

目次
はじめに
こんにちは。2023 年 9 月に grasys に入社したミャンマー出身のスースーです。
この記事では、前回の「Mecabを試してみた」という記事の続きとして、Python を使って Mecab と Qdrant(ベクトルデータベース)を連携する方法を紹介します。
まだ前回のブログを読んでいない方は、そちらを先に読んでみてください。

では早速、Python で Mecab を使ってみましょう!
Mecab を python で実施
Mecab は色々な言語をサポートしていますが、今回は python を使って実施方法を説明します。
mkdir mecab_blog
cd mecab_blog
rye init . --min-py 3.11 --no-pin --private --virtual
rye sync
touch mecab_qdrant.py下記のコマンドを実行します。
mecab-config --dicdir
mecab_qdrant.py ファイルに下記のコードを記入します。
import MeCab
# MeCab タガーを初期化する
tagger = MeCab.Tagger("-d /opt/mecab/lib/mecab/dic/ipadic -Owakati")
#日本語の言葉を入力する
text = "旅行団体"
#テキストを解析する
parsed = tagger.parse(text)
#解析結果を表示する
print("結果:")
print(parsed)
ここでは、mecab-config –dicdir コマンドで実行した file path を Mecab.Tagger へ入れています。
私の file path は /opt/mecab/lib/mecab/ なので /opt/mecab/lib/mecab/dic/ipadic へ入れています。
次に、下記のコマンドを実行します。
rye add mecab
rye sync
rye run python mecab_qdrant.pyこちらは python ファイルを実行した結果です。
Mecab では、本来「旅行団体」という言葉を「旅行」「団体」と二つの言葉に形態素解析しますが、前回のブログで Mecab の辞書へ「旅行団体」という言葉を追加しているので、今回の結果では一つの言葉として認識されています。

Mecab を Qdrant と Bert Japanese で実施
次に、形態素解析した結果を検索する方法を紹介します。
以下のような流れになります。
- Mecab を使って形態素解析した結果を
- Qdrant(ベクトルデータベース)に登録し
- BERT Japanese を使って検索する
Qdrant について知りたい方は、こちらのブログをチェックしてみてください。

