

目次
前置き
はじめまして、t.watanabe と申します。
データサイエンティストとバックエンドエンジニア出身のデータ大好き人間です。
今回はデータサイエンティスト的な一面として将来に期待したい bitnet についてご紹介しようと思います。
手法の詳しい内容は論文や他のサイト様の説明におまかせするとして、
弊社、手元の端末が mac book なので M chip の mac 上で動かすことを想定して有志の方が公開している bitnet のパッケージのインストール手順や簡単な応用の仕方や実装に付いて触れていきます。
よろしければ、最後までお付き合いお願いします!
概要
bitnet とは?
ここでの結論(はやい)としては
- weight を-1, 0, +1 の3値(もしくは-1, +1の2値)という極端な量子化をしてもよい成績を収める手法を開発しましたよ。
- 今回の量子化によってニューラルネットワークの重みと入力値の行列の計算を軽くできますよ。(掛け算なしで計算可能で、これは、GPUプロセッサでのレイテンシの削減には寄与しづらいです。FPGA や ASIC などで有効と思います。)
- メモリの消費も軽くできますよ。
です、詳しくは下記の内容です。概要が長いなと感じた方はインストールまでジャンプしてください。
昨今話題の深層学習の中でも量子化に関する話です。
以前より深層学習の計算量の問題として行列の積算がありました。
蛇足ですが、結構な計算負荷で、GPU が使われるのはもともと3Dゲームなどで多用する行列の積算(アフィン変換ってやつです)が得意であるため、広く用いられています。
今回、ご紹介の bitnet では行列の積算の箇所のスカラー値の掛け算の要素を簡略化できることが強みです。
簡略化すなわち、符号での計算にすることにより積の計算をせずに符号での条件分けと和と差にすることができ、計算が少なくなります。(少し言及すると積算回路がアフィン変換時に不要になります。)
概要が長すぎでも読みづらいので、利用例に入ります。
macは以下のスペックです。
- product: MacBook Pro
- chip: Apple M3
- macOS: 14.4(23E214)
インストール
非常に簡単です。python 3.11 です。rye などで pin してください。
requirements.txt
torch
transformers
sentencepiece
accelerate
protobuf
scipy==1.9.2
bitnet==0.1.2
scikit-learn==1.2.2
tqdmrye shell
rye pin 3.11
rye add torch transformers sentencepiece accelerate protobuf scipy==1.9.2 bitnet==0.1.2 scikit-learn==1.2.2 tqdm上のどちらかをインストールしてください。
実装(mnistでテスト)
mnist でテストします。
import torch
from bitnet import BitLinear
import torchvision
import numpy as np
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
import tqdm
device = torch.device('mps')
class mnist_model(torch.nn.Module):
def __init__(self, indim: int, outdim: int, hdndim: int=1024):
super().__init__()
self.layer1 = BitLinear(indim, hdndim)
self.layer2 = BitLinear(hdndim, outdim)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.layer1(x)
x = torch.relu(x)
x = self.layer2(x)
x = torch.softmax(x, dim=1)
return x
def load_datasets(batch_size: int = 256):
#訓練データ
train_dataset = torchvision.datasets.MNIST(root='./data',
train=True,
transform=torchvision.transforms.ToTensor(),
download = True)
#検証データ
test_dataset = torchvision.datasets.MNIST(root='./data',
train=False,
transform=torchvision.transforms.ToTensor(),
download = True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=True)
return train_loader, test_loader
def main():
train_loader, test_loader = load_datasets()
model = mnist_model(784, 10).to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.RMSprop(model.parameters())
train_losses = []
for epoch in range(30):
with tqdm.tqdm(train_loader, total=len(train_loader)) as pbar:
for images, labels in pbar:
images, labels = images.view(-1, 28 * 28).to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_losses.append(loss.item())
pbar.set_description(f"[epoch: {epoch + 1}, loss: {np.mean(train_losses)}]")
test_labels = []
test_preds = []
for images, labels in tqdm.tqdm(test_loader):
images, labels = images.view(-1, 28 * 28).to(device), labels.to(device)
outputs = model(images)
test_labels += list(labels.cpu().detach().numpy())
test_preds += list(np.argmax(outputs.cpu().detach().numpy(), axis=1))
labels = np.array(test_labels)
outputs = np.array(test_preds)
print("accuracy: ", accuracy_score(labels, outputs))
print("precision: ", precision_score(labels, outputs, average="micro"))
print("recall: ", recall_score(labels, outputs, average="micro"))
print("/**** **** Confusion Matrix **** ****/")
print(confusion_matrix(labels, outputs))
if __name__ == "__main__":
main()
結果と結論
20[epoch] に対しての各種指標は以下のとおりです。
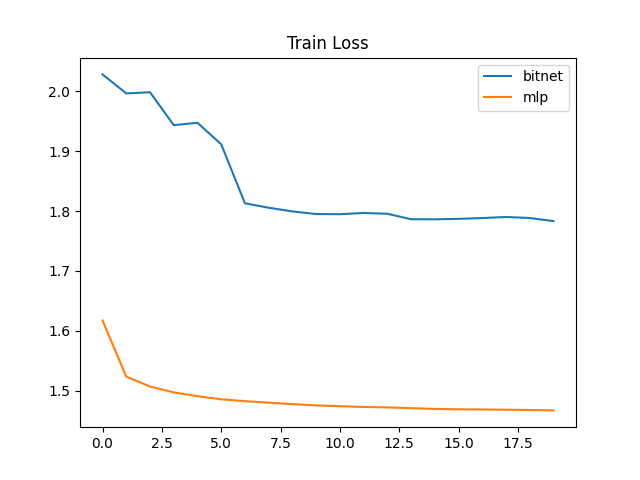
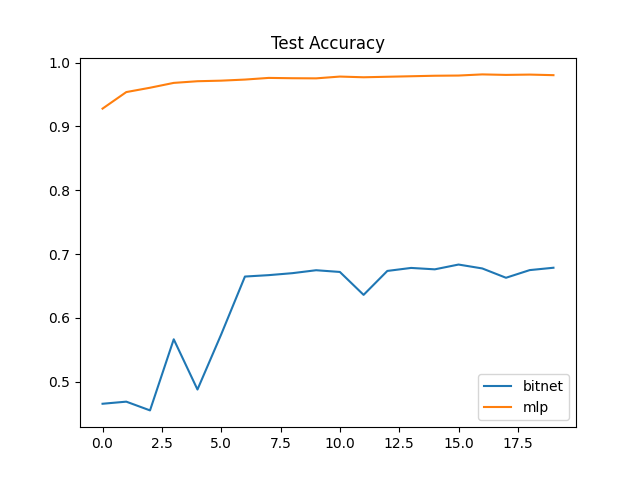
今回は mnist を用いて bitnet の性能評価を行いました。
私の bitnet の学習の実装が悪いと思います、
accuracy が 70% 前後と一般的な量子化なしのモデルに比べ、低い値となりました。
lossも一定の値から下がらない状態です。
mnist に関しては何かしらの工夫が必要そうです。
あとがき
これからの展開に期待!
参考文献
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, Furu Wei BitNet: Scaling 1-bit Transformers for Large Language Models 17 Oct 2023 https://arxiv.org/abs/2310.11453
kyegomez/BitNet https://github.com/kyegomez/BitNet


