

目次
はじめに
こんにちは、ATです。
Dataplexとは、Googleのデータファブリックなサービスです。データファブリックとはインテリジェントな自動システムを使用して、データを一元的に検出、管理するアーキテクチャや環境のことらしく、データファブリックであるDataplexはGoogleの各種サービスを組み合わせデータを一元管理する、といったサービスです。データレイクにとりあえず突っ込んだ雑多なデータを管理するのに使用する感じです。
- データを一括管理
- セキュリティとガバナンスを一元化
- データインテリジェンス(データの検出、管理を自動化)
- etc..
といった特徴があります。
おなじようなサービスでGoogleにはData Catalog があり、似たようなサービスが共存する状況がありました。GoogleはBIツールでもLookerとData Portalがあり、選択肢をいくつか提供している状態でした。LookerとData Portalは明確な機能差がありユースケースもそれぞれ異なっているので選択に悩むことや使い所に迷うことは無いですが、DataplexとData Catalog にはデータ管理するといったところでは明確な差が分かりにくく(というかわからなかった)この先どのように差別化していくのか興味本位で観察してました。そんな中今年の7/21以降Data Catalog をDataplex に統合して Dataplex の一部になるとの発表がありました。晴れて2つのサービスがひとつになることに。あら、そうなるのねという感じでこれで余計なこと気にしないで良くなって、よかった、よかったw
そんなDataplex ですがイメージは湧くが実際はどんなものか?というわけでやってみることに。
(2022.09/07作成)
設定
事前準備
- Dataplex API の有効化
- 必要な権限の付与(roles/dataplex.admin or roles/dataplex.editor)
- 管理するデータ。今回はGCS上のファイルを管理する
- バケット:dataplex-test01
- フォルダ:customers
- CSVファイル:customer.csv
