

目次
はじめに
こんにちは。2023 年 9 月に grasys に入社したミャンマー出身のスースーです。grasys に入社してからは、これまで自分が触ったことのなかった新しい技術を色々触ることが出来ました。今回はその中の一つである MeCab について説明します。
現在 AI は有名になりましたよね。AI モデル、特にテキスト分類、感情分析、翻訳などのモデルでは、テキストをトークン化するか、意味のある単位に分割する必要があります。MeCab は、単語間にスペースがない日本語テキストのトークン化に優れており、AI モデルを強化できる形態情報を提供します。
形態素解析
国によって色々な言語があります。それら言語に合わせて様々な形態素解析があります。
なぜ形態素解析は必要なのでしょうか?
AI は人が書いた様々な文章を検索しています。そして、検索した文章をシステムで分析しています。入力された文章を単語や形態素に分割し、それぞれの品詞や基本形、読み仮名などを解析します。この分析をするために形態素解析が必要になりました。
例:英語文章
My name is Su Su.
これを形態素解析すると「My name、is、Su Su、.」になります。英語の文章にはスペースがあります。スペースがあるので形態素解析は日本語より簡単になります。
日本語の文章にはスペースがありません。日本語ではどのような形態素解析になるでしょうか?
例:日本語文章
私の名前はスースーです。
この文章を形態素解析すると「私、の、名前、は、スースー、です、 。」になります。日本語の形態素解析には色々なモデルがあります。そのモデルの一つ、Mecab についてこれから説明します。
Mecab とは?
MeCab は、日本語のテキストを処理および分析するために設計されたオープンソースの形態素解析ツールです。これは、単語間にスペースがなく、複雑な文法構造を持つ日本語を扱う場合に特に役立つ、自然言語処理(NLP)タスクに使用される強力なツールです。
Mecab は Python や Java、C 言語で使えるので利用しやすいです。
Mecab を選んだ理由
日本語形態素解析は下記のように様々な種類があります。
- Mecab
- Nagisa
- SentencePiece
- Sudachi
- Kuromoji
- Juman++
- Yahoo! 形態素解析 API
私は、この中から Mecab、Nagisa、SentencePiece で比較検討しました。
Nagisa は形態素解析で言葉を取得するのは簡単だったのですが、新しく言葉を追加するのは難しい印象がありました。
SentencePiece も実際にテストしてみたのですが、Nagisa と同様に言葉の追加など難しかったです。
簡単に言葉を追加できること、使い勝手が良いことなどの観点から、私は Mecab を選びました。
Mecab の良い点
私は、Mecab の以下の点が良いなと思っています。
- 新しい言葉を簡単に追加出来る
- Python、Java、C++、Ruby、Go で利用出来る
- オープンソースソフトウェアなので無料で利用出来る
- ソースコードを柔軟にカスタマイズできる
Mecab のインストール方法
私は google vm instance の linux debian を使っているので、下記は linux debian でインストールする方法です。
Mecab の ipa 辞書へ新しく言葉を追加したいので mecab-0.996 と mecab ipa の二つをダウンロードしてインストールします。
mkdir mecab_source
cd mecab_source
#ソースコードをダウンロードして解凍、移動
wget 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE' -O mecab-0.996.tar.gz
tar zxvf mecab-0.996.tar.gz && rm mecab-0.996.tar.gz
cd mecab-0.996
#インストールフォルダーを作成する
sudo mkdir -p /opt/mecab
# configure(コンパイルのための設定)、コンパイル、インストールを実行
./configure --prefix=/opt/mecab --with-charset=utf8 --enable-utf8-only
make
sudo make install
#環境変数を設定
echo "export PATH=/opt/mecab/bin:\$PATH" >> ~/.bashrc
source ~/.bashrc
#mecab-0.996 フォルダーから出る
cd ..
