

目次
こんにちは、mhosoya です。
今回は、 RAG とはどういう仕組みでできているのか?を構築しながら理解していきたいと思います。
自分は Google Cloud の AI Applications (旧 Vertex AI Agent Builder) というマネージドな RAGサービス を使用した開発経験はありますが、自分で RAG を構築したことがないです。
そのため、ローカルLLM を使った RAG を構築し、理解を深めていきたいと思います。
初めての構築で、モジュール を差し替えたりなどが発生しそうなので、差し替えが容易に行えるような構成で作っていこうと思います。
処理フロー
[offline] ドキュメントの前処理とベクトルデータ登録

- PDF から テキスト を抽出する
- テキスト を チャンク 分割 する
- ベクトル化する
- ベクトルDB に保存する
[online] ユーザーの質問に対する回答生成フロー

- 質問を受け取る
- 質問を ベクトル化 する
- ベクトルDB から類似検索する
- LLM に渡して回答を生成する
Qdrant and LlamaIndex — A new way to keep your Q&A systems up-to-date
技術選定
PDF から テキスト を抽出
- 特に機能面は求めていないので、シンプル重視
- 根拠データのページに飛ばすなら、ページ情報も取得できた方が良く、これは対応しています
チャンク分割
- 構造認識チャンク分割(RecursiveCharacterTextSplitter)
- 自然言語の構造を意識して再帰的に分割できて、可能な限り意味のまとまりを保ったまま指定の長さに収まるよう分割できる
埋め込みモデル(テキストをベクトルに変換するモデル)
- 日本語対応
- 軽量で高速
LLM
- このモデルは Meta の Llama 2 をベースに ELYZA が日本語対応のチューニングしたものです
- 研究および商業目的での利用が可能
- 軽さと精度を求めたいので q4_K_M 版
- GPT生成統合フォーマット(GGUF) とは、大規模言語モデル(LLM)の推論モデルを高速かつ効率的に読み書きできるよう設計されたバイナリファイル形式
Metaの「Llama 2」をベースとした商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を公開しました
ベクトル化
- 意味の近さを反映したい
- model.encode() だけでベクトル化できたり、扱いやすい。
ベクトルDB
- 手軽に試したい
- パフォーマンスも考慮したい
事前準備
1. プロジェクト作成
プロジェクト名はとりあえず local-llm-rag としておきます。
今回は、 uv を使用していきたいと思います。
uv init local-llm-rag --python 3.13 && cd local-llm-rag2. 仮想環境作成 & 有効化
uv venv
source .venv/bin/activate2. パッケージをインストール
必要なパッケージを追加していきます。
uv add pdfplumber sentence-transformers qdrant-client langchain3. llama-cpp-python を追加
Metal(Metal Performance Shaders) を使用して追加します。
CMAKE_ARGS="-DGGML_METAL=on" uv add llama-cpp-python --force-reinstall --no-cache-dirhttps://github.com/abetlen/llama-cpp-python
4. LLM をダウンロード
mkdir models
curl -L -o ./models/ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf \
https://huggingface.co/mmnga/ELYZA-japanese-Llama-2-7b-fast-instruct-gguf/resolve/main/ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf5. データを用意する
Wikipedia「インターネットの歴史」を使用したいと思います。
Wikipedia「インターネットの歴史」 > ツール > PDF形式でダウンロード でPDFをダウンロードします。
./resources/internet-history.pdf にリネームして移動しておきます。
※本記事では、Wikipedia「インターネットの歴史」記事(https://ja.wikipedia.org/wiki/インターネットの歴史)を元に、一部の質問と回答を生成しています。
当該コンテンツは、CC BY-SA 3.0 ライセンスに従って使用しています。実装 – ドキュメント の前処理と ベクトルデータ 登録
抽象クラスを介すようにして、疎結合に作っていきたいと思います。
1. PDF から テキスト を抽出する

pdfplumber を使用して、PDF を読み込んでテキストを取得します。
pdf_loader.py (最終的なコードまとめ)
import pdfplumber
class PDFLoader:
@staticmethod
def load(pdf_file_path: str) -> str:
with pdfplumber.open(pdf_file_path) as pdf:
return "".join([page.extract_text() or "" for page in pdf.pages])呼び出し元
text = PDFLoader.load(PDF_FILE_PATH)2. テキスト を チャンク分割
