

目次
こんにちは、ilhamhkです!
今回の記事では、SQLのロジック、どうやってLooker Studioの機能で再現するか共有したいと思います。今回は、SQLのWHERE句にあたる「動的なフィルタ」を工夫して実装する方法や、JOINにあたる処理を「データの統合」で再現する方法について解説します。
概要
Looker Studioには、様々なデータソースを取り込む方法が用意されています。 多くの場合、データをすべてそのまま表示するのではなく、グラフで見せたいデータだけに絞り込みたいことがありますよね。
例えば、あるゲーム会社で「先月、新しくゲームを始めたプレイヤーが何人いるか」を集計したいケースを考えてみましょう。
※今回はシンプルにするため、「新規プレイヤー」の定義を「先月プレイしたが、その前の月はプレイしていなかった人」とします。厳密に「過去一度もプレイしたことがない人」を特定するには、過去すべての履歴データと突き合わせる必要がありますが、今回は割愛します。
元となるデータは、各プレイヤーがその月に最初にログインした日時(timestamp)が記録されている、以下のようなテーブルです:
| first_logged_in_per_month | user_id | username | total_play_hour | platform |
| 2025-09-02 9:14:23 | 8394021155 | PlayerOne | 120 | [‘PC Windows’] |
| 2025-09-05 18:30:11 | 1928374650 | GamerGirl_X | 45 | [‘iOS’, ‘PC Windows’] |