# mecab ipa のソースコードをダウンロードして解凍、移動
wget 'https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM' -O $mecab_ipa_name.tar.gz
tar zxvf $mecab_ipa_name.tar.gz && rm $mecab_ipa_name.tar.gz
cd $mecab_ipa_name
#configure(コンパイルのための設定)、コンパイル、インストールを実行
./configure --with-mecab-config=/opt/mecab/bin/mecab-config --with-charset=utf8
make
sudo make installインストールした Mecab が実際にインストールされて動いているかを確認します。
下記のコマンドを実行します。
echo "私の名前はスースーです" | mecab下記のような結果を見られます。
私 名詞
の 動詞
名前 名詞
は 動詞
スースー 名詞
です 助動詞
Mecab は想定通り動いているようです。

Python で Mecab に新しい言葉を追加する方法
Mecab へ新しく言葉を追加する方法は二つあります。
- システム辞書への追加
- ユーザ辞書への追加
Mecab ドキュメントを見ると、システム辞書への追加の方がユーザ辞書へ追加するよりも解析する速度が早いとのことだったので、今回はシステム辞書へ追加する方法で新しい言葉を追加します。
まずは csv ファイルを作成します。Mecab の辞書で使う csv ファイルのカラムは 13 列あります。
この 13 列で新しい言葉を追加します。
表層形、左文脈ID、右文脈ID、コスト、品詞、品詞細分類1、品詞細分類2、品詞細分類3、活用型、活用形、原形、読み、発音
Mecab では通常、「旅行団体」という言葉は「旅行 名詞、団体 名詞」と二つの言葉で形態素解析されます。この言葉を「旅行団体 名詞」と一つの言葉になるように新しく言葉を追加してみます。
「旅行団体」と合わせて「企業組織」、「学生集団」、「同僚の仲間」、「プロジェクトチーム」の言葉も一つとして認識されるように辞書へ追加します。
下記のコマンドを実行します。
echo "旅行団体" | mecab
echo "企業組織" | mecab
echo "学生集団" | mecab
echo "同僚の仲間" | mecab
echo "プロジェクトチーム" | mecabこちらのキャプチャは辞書へ追加する前の状態です。それぞれ複数の言葉に分けられていることがわかります。
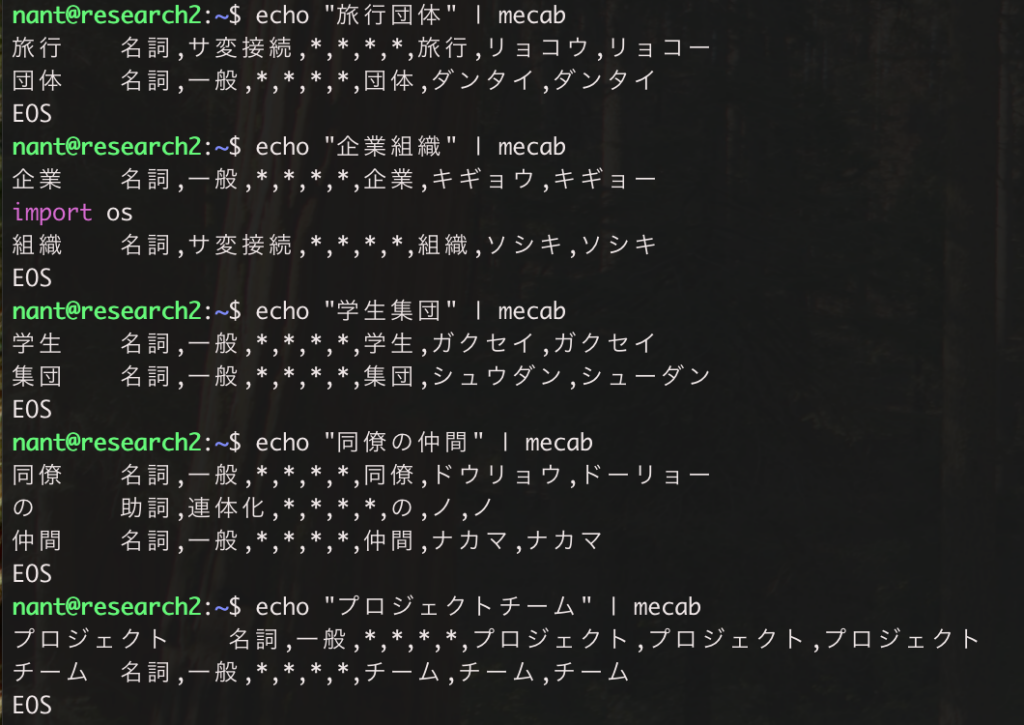
新しい言葉を csv ファイルで作成するのに、言葉 1 個、2 個程度であれば一つ一つ作成するので問題ないですが、追加したい言葉が 100 個ですとかそれ以上ある場合は限界があります。
そこで、今回は python で csv ファイルを作成してみます。
下記のコマンドを実行します。
mkdir mecab_blog
cd mecab_blog
rye init . --min-py 3.11 --no-pin --private --virtual
rye sync
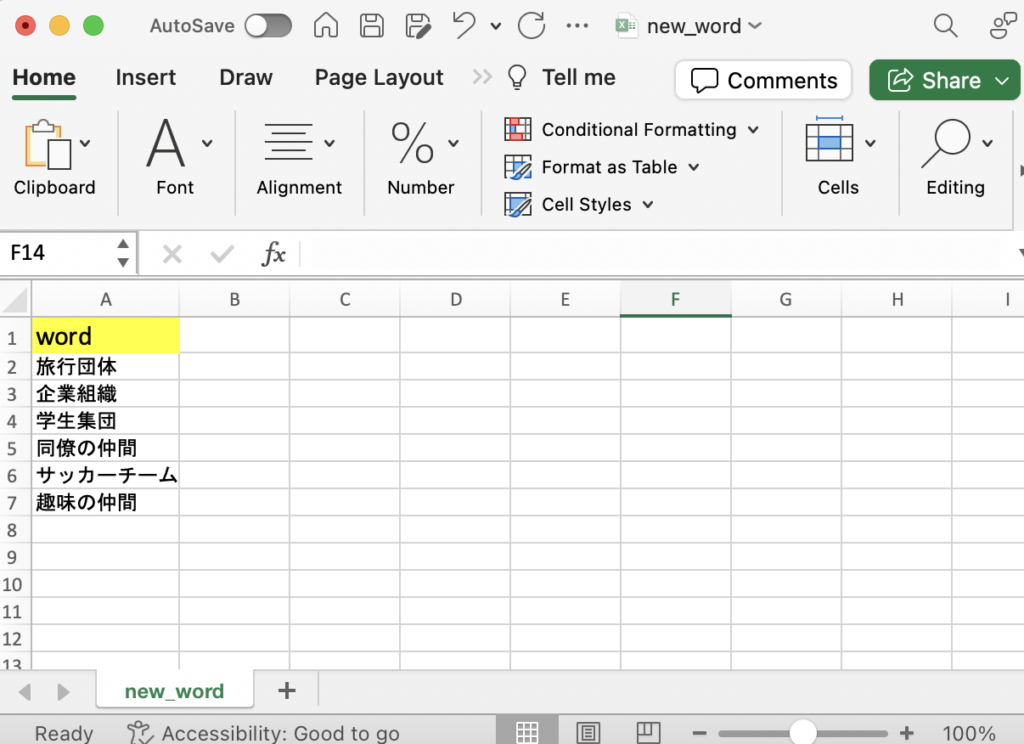
touch new_word.pyMecab の辞書に入れたい言葉を excel ファイルに入れます。
例:new_word.xlsx ファイルに下記のように言葉を記入します。