拡張しやすいように Factory でテキストを分割するための実装クラスを生成し、抽象クラスで返すようにします。
300文字で分割していこうと思います。
RAGのチャンク分割で検索精度に革命を!エンジニアのキャリアを加速させる最適化技術
固定長チャンク分割 の実装もありますが、これは回答にどのくらい差があるかを実際に試してみたので残っています。
今回の構成では差し替えは、容易なので実際に試してみると良いかと思います。
自分が試したところ、回答の情報量に差がありました。
また、固定チャンク分割だと内容が少しおかしかったり、誤字(プロトコルがプラトコルになっていた)が発生したりしていました。
意味のまとまりをできる限り保つことで、ベクトルデータベースから取得する関連情報をある程度精度高く取得できそうです。
text_splitter.py (最終的なコードまとめ)
from abc import ABC, abstractmethod
from enum import Enum
from langchain.text_splitter import RecursiveCharacterTextSplitter
class TextSplitterType(Enum):
"""
テキスト分割のタイプ
"""
FIXED_LENGTH = 1
RECURSIVE_CHARACTER = 2
class TextSplitter(ABC):
"""
テキストを分割するための抽象クラス
"""
@abstractmethod
def split_text(self, text: str) -> list[str]:
raise NotImplementedError("This method should be overridden by subclasses.")
class FixedLengthTextSplitter(TextSplitter):
"""
固定長のテキストチャンクに分割するクラス
"""
def __init__(self, chunk_size: int) -> None:
self.splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
def split_text(self, text) -> list[str]:
return self.splitter.split_text(text)
class LangchainRecursiveCharacterTextSplitter(TextSplitter):
"""
構造認識チャンク分割
"""
def __init__(self, chunk_size: int) -> None:
self.splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=0,
separators=["。", "\n\n", "\n", "、", ""],
)
def split_text(self, text) -> list[str]:
return self.splitter.split_text(text)
class TextSplitterFactory:
@staticmethod
def create(text_splitter_type: TextSplitterType, chunk_size: int) -> TextSplitter:
match text_splitter_type:
case TextSplitterType.FIXED_LENGTH:
return FixedLengthTextSplitter(chunk_size)
case TextSplitterType.RECURSIVE_CHARACTER:
return LangchainRecursiveCharacterTextSplitter(chunk_size)
case _:
raise ValueError(f"Unsupported text splitter type: {text_splitter_type}")呼び出し元
text_splitter = TextSplitterFactory.create(
text_splitter_type=TextSplitterType.RECURSIVE_CHARACTER, chunk_size=CHUNK_SIZE
)
chunks = text_splitter.split_text(text)3. ベクトル化する
SentenceTransformer を使用して、チャンク分割したテキストをベクトル化していきます。
また、同様に抽象化して、実装クラスを Factory から生成するようにします。
text_vectorizer.py (最終的なコードまとめ)
from abc import ABC, abstractmethod
from enum import Enum
import numpy
from sentence_transformers import SentenceTransformer
class TextVectorizerType(Enum):
SENTENCE = 1
class TextVectorizer(ABC):
"""
テキストをベクトル化するための抽象クラス
"""
def __init__(self, model_name: str) -> None:
self.embedder = SentenceTransformer(model_name)
@abstractmethod
def encode(self, chunks: list[str]) -> numpy.ndarray:
raise NotImplementedError("This method should be overridden by subclasses.")