| 2025-09-12 21:05:44 | 5501928347 | JohnDoe_123 | 200 | [‘Playstation’] |
| 2025-09-01 14:22:10 | 9918273645 | SpeedyGon | 310 | [‘Android’] |
| … | … | … | … | … |
データがBigQueryなどのデータベースにある場合、データを取り込む際に以下のようなクエリを書くことで解決できます:
SELECT p.user_id, p.username
FROM (
SELECT user_id FROM `player_monthly_data`
WHERE DATE_TRUNC(DATE(first_logged_in_per_month), MONTH) =
DATE_SUB(DATE_TRUNC(CURRENT_DATE(), MONTH), INTERVAL 2 MONTH)
) AS pp -- 2ヶ月前
FULL OUTER JOIN (
SELECT user_id, username FROM `player_monthly_data`
WHERE DATE_TRUNC(DATE(first_logged_in_per_month), MONTH) =
DATE_SUB(DATE_TRUNC(CURRENT_DATE(), MONTH), INTERVAL 1 MONTH)
) AS p -- 先月
ON pp.user_id = p.user_id
WHERE pp.user_id IS NULL
すると、結果はこのようになります:
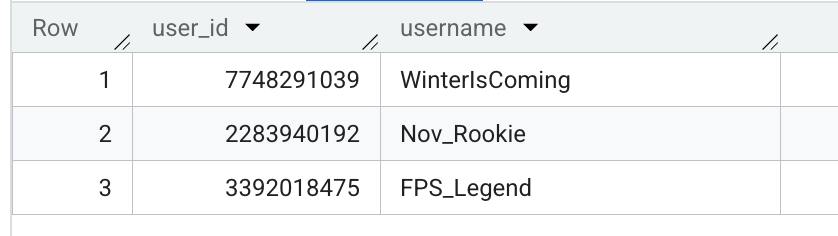
しかし、スプレッドシートなどのデータをデータソースとして利用する際は 一度ファイルをまるごと読み込んだ上で、グラフ作成時などにフィルタをかける場合が多いのではないでしょうか。
クエリを書く場合であれば、DATE_SUB や DATE_TRUNC といった関数を使って「今日から2ヶ月前」を特定することができます。 しかし、Looker Studioの標準の「フィルタ」機能は、こうした計算式を含んだ動的なフィルタリング条件をそのまま表現しづらいことがあります。
そこで、「計算フィールド」を使って動的な値をあらかじめ生成しておくことで、この制限を回避することができます。 今回は、そのデータが「何ヶ月前のものか」を計算するフィールドを作成してみましょう。
クエリのロジックを再現する
データを追加する
まず、データをレポートへ追加します。今回はGoogle スプレッドシートを使います。
追加するファイルを選んだ後、追加するシートも選択します。
テーブルを作成する
Googleスプレッドシートなどのファイルからデータをインポートする場合、通常、インポート可能な最小単位は「シート」となります。 フィルタは、Looker Studioのデータソースを通じてファイルがインポートされた後に適用されます。
まず、データの状態を確認したり調整しやすくするために、データをテーブルとして配置してみましょう。 このテーブルをベースにして、最終的に「先月の新規プレイヤー」を表示させていきます。