Qdrant(ベクトルデータベース)が分かっている方はこのまま読み進めてください。
まずは、下記のコマンドを実行します。
touch qdrant.py下記のコードを qdrant.py ファイルに記入してください。
from qdrant_client import models, QdrantClient
#docker に Qdrant のポート番号は 6333 で実行しているので 6333 を入れる
client = QdrantClient("0.0.0.0", port=6333)
client.recreate_collection(
collection_name="dictionary_data", # 作成したい collection の名前をいれる
vectors_config=models.VectorParams(
size=768, # ベクトルサイズは使用するモデルによって定義される
distance=models.Distance.EUCLID, # Euclidean distance を入れる
),
)
下記のコマンドを実行します。
rye add qdrant
rye sync
rye run python qdrant.py下記のように dictionary_data を Qdrant の collections に作成出来ました。
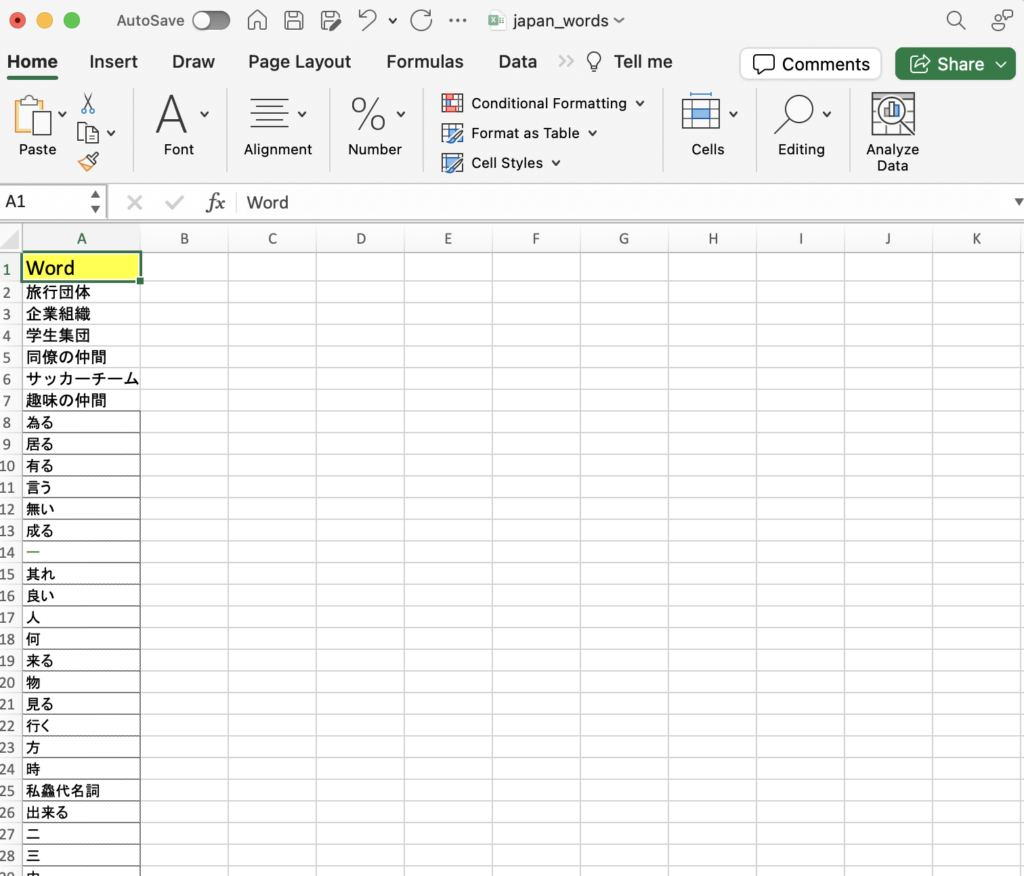
japan_words.xlsx ファイルに下記のようなデータを入れてください。自分が入れたい言葉を入れても大丈夫です。
下記のコマンドを実行します。
touch update_dicitonary_data.pyupdate_dicitonary_data.py のファイルに下記を記入してください。
from qdrant_client import models, QdrantClient
import pandas as pd
from transformers import AutoModel, AutoTokenizer
#bert japanese model を使って vector database にデータをインポートする。
model_name = "cl-tohoku/bert-base-japanese-v3"
bertjapanese = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
client = QdrantClient("0.0.0.0", port=6333)
#エクセルファイルのデータをインポートする
df = pd.read_excel('./japan_words.xlsx')
#dictionary に変換する
myDict = df.to_dict('records')
# bert japanese で日本語の言葉をベクトルで変換して Qdrant Collection にデータ登録する
client.upload_records(
#インポートしたい collection の名前を記入する
collection_name="dictionary_data",
#bert japanese モデルは dimension = 768 なので 768 ベクトルでデータ登録する
records=[
models.Record(
id=idx, vector=bertjapanese(**tokenizer(doc["word"], return_tensors="pt"))[0][0][0], payload=doc
)
for idx, doc in enumerate(myDict)
],
)
print ("データ登録成功になりました。")
下記のコマンドを実行します。
$ rye add pandas
$ rye add transformers
$ rye add torch
$ rye add fugashi
$ rye add unidic_lite
$ rye add openpyxl
$ rye sync
$ rye run python update_dicitonary_data.py
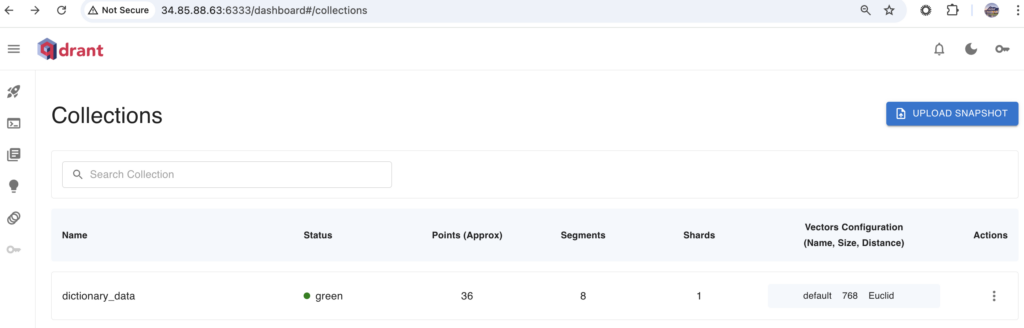
update_dicitonary_data.py を実行すると下記のようになります。Qdrant の collection にデータをアップロードしました。
下記のコマンドを実行します。
touch mecab_separate.py
touch mecab_qdrant_search.pymecab_separate.py のファイルに下記を記入してください。
import MeCab
import pandas as pd
class CustomMeCabTagger:
MECAB_COLUMNS = ['word',
'speech',
'subclassification_1',
'subclassification_2',
'subclassification_3',
'utilization_type',
'conjugation_form',
'original_form',
'reading',
'pronunciation',
'new_word_flag',
'remark',
]
def __init__(self, dicdir=None):
if dicdir:
self.tagger = MeCab.Tagger(f"-d {dicdir}")
else:
self.tagger = MeCab.Tagger()
def parseToDataFrame(self, text: str) -> pd.DataFrame:
"""テキストを parse した結果を Pandas DataFrame として返す"""
new_word_data = []
new_word_pd = ""
for line in self.tagger.parse(text).split('\n'):
if line == 'EOS':
break
if '\t' not in line:
continue
surface, feature = line.split('\t')
feature = [None if f == '*' else f for f in feature.split(',')]
# mecab の基本列は 9 つなので、追加した2列の言葉だけを取得する場合は 10 以上のデータのみ取得する。
if (len(feature) >= 10):
new_word_data.append([surface, *feature])
# 新しい言葉の合計
word_total = len(new_word_data)
# 新しい言葉だけ渡す
if (len(new_word_data) > 0):
new_word_pd = pd.DataFrame(new_word_data, columns=type(self).MECAB_COLUMNS)
return new_word_pd, word_total
下記のコマンドを実行して、dicdir の filepath を取得します。
mecab-config --dicdirmecab_qdrant_search.py のファイルに下記を記入してください。
dicdir の filepath には先ほど取得した file path を入れてください。
from qdrant_client import models, QdrantClient
from transformers import AutoModel, AutoTokenizer
import MeCab
import mecab_separate
#docker に Qdrant のポート番号は 6333 で実行しているので 6333 を入れる
client = QdrantClient("0.0.0.0", port=6333)
#bert japanese model を使って collection データを検索する。
model_name = "cl-tohoku/bert-base-japanese-v3"
bertjapanese = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Input Japanese text
text = "お疲れ様です。お元気ですか。旅行団体で旅行しますか?大学で学生集団しますか?"
tagger = mecab_separate.CustomMeCabTagger(dicdir='/opt/mecab/lib/mecab/dic/ipadic')
df, total_word_count = tagger.parseToDataFrame(text)
#新しい言葉だけを取得しているので新しい言葉の結果
print("結果:")
print(df['word'])
datas = df['word']
for word in datas:
# collection データで言葉を検索する。
# limit 3 は取得データ一つを取得するという意味です。
print("qdrant で",word, "の検索結果:")
hits_bertjp_eu = client.search(
collection_name="dictionary_data",
query_vector=bertjapanese(**tokenizer(word, return_tensors="pt"))[0][0][0],
limit=3,
)
# 結果とスコアで表示する
for bertjp_eu in hits_bertjp_eu:
print(bertjp_eu.payload, "score:", bertjp_eu.score)mecab_blog の中に下記のようなファイルがあります。