class SentenceTextVectorizer(TextVectorizer):
"""
SentenceTransformerを使用してテキストをベクトル化するクラス
"""
def __init__(self, model_name: str) -> None:
self.embedder = SentenceTransformer(model_name)
def encode(self, chunks: list[str]) -> numpy.ndarray:
return self.embedder.encode(chunks)
class TextVectorizerFactory:
@staticmethod
def create(vectorizer_type: TextVectorizerType, model_name: str) -> TextVectorizer:
match vectorizer_type:
case TextVectorizerType.SENTENCE:
return SentenceTextVectorizer(model_name)
case _:
raise ValueError(f"Unsupported text vectorizer type: {vectorizer_type}")呼び出し元
text_vectorizer = TextVectorizerFactory.create(
vectorizer_type=TextVectorizerType.SENTENCE,
model_name=EMBEDDING_MODEL_NAME_OR_PATH,
)
vectors = text_vectorizer.encode(chunks)4. ベクトルDB に保存する
QdrantClient を使用して、ベクトル化したデータを Qdrant に登録していきます。
Collection の作成
qdrant_client.recreate_collection を使用して、Collection を作成します。
- size
- 1つのベクトルが持つ次元数を指定
- これは特徴量の数に該当
- distance
- 距離の計算方法
- 自然言語処理では COSINE が一般的
def recreate(self, vectors: list[float], collection_name: str) -> None:
self.qdrant_client.recreate_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=len(vectors[0]), distance=Distance.COSINE),
)ベクトルデータの登録
qdrant_client.upsert で ベクトルデータ を登録していきます。
回答時に、文書の該当ページも返したい場合は、 id に組み込むか payload にページ情報を持たせると良さそうに見えます。
ちなみに今回は、該当ページを開いたりしないので対応はしません。
def upsert(
self, chunks: list[str], vectors: list[float], doc_id: str, collection_name: str
) -> None:
points = [
PointStruct(
id=str(uuid.uuid4()),
vector=vec,
payload={"text": chunk, "doc_id": doc_id},
)
for chunk, vec in zip(chunks, vectors)
]
self.qdrant_client.upsert(collection_name=collection_name, points=points)vector_db_client.py (最終的なコードまとめ)
import uuid
from abc import ABC, abstractmethod
from enum import Enum
from qdrant_client import QdrantClient
from qdrant_client.http.models import (
Distance,
PointStruct,
VectorParams,
)
class VectorDatabaseType(Enum):
QDRANT = 1
class VectorDatabaseRepository(ABC):
@abstractmethod
def recreate(self, vectors: list[float], collection_name: str) -> None:
raise NotImplementedError("This method should be overridden by subclasses.")
@abstractmethod
def upsert(
self, chunks: list[str], vectors: list[float], doc_id: str, collection_name: str
) -> None:
raise NotImplementedError("This method should be overridden by subclasses.")
@abstractmethod
# TODO: parameter object pattern
def search(
self,
query_vectors: list[float],
collection_name: str,
min_score: float,
) -> list[str]:
raise NotImplementedError("This method should be overridden by subclasses.")