- フォルダ:images
- 画像ファイル:black.png
- フォルダ:customers
- バケット:dataplex-test01

有効にする
手順
下記の手順でデータをDataplexで管理する。
- lakeの作成
- zoneの作成
- assetの作成
lakeの作成
「レイクを作成」を押下
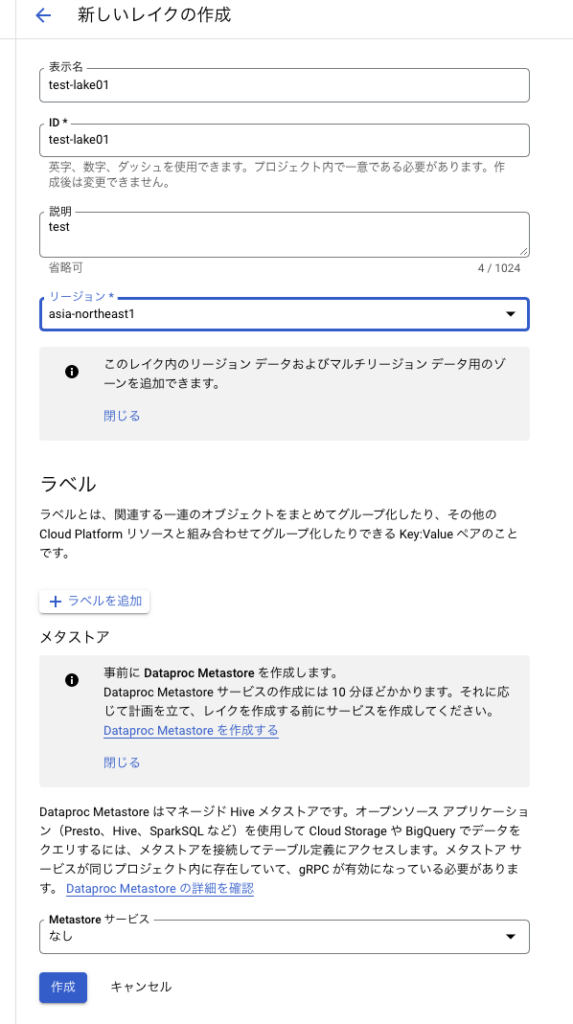
名前を適当に入力、リージョンを選択する。今回はメタストアは使用しないので「なし」。入力できたら「作成」を押下。
zoneの作成
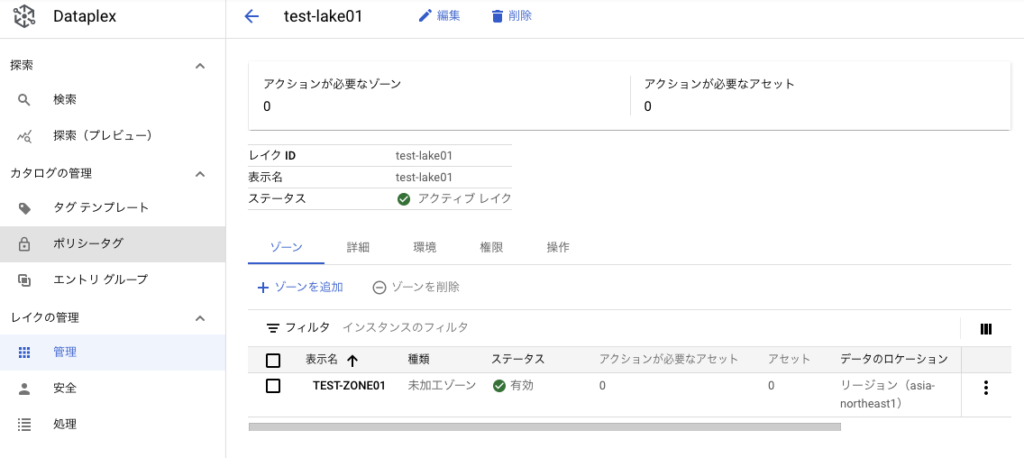
lakeの表示名(この場合、TEST-LAKE01)を押下するとzone一覧に遷移する
「ゾーンを追加」を押下
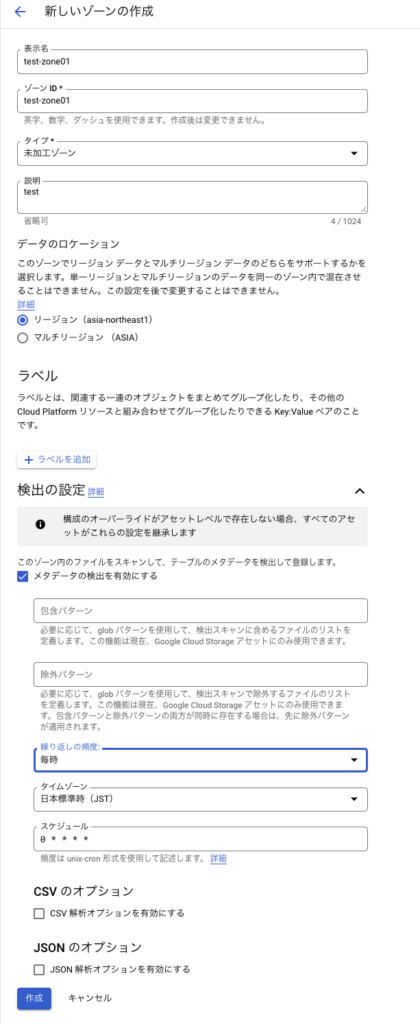
表示名を入力する。タイプは「未加工ゾーン」を選択。生データとかは未加工ゾーンにしておくと良いみたい。その他特に設定することもなく「作成」を押下。