new_word.py のファイルに下記のコードを入れてください。left_context_id と right_context_id を固定で 1285 と cost を-3150 で固定で入れます。この固定の left_context_id、right_context_id、cost についてはまたの機会に詳しく説明できればと思います。
import pandas as pd
import typer
import pykakasi
app = typer.Typer()
@app.command()
def main():
df = pd.read_excel(r"../new_word.xlsx",sheet_name=['new_word'])
df = pd.concat(df, axis=0, ignore_index=True)
data_list = []
for index, row in df.iterrows():
print(row['word'])
#漢字とひらがなをカタカナに変更するため pykakasi を使用
kks = pykakasi.kakasi()
japan_word_convert = kks.convert(row['word'])
japan_word_kana = ''.join([entry['kana'] for entry in japan_word_convert])
#mecab の 13 列に言葉を追加
data_list.append(
{
'word': row['word'],
'left_context_id': 1285,
'right_context_id': 1285,
'cost': -3150,
'speech': "名詞",
'subclassification_1': "*",
'subclassification_2': "*",
'subclassification_3': "*",
'utilization_type': "*",
'conjugation_form': "*",
'original_form': row['word'],
'reading': japan_word_kana,
'pronunciation': japan_word_kana,
}
)
pd_data = pd.DataFrame(data_list)
if not pd_data.empty:
pd_data.to_csv('new_word.csv', index=False, header=None)
else:
print("DataFrame is empty.")
print("count data",len(pd_data))
if __name__ == "__main__":
app()rye add pandas
rye add typer
rye add pykakasi
rye add openpyxlpython script を実行して csv ファイルを出力します。
rye run python new_word.pypython ファイルを実行すると、このような csv ファイルが出力されます。
nant@research2:~/mecab_blog$ cat new_word.csv
旅行団体,1285,1285,-3150,名詞,*,*,*,*,*,旅行団体,リョコウダンカラダ,リョコウダンカラダ
企業組織,1285,1285,-3150,名詞,*,*,*,*,*,企業組織,キギョウソシキ,キギョウソシキ
学生集団,1285,1285,-3150,名詞,*,*,*,*,*,学生集団,ガクセイシュウダン,ガクセイシュウダン
同僚の仲間,1285,1285,-3150,名詞,*,*,*,*,*,同僚の仲間,ドウリョウノナカマ,ドウリョウノナカマ