class QdrantRepository(VectorDatabaseRepository):
def __init__(self, host: str, port: int) -> None:
self.qdrant_client = QdrantClient(host=host, port=port)
def recreate(self, vectors: list[float], collection_name: str) -> None:
self.qdrant_client.recreate_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=len(vectors[0]), distance=Distance.COSINE),
)
def upsert(
self, chunks: list[str], vectors: list[float], doc_id: str, collection_name: str
) -> None:
points = [
PointStruct(
id=str(uuid.uuid4()),
vector=vec,
payload={"text": chunk, "doc_id": doc_id},
)
for chunk, vec in zip(chunks, vectors)
]
self.qdrant_client.upsert(collection_name=collection_name, points=points)
def search(
self,
query_vectors: list[float],
collection_name: str,
min_score: float,
) -> list[str]:
results = self.qdrant_client.query_points(
collection_name=collection_name,
query=query_vectors,
with_payload=True,
)
sorted_results = sorted(results.points, key=lambda r: r.score, reverse=True)
return [r.payload["text"] for r in sorted_results if r.score >= min_score]
class VectorDatabaseRepositoryFactory:
@staticmethod
def create(host="localhost", port=6333) -> VectorDatabaseRepository:
return QdrantRepository(host=host, port=port)ここでは、def search は必要ないですが、この後にでてくる 実装 – ユーザーの質問に対する回答生成 で必要になります。
pdf_to_vector_db_runner.py (最終的なコードまとめ)
from pdf_loader import PDFLoader
from text_splitter import TextSplitterFactory, TextSplitterType
from text_vectorizer import TextVectorizerFactory, TextVectorizerType
from vector_db_client import VectorDatabaseRepositoryFactory
PDF_FILE_PATH = "resources/internet-history.pdf"
EMBEDDING_MODEL_NAME_OR_PATH = "intfloat/multilingual-e5-small"
COLLECTION_NAME = "pdf_chunks"
CHUNK_SIZE = 300
def execute() -> None:
# load text from PDF
text = PDFLoader.load(PDF_FILE_PATH)
text_splitter = TextSplitterFactory.create(
text_splitter_type=TextSplitterType.RECURSIVE_CHARACTER, chunk_size=CHUNK_SIZE
)