assetの作成
「TEST-ZONE01」を押下すると、アセット一覧に遷移する。
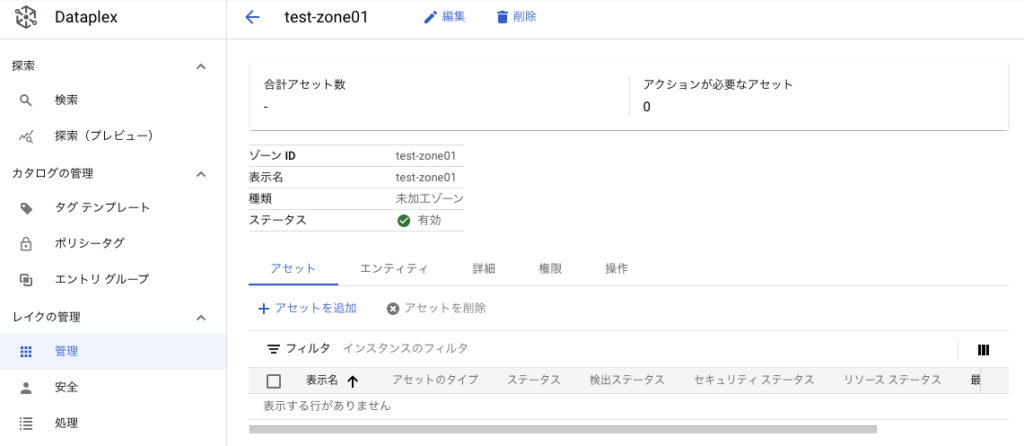
「アセットを追加」を押下
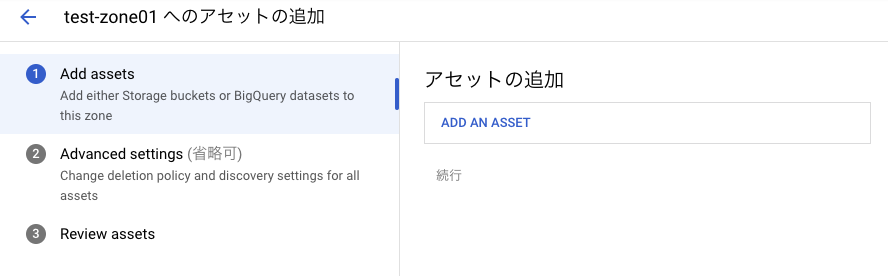
「ADD AN ASSET」を押下
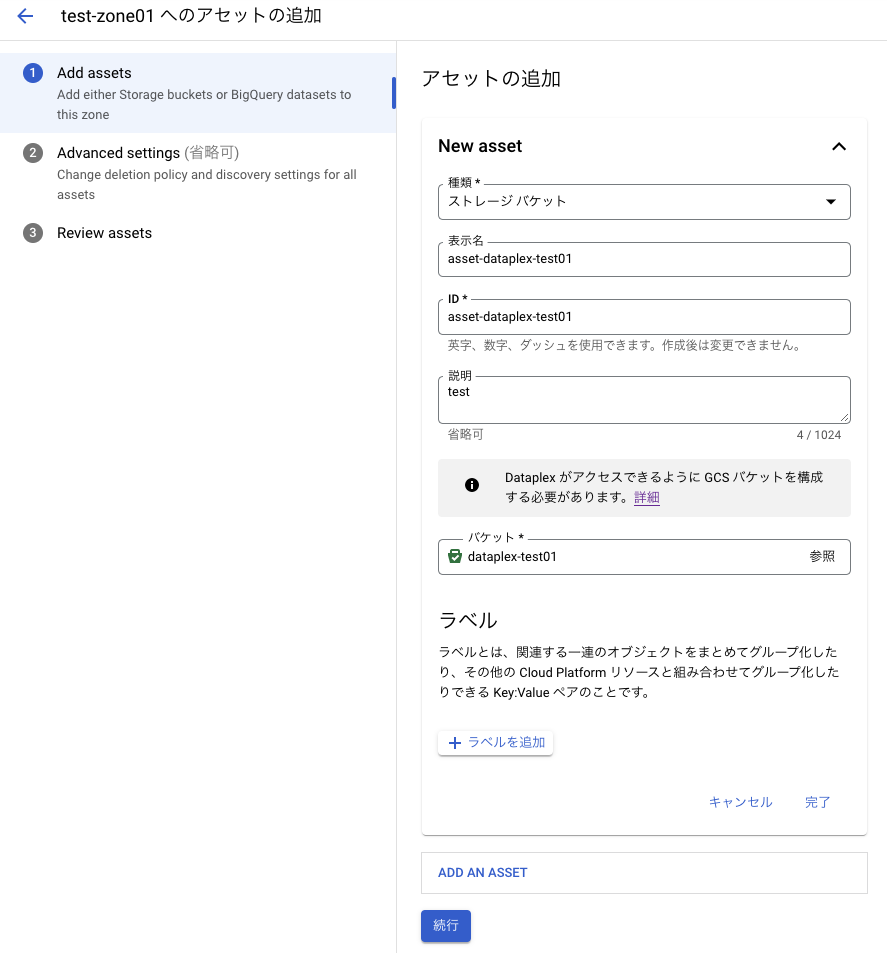
種類は「ストレージバケット」を選択する。種類は「ストレージバケット」か「BigQueryデータセット」が選べる。名前を入力し、最後に事前に作成したバケットを指定する。「続行」を押下。
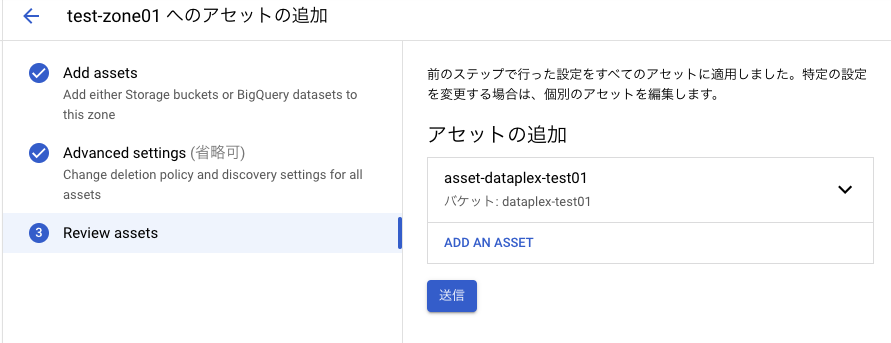
Advanced settings は何も設定せず、最後に「送信」押下でアセットが作成される。
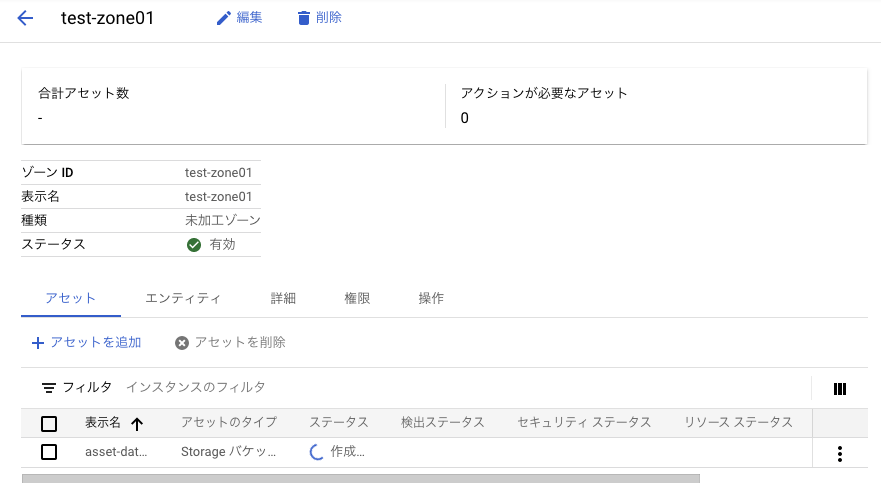
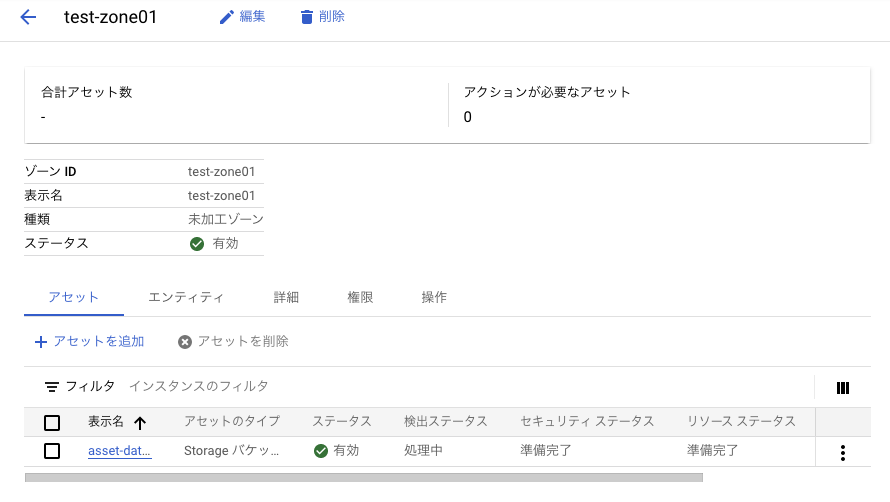
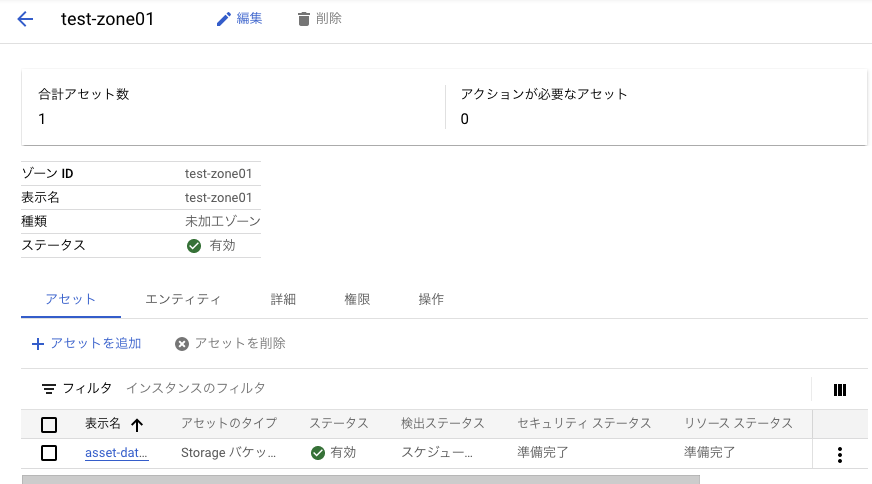