サッカーチーム,1285,1285,-3150,名詞,*,*,*,*,*,サッカーチーム,サッカーチーム,サッカーチーム
趣味の仲間,1285,1285,-3150,名詞,*,*,*,*,*,趣味の仲間,シュミノナカマ,シュミノナカマこの csv ファイルを Mecab の ipa 辞書へ入れます。
Mecab ipa は EUC で動いているので、さきほどの csv ファイルを UTF8 から EUC に変更します。
下記のコマンドを実行します。
iconv -f UTF-8 -t EUC-JP -o new_word_euc.csv new_word.csvnew_word_euc.csv の EUC ファイルを出力します。
この EUC ファイルを、先ほど作成した mecab_source の中にある mecab-ipadic-2.7.0-20070801 へ入れます。
nant@research2:~/mecab_source/mecab-ipadic-2.7.0-20070801$ ls
AUTHORS Filler.csv Noun.adverbal.csv Noun.place.csv RESULT config.log left-id.def right-id.def
Adj.csv INSTALL Noun.csv Noun.proper.csv Suffix.csv config.status matrix.bin sys.dic
Adnominal.csv Interjection.csv Noun.demonst.csv Noun.verbal.csv Symbol.csv config.sub matrix.def unk.def
Adverb.csv Makefile Noun.nai.csv Others.csv Verb.csv configure missing unk.dic
Auxil.csv Makefile.am Noun.name.csv Postp-col.csv aclocal.m4 configure.in mkinstalldirs
COPYING Makefile.in Noun.number.csv Postp.csv char.bin dicrc new_word_euc.csv
ChangeLog NEWS Noun.org.csv Prefix.csv char.def feature.def pos-id.def
Conjunction.csv Noun.adjv.csv Noun.others.csv README config.guess install-sh rewrite.defnew_word_euc.csv ファイルを mecab-ipadic-2.7.0-20070801 へ入れた後に Mecab ipa 辞書を再度実行します。
下記のコマンドを実行します。
sudo $(mecab-config --libexecdir)/mecab-dict-index -f euc-jp -t utf8ターミナルで以下のように見られます。先ほどの new_word_euc.csv ファイルが入っていることがわかります。
nant@research2:~/mecab_source/mecab-ipadic-2.7.0-20070801$ sudo $(mecab-config --libexecdir)/mecab-dict-index -f euc-jp -t utf8
reading ./unk.def ... 40
emitting double-array: 100% |###########################################|
./model.def is not found. skipped.