# split text into chunks
chunks = text_splitter.split_text(text)
text_vectorizer = TextVectorizerFactory.create(
vectorizer_type=TextVectorizerType.SENTENCE,
model_name=EMBEDDING_MODEL_NAME_OR_PATH,
)
# vectorize the text chunks
vectors = text_vectorizer.encode(chunks)
vector_db_repository = VectorDatabaseRepositoryFactory.create()
# recreate the collection
vector_db_repository.recreate(vectors=vectors, collection_name=COLLECTION_NAME)
# upsert the vectors
vector_db_repository.upsert(
chunks=chunks,
vectors=vectors,
doc_id=PDF_FILE_PATH,
collection_name=COLLECTION_NAME,
)
if __name__ == "__main__":
execute()これで実装は完了したので、実際に実行して確認したいと思います。
実行 – ドキュメント の前処理と ベクトルデータ 登録
Qdrant を Docker で起動する
docker run -d \
-p 6333:6333 \
--name qdrant \
qdrant/qdrantQdrant にアクセスして、起動しているかを確認します。
http://localhost:6333/dashboard
Qdrant にPDFから読み込んだ テキスト を ベクトルデータ にして登録する
pdf_to_vector_db_runner.py を実行して、 Qdrant にベクトルデータを登録していきます。
uv run python pdf_to_vector_db_runner.pyCollection が作成されているのを確認します。
http://localhost:6333/dashboard
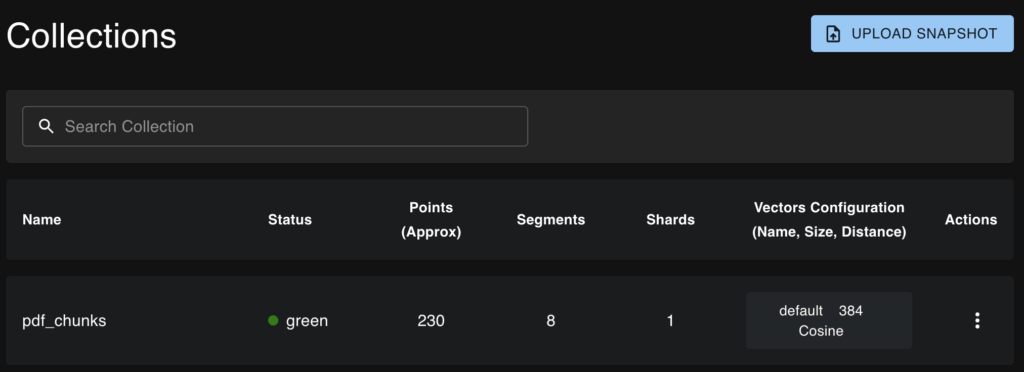
intfloat/multilingual-e5-small は 埋め込みサイズが384 との記載があるので、Qdrant に正しく Collection が作成されていそうです。
次にデータを確認していきたいと思います。
http://localhost:6333/dashboard#/collections/pdf_chunks
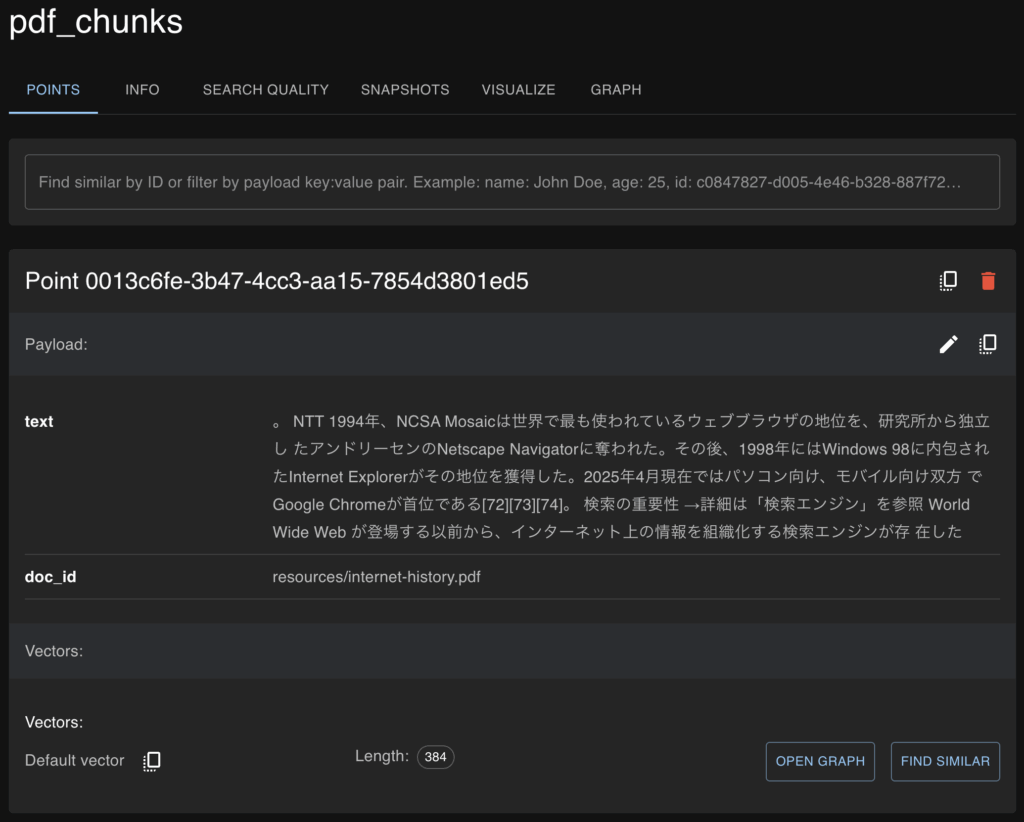
文頭が「。」になっています。
「。」で セパレート するように指定しましたが、果たしてこれでいいのか?w
文末が「。」になるかと思っていました。
これで ドキュメント の前処理と ベクトルデータ 登録 が完了しました。
次に LLM にプロンプトで指示して回答を生成したいと思います。
実装 – ユーザーの質問に対する回答生成
1. 質問を受け取る

インタラクティブに質問を受け取るようにします。
while True:
query = input("質問をどうぞ(qで終了): ")
if query.lower() == "q":
break
...2. 質問を ベクトル化 する
テキストをベクトル化するのは ドキュメントの前処理とベクトルデータ登録#ベクトル化する で実装済みです。
text_vectorizer = TextVectorizerFactory.create(
vectorizer_type=TextVectorizerType.SENTENCE,
model_name=EMBEDDING_MODEL_NAME_OR_PATH,
)
...
query_vectors = text_vectorizer.encode([query])[0].tolist()3. ベクトルDB から類似検索する
vector_db_client.py の def search はドキュメントの前処理とベクトルデータ登録#ベクトルDB に保存する で実装済みです。
from qdrant_client import QdrantClient
...