しばらく待つとアセットが完成した。ついでにデータ検出も行われているらしい。
これにて設定が完了。
管理されたデータの確認
検索画面から、Dataplexに登録されたデータを確認できる。
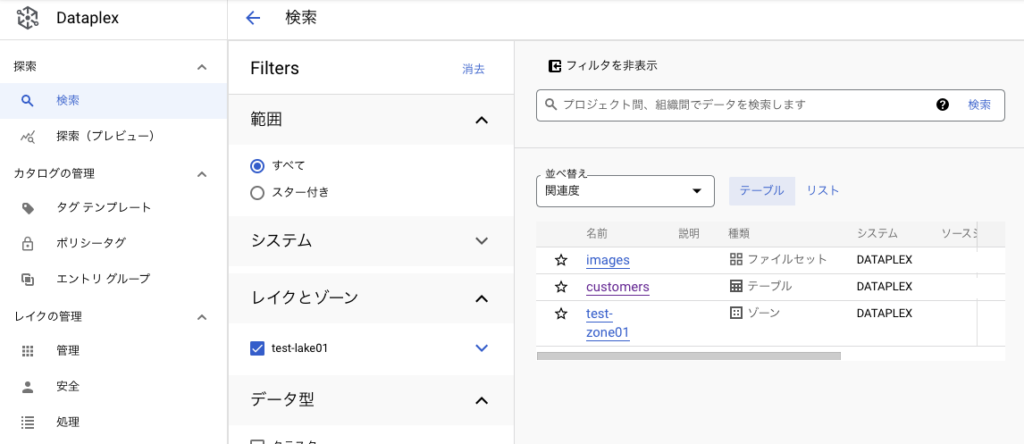
作成したレイクにチェック入れるとゾーンと登録したアセット配下のデータが表示される。CSVも認識されている。
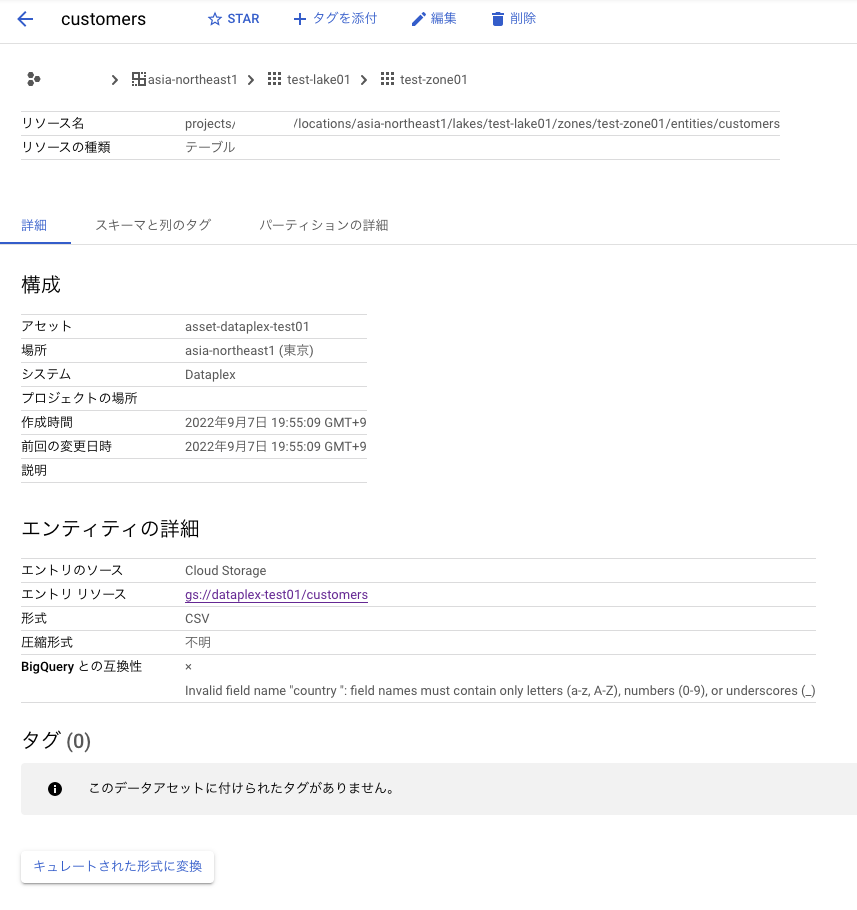
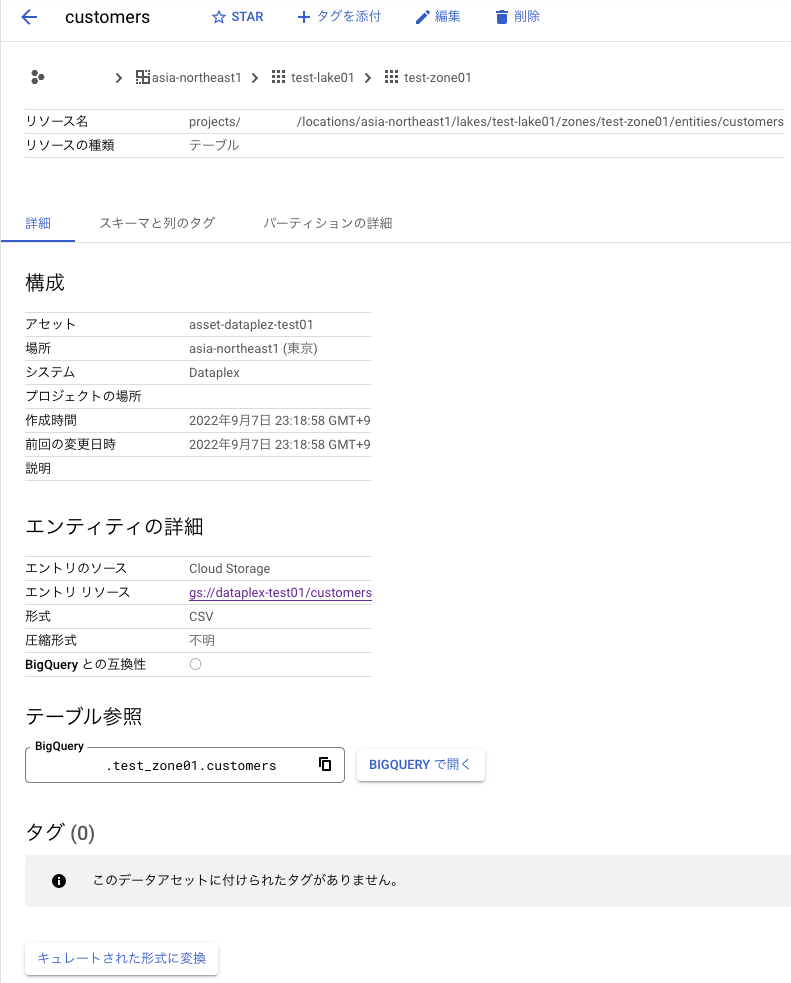
データの検出は?
半構造化データはうまく認識して、メタデータを自動で取得してくれている。個人的に非構造データはどう処理されるのが結構気になっており、今回Dataplexを触った動機の一つだったりします。
非構造データとして今回は画像ファイルを置いてみたが「画像」と表示されるのみだった。フォーマットやサイズくらいは取得しないかなぁと思っていたが、そんなことはなかった。(試しに音声ファイルの拡張子をjpgとしてバケットに置いといたら画像ファイルと判定された。ファイル中身までは見ていないぽい)

Googleなら画像認識で「人」とか「車」なんてタグが付くとか期待してたんだけどw
さいごに
今回気になったことが一つあった。検出後になにか問題があると、問題あるよと表示される機能がある。無効なファイルを検出した時やフォーマットが不正な場合にその旨表示してくれる。内容的にも問題がある対象を表示してくれてなかなか便利。で、それはいいのだが修正して、それを確認しようとすると次の検出処理を待たなくてはならない。これはちょっと参った。ドキュメントには下記の通り次の検出処理で解決するよなんてかいてあり(ココ)待つしかない。

再実行ボタンとかあればよかったのにと思う。
とりあえず使ってみました。使ってみた感想はとしてはそれほど設定は複雑でなくまぁまぁと言った所でした。今回はチュートリアルレベルだったので次回があればもう少し踏み込んで色々な機能を触ってみたい。セキュリティや権限周りの設定も何もしていないのでそちらも機会があればゼヒ。