下記のコマンドを実行します。
rye run python mecab_qdrant_search.py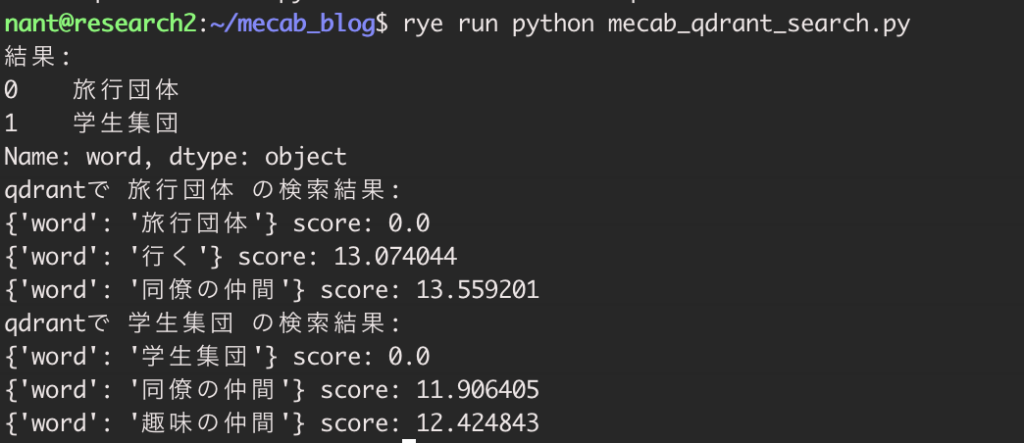
Qdrant で検索をすると、検索した言葉との類似度をスコアとして表示します。
完全一致している言葉のスコアは 0.0 で表示されます。今回は「旅行団体」という言葉を事前に登録していたので、スコアが 0.0 となっています。
完全一致ではない言葉はそれぞれのスコアが表示されます。今回はスコア 11〜13 までの言葉が表示されていますが、Qdrant へさらに多くの言葉を登録すると、上記よりもスコアの低い(類似している)言葉が表示されるようになると思います。
まとめ
今回のブログでは Mecab と Qdrant と Bert Japanese の以下について説明してきました。
- Mecab で形態素解析をする方法
- Mecab の辞書に追加した二列のカラムに入っている言葉のみを形態素解析する方法
- Mecab で形態素解析して新しい言葉だけを取得し、Qdrant のデータを Bert Japanese のモデルを使って検索する
Mecab と Qdrant と Bert Japanese に関する情報はまだまだ少ないので、このブログが学んでる人の助けになれば嬉しいです。
こちらのブログもぜひチェックしてみてください。