def search(
self,
query_vectors: list[float],
collection_name: str,
min_score: float,
) -> list[str]:
results = self.qdrant_client.query_points(
collection_name=collection_name,
query=query_vectors,
with_payload=True,
)
...query_points で類似検索で payload 付きで取得します。
- with_payload
- payload に テキストを入れているので、True にして取得します。
- query_filter
- 今回は使用していませんが、絞り込みをしたい場合に使用します。
精度を高めるために、score が特定の値以上のものだけにしています。
Distance.COSINE であれば、score は -1 ~ 1 で大きいほど類似しているということになります。
sorted_results = sorted(results.points, key=lambda r: r.score, reverse=True)
return [r.payload["text"] for r in sorted_results if r.score >= min_score]vector_db_repository = VectorDatabaseRepositoryFactory.create()
...
contexts = vector_db_repository.search(
query_vectors=query_vectors,
collection_name=COLLECTION_NAME,
min_score=MIN_SCORE,
)4. LLM に渡して回答を生成する
まずは結果としてこうなりました。
llm_client.py (最終的なコードまとめ)
from abc import ABC, abstractmethod
from enum import Enum
from llama_cpp import Llama
class LLMClientType(Enum):
LLAMA_CPP = 1
class LLMClient(ABC):
"""
抽象クラス: LLMクライアントのインターフェース
"""
@abstractmethod
def generate_answer(self, contexts: list[str], question: str) -> str:
"""
質問に対する回答を生成する
"""
raise NotImplementedError("This method should be overridden by subclasses.")
class LlamaCppClient(LLMClient):
"""
LlamaCppを使用して質問に対する回答を生成するクライアント
"""
def __init__(self, model_path: str) -> None:
self.llm = Llama(
model_path=model_path,
n_ctx=2048,
n_threads=8,
n_gpu_layers=-1,
)
def generate_answer(self, contexts: list[str], question: str) -> str:
"""
質問に対する回答を生成するメソッド
"""
if not contexts:
return "この質問に関する情報は資料に含まれていませんでした。"
combined_context = " ".join(contexts)
prompt = (
"あなたは、以下の文脈内に情報がある場合のみ回答してください。\n"
"文脈にないことについては「情報が見つかりません」と答えてください。\n\n"
"### 文脈:\n"
f"{combined_context}\n\n"
"### 質問:\n"
f"{question}\n\n"
"### 回答:\n"
)
response = self.llm(prompt, max_tokens=512, stop=["###"])
return response["choices"][0]["text"].strip()
class LLMClientFactory:
@staticmethod
def create(llm_client_type: LLMClientType, model_path: str) -> LLMClient:
match llm_client_type:
case LLMClientType.LLAMA_CPP:
return LlamaCppClient(model_path=model_path)
case _:
raise ValueError(f"Unsupported LLM client type: {llm_client_type}")- n_ctx
- 1回の推論で扱えるトークン数
- 小さすぎると?
- エラーもしくは予期しない挙動になりそう。
- エラーにならない場合、プロンプトが一部削除されそうなので、おかしな回答を生成しそう。
- モデルごとに限界値があるので、確認するのが良い。
- Llama を生成すると、metadata が出力されます(verbose のデフォルト値はTrue)。そこから確認ができます。
- エラーもしくは予期しない挙動になりそう。
- 大きすぎると?