テーブルの使用は、あくまで一例に過ぎません。 実際の運用において、この手法は他の種類のチャートや表を作成する際にも利用可能です。
計算フィールドを活用する
「リソース」>「追加済みのデータソースの管理」メニューからデータの編集画面を開き、先ほど追加したファイルの「編集」を押します。
個別のグラフ設定ではなく、ここから編集を行うことで、このフィールドが「テーブルレベル(グラフ単位)」ではなく「データレベル」で実装されます。こうすることで、他のグラフを作成する際にも同じフィールドを使い回せるようになります:

次に、「フィールドを追加」>「計算フィールドを追加」を押してフィールド追加画面を開きます。
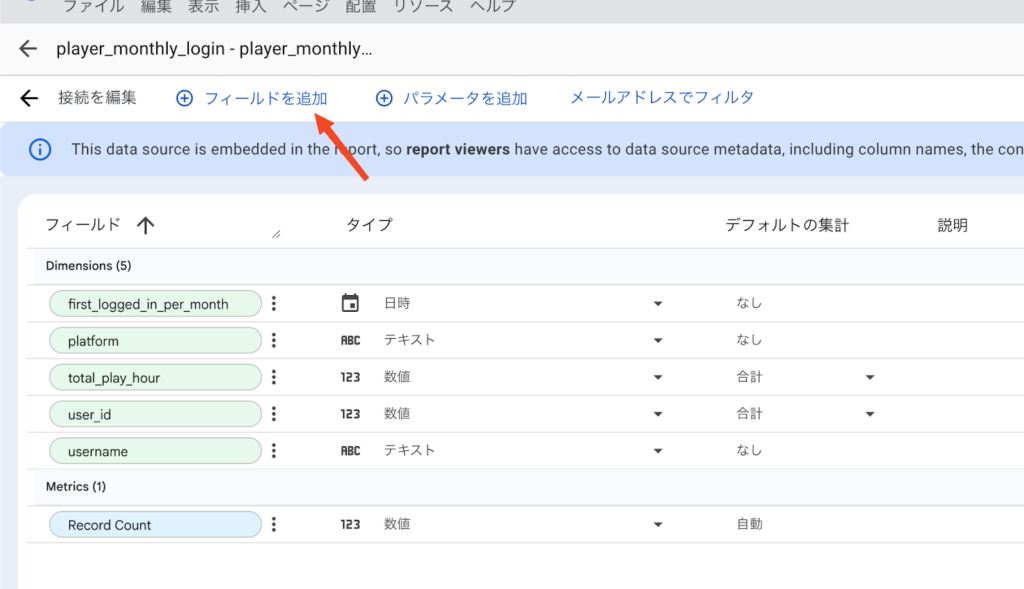
カラム名を month_offset とし、以下の計算式を使って「この行が何ヶ月前に追加されたか」を算出します。 この計算式の意味はシンプルで、「今日(CURRENT_DATE)と、その行のデータが追加された日(first_logged_in_per_month)の間に、何ヶ月(MONTH)の差があるか(DATETIME_DIFF)」を求めています:
DATETIME_DIFF(CURRENT_DATE(), first_logged_in_per_month, MONTH)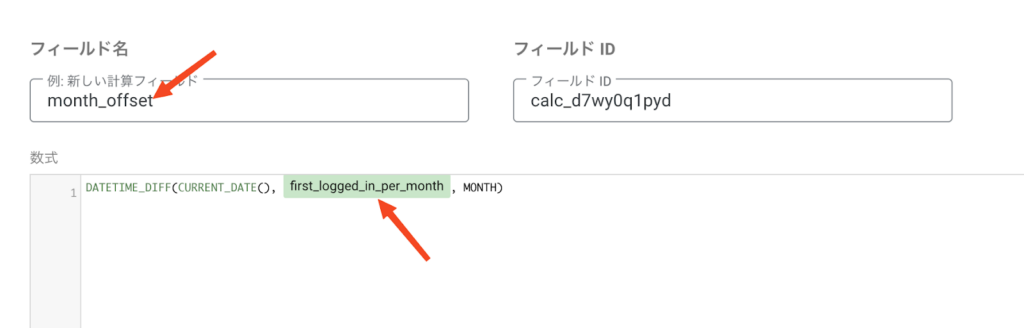
ここで使用されている言語は、Looker Studio独自の関数構文です。 必要に応じて他の種類の計算を行いたい場合は、以下の公式ドキュメントを参照してください:
https://docs.cloud.google.com/looker/docs/studio/function-list?hl=ja