reading ./Auxil.csv ... 199
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
reading ./new_word_euc.csv ... 6
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
reading ./Noun.demonst.csv ... 120
emitting double-array: 100% |###########################################|
reading ./matrix.def ... 1316x1316
emitting matrix : 100% |###########################################|
done!Mecab ipa で新しい言葉を csv ファイルで追加した後に、再度 Mecab ipa をインストールします。
下記のコマンドを実行します。
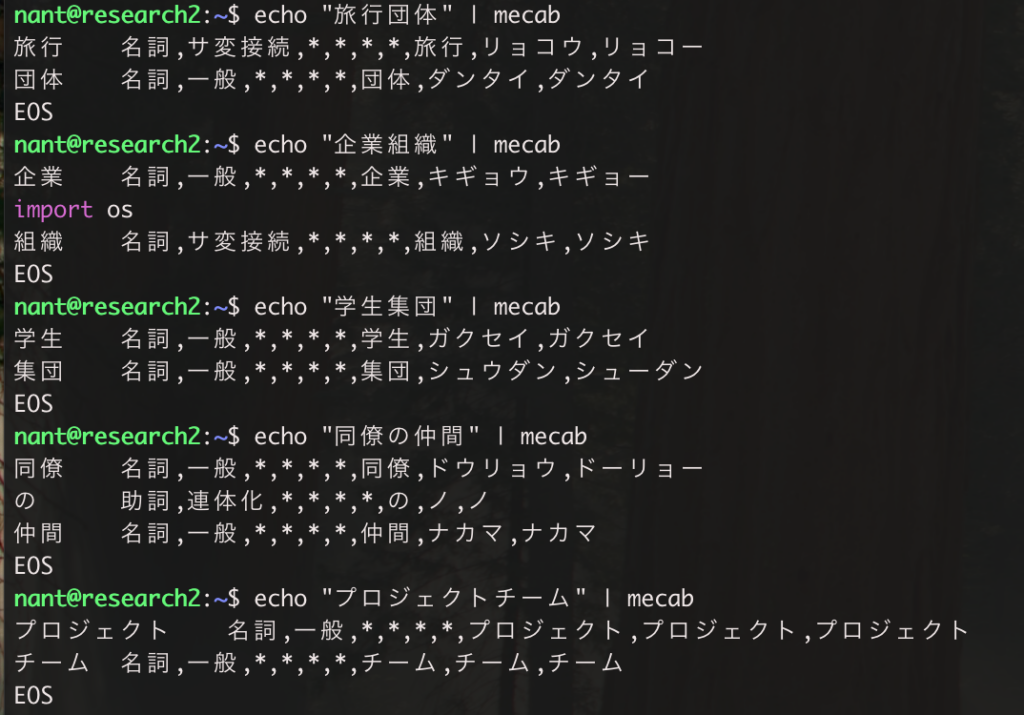
sudo make install新しい言葉を追加する前に Mecab を実行したら「旅行団体』は二つの言葉になります。以下のような実行結果になります。
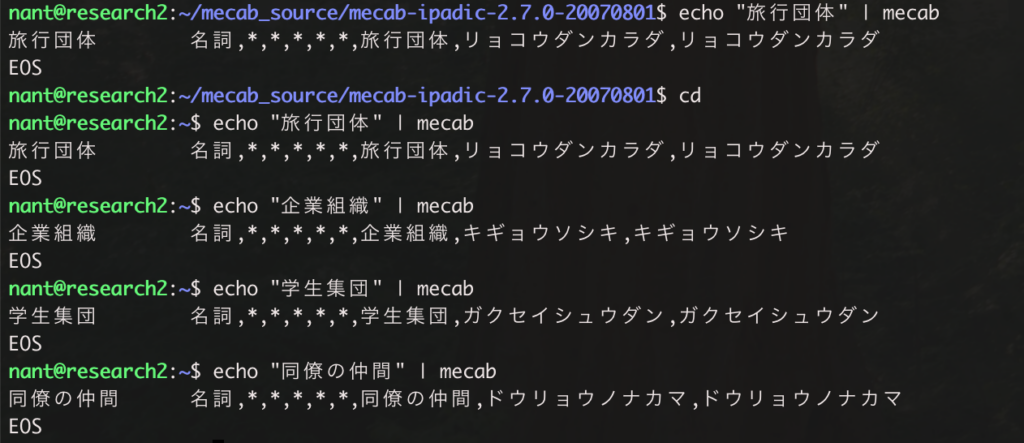
新しい言葉を追加してから Mecab を実行すると一つの言葉として認識されました。以下のような結果になります。
Mecab 辞書の csv ファイルにカラムを追加する方法
Mecab の辞書の csv ファイルには 13 のカラムがありますが、さらに追加することも出来ます。
ここでは、13 列から 15 列へ増やしてみます。
new_word_flag 列と remark の列を追加します。
new_word.py ファイルへ下記のコードを入れてください。
import pandas as pd
import typer
import pykakasi
app = typer.Typer()
@app.command()
def main():
df = pd.read_excel(r"../new_word.xlsx",sheet_name=['new_word'])
df = pd.concat(df, axis=0, ignore_index=True)
data_list = []
for index, row in df.iterrows():
print(row['word'])
#漢字とひらがなをカタカナに変更するため pykakasi を使用
kks = pykakasi.kakasi()
japan_word_convert = kks.convert(row['word'])
japan_word_kana = ''.join([entry['kana'] for entry in japan_word_convert])
#mecab の 13 列に新規言葉と新規列追加
data_list.append(
{
'word': row['word'],
'left_context_id': 1285,
'right_context_id': 1285,
'cost': -3150,
'speech': "名詞",
'subclassification_1': "*",
'subclassification_2': "*",
'subclassification_3': "*",
'utilization_type': "*",
'conjugation_form': "*",
'original_form': row['word'],
'reading': japan_word_kana,
'pronunciation': japan_word_kana,
'new_word_flag': 1,
'remark':"新しい単語",
}
)
pd_data = pd.DataFrame(data_list)
if not pd_data.empty:
pd_data.to_csv('new_word.csv', index=False, header=None)
else:
print("DataFrame is empty. Nothing to write to the database.")