- 大きい方が良さそうだが、メモリを逼迫するため、クラッシュなどに繋がりそう
- n_gpu_layers
- GPU にオフロードするレイヤーを指定します。-1 を指定することで可能な限りすべてのレイヤーが GPU で処理されます。
- 高速化とメモリ使用量のトレードオフになります。
- n_threads
- 使用する CPU スレッド数
- 自分のPCは 8コア なので 8を指定しました
llama-cpp-python#API Reference
ハルシネーションの緩和
関連するデータが取得できなければ、LLM を呼ばずに返すようにします。
このような空チェックを入れて、ハルシネーションを緩和します。
if not contexts:
return "この質問に関する情報は資料に含まれていませんでした。"完全に防止できるものではないですが、プロンプトでも指示して緩和をします。
文脈にないことについては「情報が見つかりません」と答えてください。実行用のスクリプトはこうなりました。
rag_qa_runner.py (最終的なコードまとめ)
import time
from llm_client import LLMClientFactory, LLMClientType
from text_vectorizer import TextVectorizerFactory, TextVectorizerType
from vector_db_client import VectorDatabaseRepositoryFactory
PDF_FILE_PATH = "resources/internet-history.pdf"
EMBEDDING_MODEL_NAME_OR_PATH = "intfloat/multilingual-e5-small"
COLLECTION_NAME = "pdf_chunks"
MODEL_PATH = "./models/ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf"
MIN_SCORE = 0.75
if __name__ == "__main__":
text_vectorizer = TextVectorizerFactory.create(
vectorizer_type=TextVectorizerType.SENTENCE,
model_name=EMBEDDING_MODEL_NAME_OR_PATH,
)
vector_db_repository = VectorDatabaseRepositoryFactory.create()
llm_client = LLMClientFactory.create(LLMClientType.LLAMA_CPP, MODEL_PATH)
while True:
print("##########")
query = input("質問をどうぞ(qで終了): ")
if query.lower() == "q":
break
start_time = time.time()
query_vectors = text_vectorizer.encode([query])[0].tolist()
contexts = vector_db_repository.search(
query_vectors=query_vectors,
collection_name=COLLECTION_NAME,
min_score=MIN_SCORE,
)
print(f"関連データ数: {len(contexts)}")
answer = llm_client.generate_answer(contexts=contexts, question=query)
elapsed_time = time.time() - start_time
print(f"回答: {answer}")
print(f"処理時間: {elapsed_time} Sec.")今回の実装では score で降順にソートしているので、MIN_SCORE が小さいと関連データ数が少ない場合におかしな回答を返しそうです。
また、大きいと関連データ数が少なくなるので、調整していくのが良さそうです。
実行 – ユーザーの質問に対する回答生成フロー
rag_qa_runner.py を実行してみます。
uv run python rag_qa_runner.py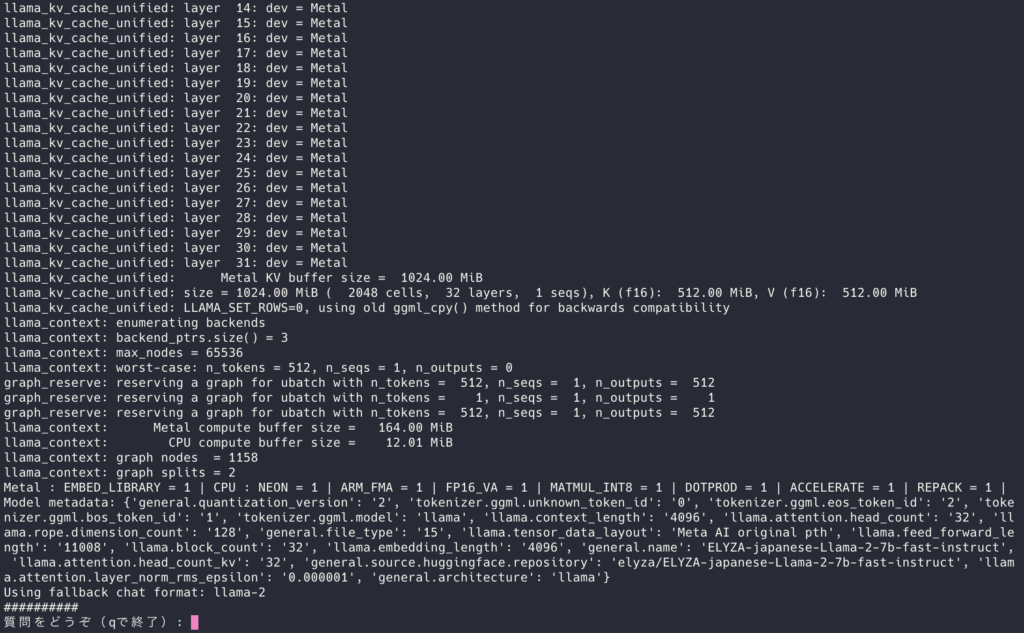
無事、動きました。
metadata が出力されていて、LLM の名前も合っていそう。
では、実際に質問していきたいと思います。
質問をどうぞ(qで終了): インターネットとWWWの違いは?
