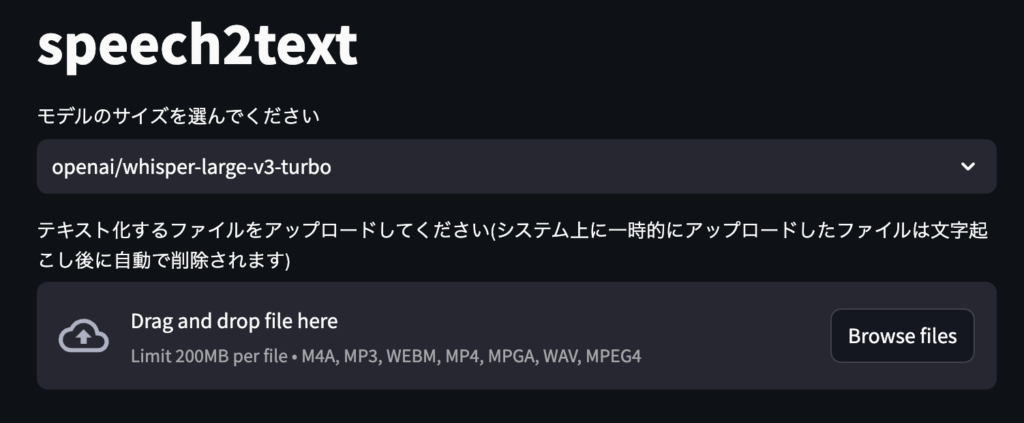
がブラウザ上に表示されます。
Drag and drop file here に録音ファイルを ドラッグ&ドロップ するか Browse files でファイルを指定し、Speech2Text run ボタンが表示されるので押します。
しばらく待つと音声ファイルがテキストになり出力されます。
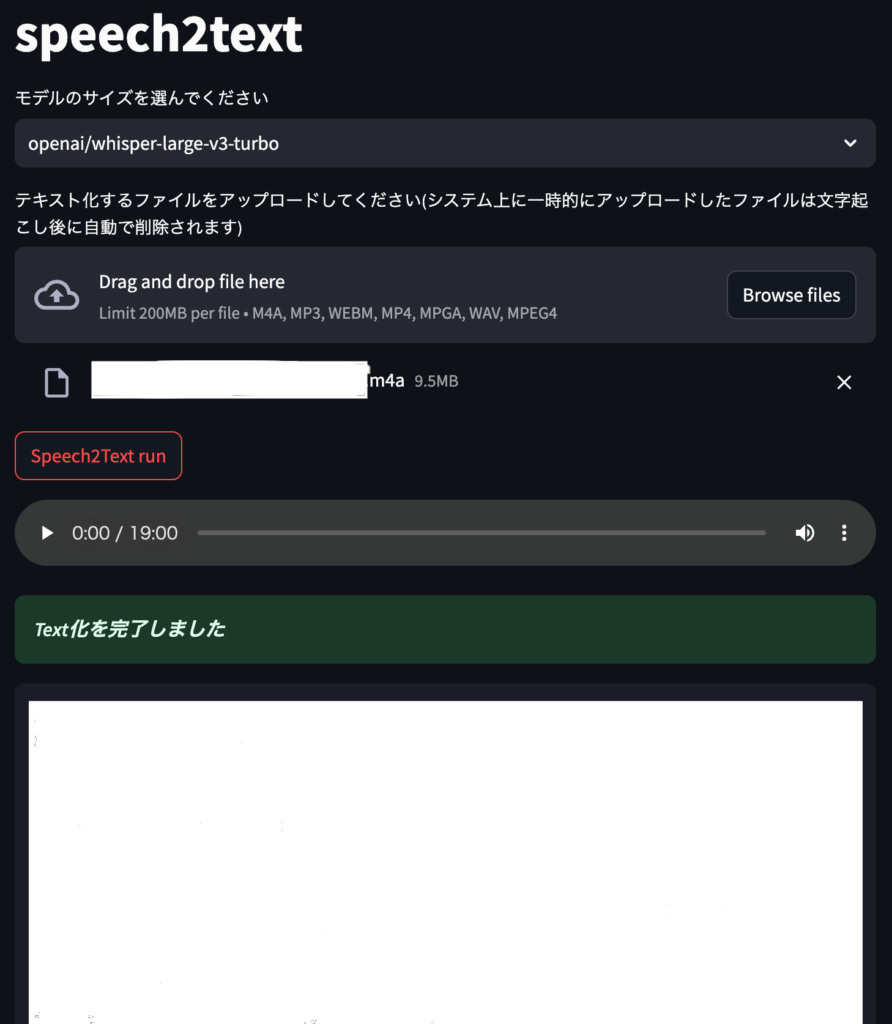
白塗りの部分にテキストがでてきます。
総括
簡単に speech2text を触ってみました。
非常に便利な時代です。