print("count data",len(pd_data))
if __name__ == "__main__":
app()以下のコマンドを実行します。
rye run python new_word.py新しい言葉を追加する時と同じコマンドを再度実行します。
python script で実行して出力された csv ファイルは UTF-8 なので、下記のコマンドで EUC に変更します。
iconv -f UTF-8 -t EUC-JP -o new_word_euc.csv new_word.csvEUC で変更した new_word_euc.csv ファイルを mecab-ipadic-2.7.0-20070801 へ入れた後に、Mecab ipa 辞書を再度実行してインストールします。
下記のコマンドを実行します。
sudo $(mecab-config --libexecdir)/mecab-dict-index -f euc-jp -t utf8
sudo make installこちらは二列を追加する前の結果です。

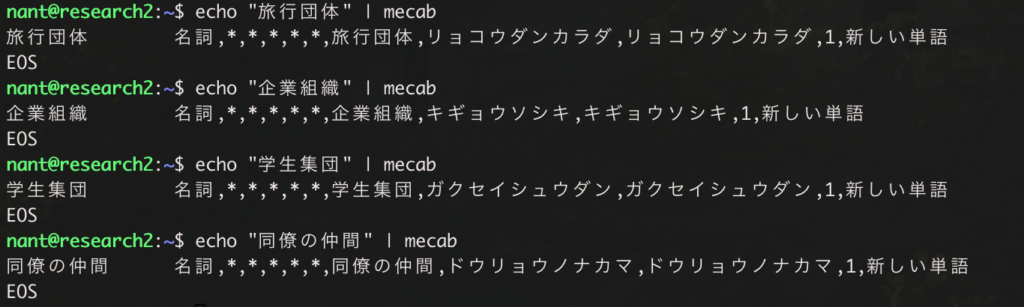
二列を追加した後、追加した列の ‘new_word_flag’: 1 と ‘remark’:” 新しい単語” も表示されました。
下記のコマンドを実行します。
echo "年末年始祝日にチームのメンバーと一緒に旅行団体で行きますか?" | mecab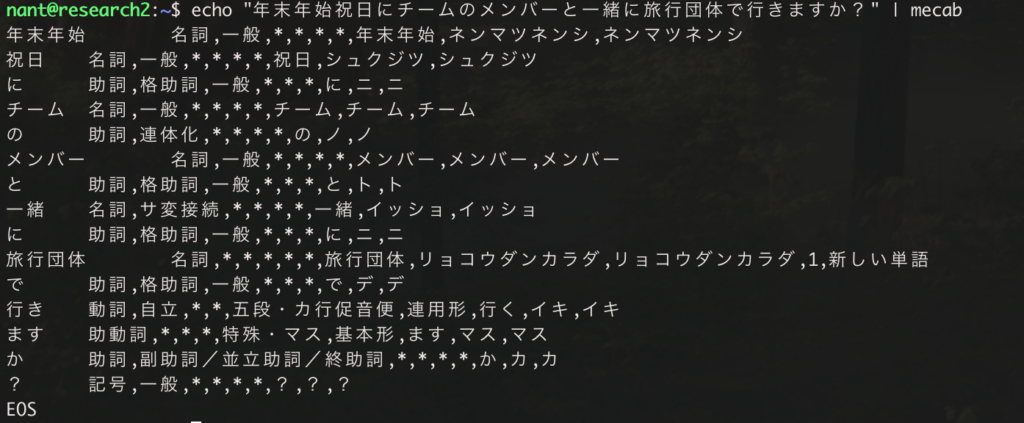
先ほど追加した「旅行団体」の言葉には列も追加しているので ‘new_word_flag’: 1、’remark’:”新しい単語” の項目も表示されています。
それ以外の言葉については、Mecab の基本データのまま表示されていることがわかります。
Mecab 参照リンク https://taku910.github.io/mecab/dic.html
まとめ
今回のブログではこちらの内容について書いてきました。
- Mecab のインストール方法
- Mecab のシステム辞書へ言葉を追加する方法
- Mecab のシステム辞書へ列を追加する方法
続編として、Mecab と Qdrant の連携方法をまとめています。以下のようなことをまとめているので、気になった方はぜひご覧ください。
- 追加した言葉と追加した列がどのように使われているかを確認する
- 新しい言葉を Mecab で取得して、ベクトルデータベースで検索する方法

Mecab に関する情報はまだまだ少ないので、この記事が Mecab を学んでる人の助けになれば嬉しいです。
最後に
この他にも、Qdrant(ベクトルデータベース)についてのブログも書いているので、興味のある方はぜひこちらもご覧ください。