うん、まぁ合っていそう。回答時間も許容範囲です。
しつこく、何度も何度も聞いてみます。
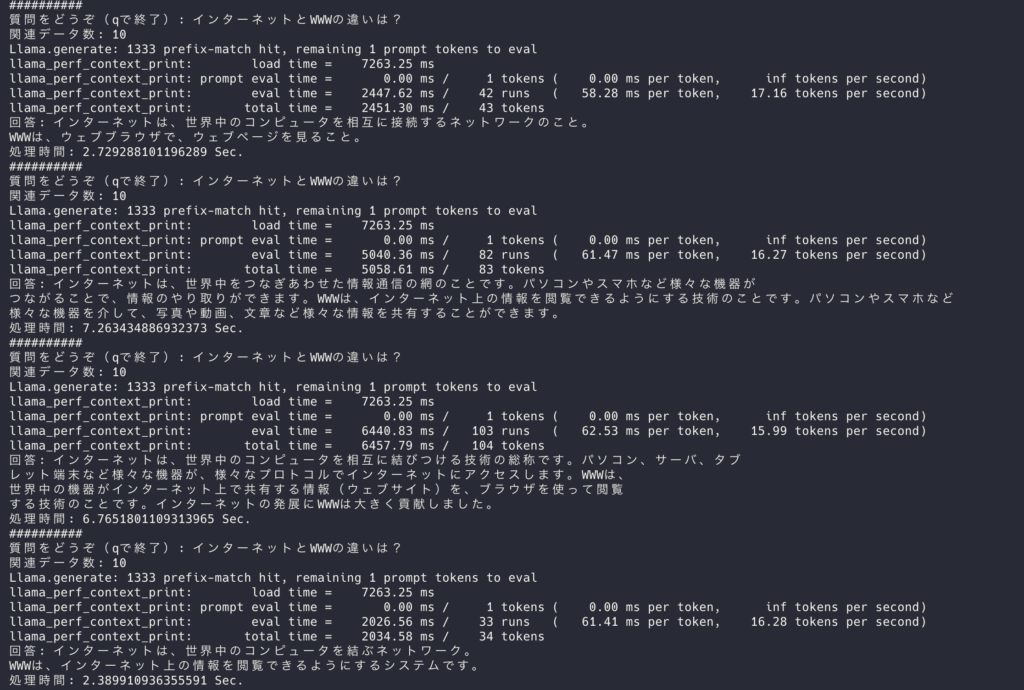
回答がランダムになっていて、毎回変わりますが、どれも正しそうです。
ただし、情報量の差は少し気になります。
回答のランダムをやめるには、temperature を 0 で指定します。
llm_client.py
response = self.llm(prompt, max_tokens=512, stop=["###"], temperature=0)総括
動かすまでは結構、簡単にいけたかなという印象です。
また、ローカルで完結するので、安心して使えそうですし、この速度なら全然使えるかなと思います。
ただ、CPU のみだと結構遅いです。n_gpu_layers を 0 にすると確認できます。(もしかしたら設定やモデルなどを変えることで変わるのかもしれませんが)
あと本来なら、最初に クリーニング や 正規化 などがあった方が良いかと思いますが、その辺は一旦飛ばしています。
今回、ローカルLLM で RAG を構築することで理解が深まったのと、クラウド や SaaS の魅力を思い知らされました。
最終的なコードまとめ
- pdf_loader.py
- text_splitter.py
- text_vectorizer.py
- vector_db_client.py
- llm_client.py
- pdf_to_vector_db_runner.py
- rag_qa_runner.py