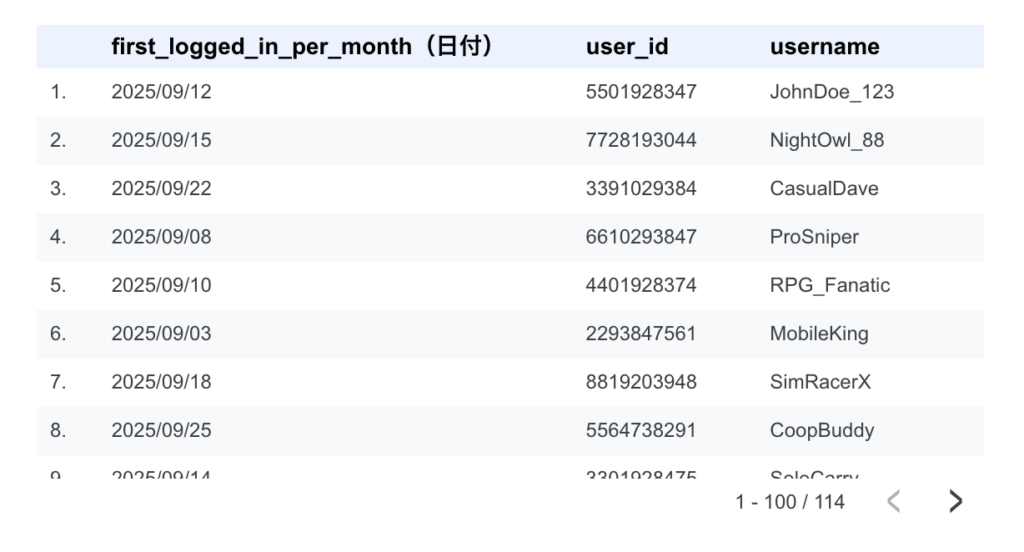
計算フィールドを追加した後、テーブルを見てみると、データが何ヶ月前のものかが数字で表示されているはずです。 例えば、現在が2025年12月だとすると、2025年9月のデータは「3」、10月のデータは「2」といった具合に表示されます:
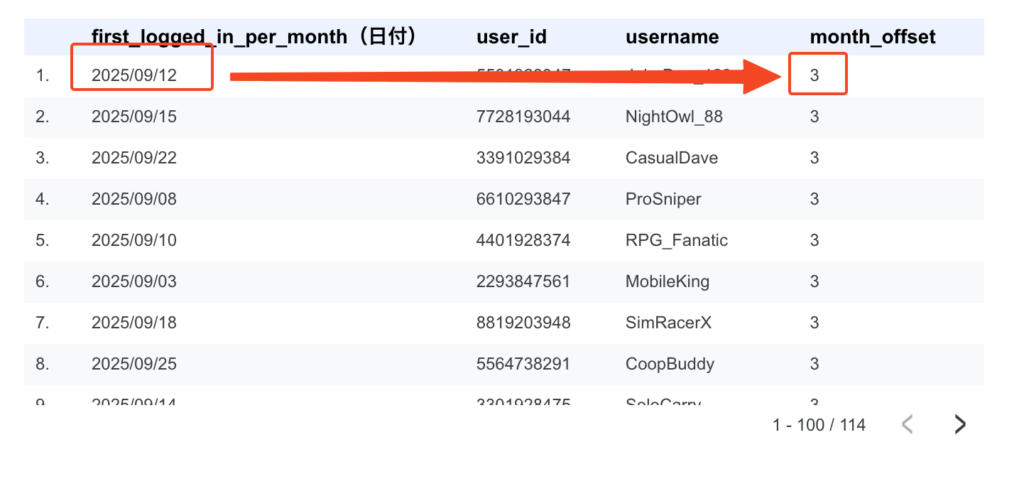
これで、この新しいカラムをフィルタ条件として使う準備が整いました。
データの統合を使う
クエリでは FULL OUTER JOIN を使って、「先月」と「2ヶ月前」のデータを実質的に突き合わせ(比較)ていましたね。 これと同じことをLooker Studioで行うには、「データの統合(Blend Data)」機能を使います。 プロパティ(設定)パネルにある「データを統合」ボタンをクリックしましょう。正しいデータソースが選択されているか確認してください:
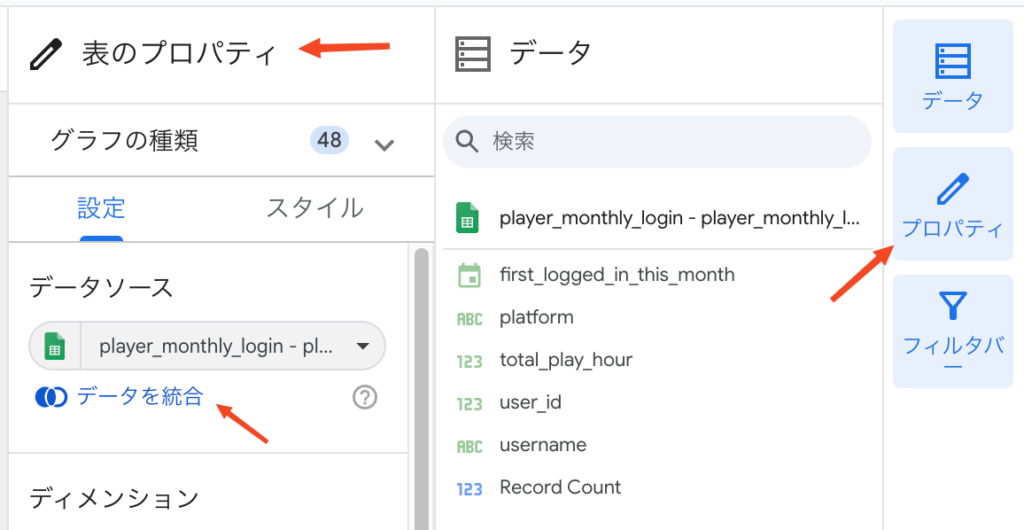
「データを統合」ウィンドウが開いたら、同じテーブル同士を、異なる期間で結合する設定を行います。 そのため、「別のテーブルを結合」をクリックし、現在選択しているのとまったく同じテーブルをもう一度追加します。 区別しやすいように、テーブル名を「2ヶ月前データ」「先月データ」のように変更しておきましょう。 また、最終的に知りたいのは「先月の新規プレイヤーのIDと名前」だけなので、ディメンションには user_id と username だけを選んでおきます:
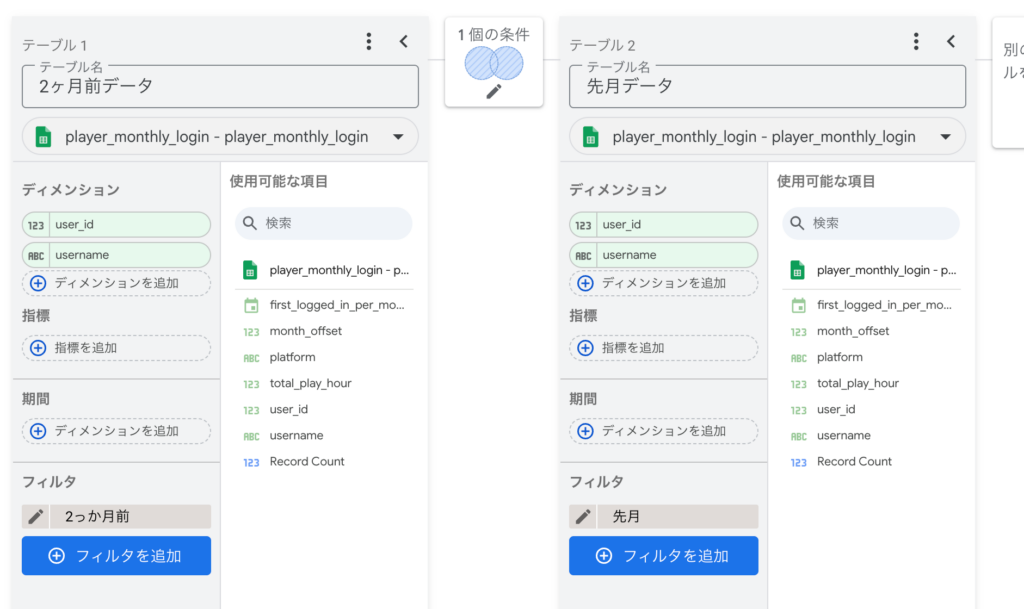
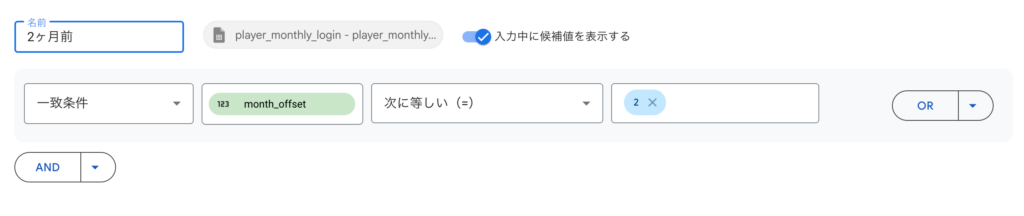
この状態で、左側のデータには「2ヶ月前」のデータだけが残るようにフィルタをかけます。 「フィルタを追加」をクリックし、先ほど作った month_offset の値が「2」になるデータだけを抽出するように設定します:
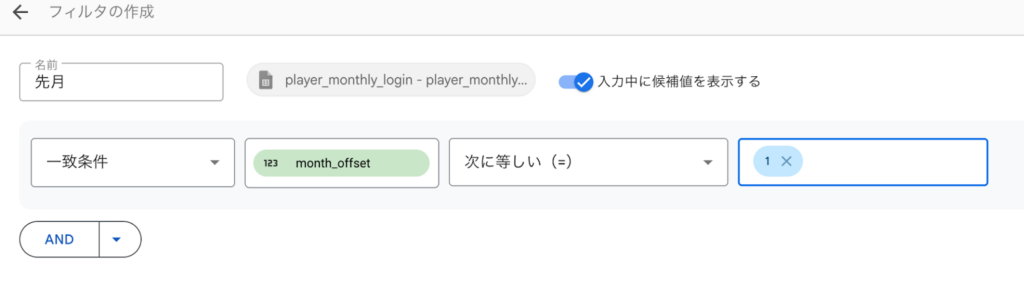
右側のデータも同様に操作しますが、こちらは「先月」のデータが欲しいので、month_offset の値が「1」になるように設定しましょう:
ここで重要なのは、データの結合設定の「内側」でフィルタをかけて、特定の期間のユーザーリスト(バケット)を作ってから結合することです。もし結合した後の最終的なグラフ側でフィルタをかけようとしても、このロジックは正しく動作しません。
準備ができたら、いよいよ結合です。 クエリの時と同じく「完全外部結合(Full Outer Join)」を選択します。結合キー(結合条件)も同様に user_id を使用します:
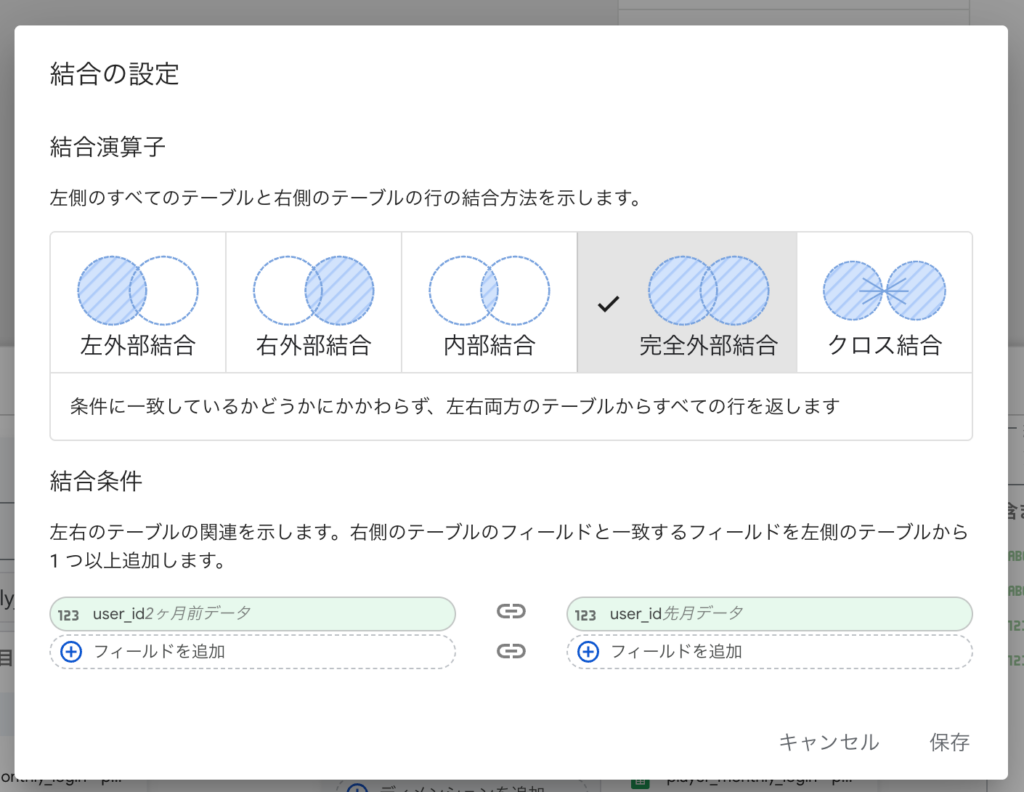
結合設定が完了すると、左右両方のテーブルから username と user_id が出てきて重複してしまいます。 今回は「先月のデータ」を表示させたいので、右側(先月分)のテーブルにあるディメンションだけを選択して保存しましょう:
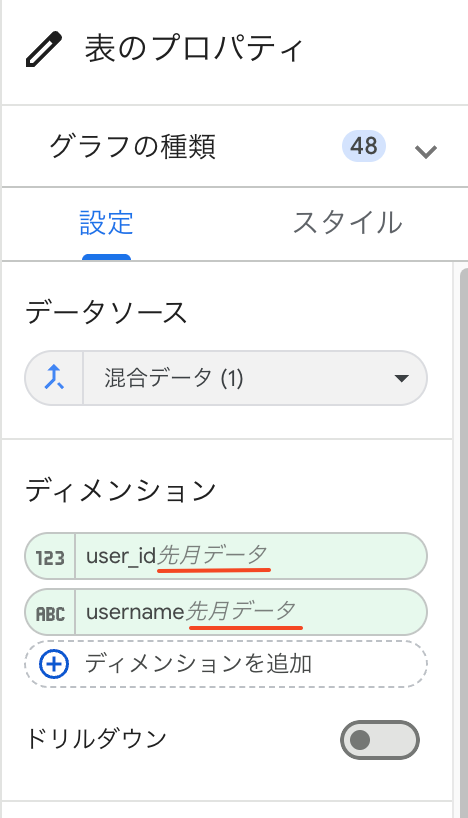
フィルタを活用する
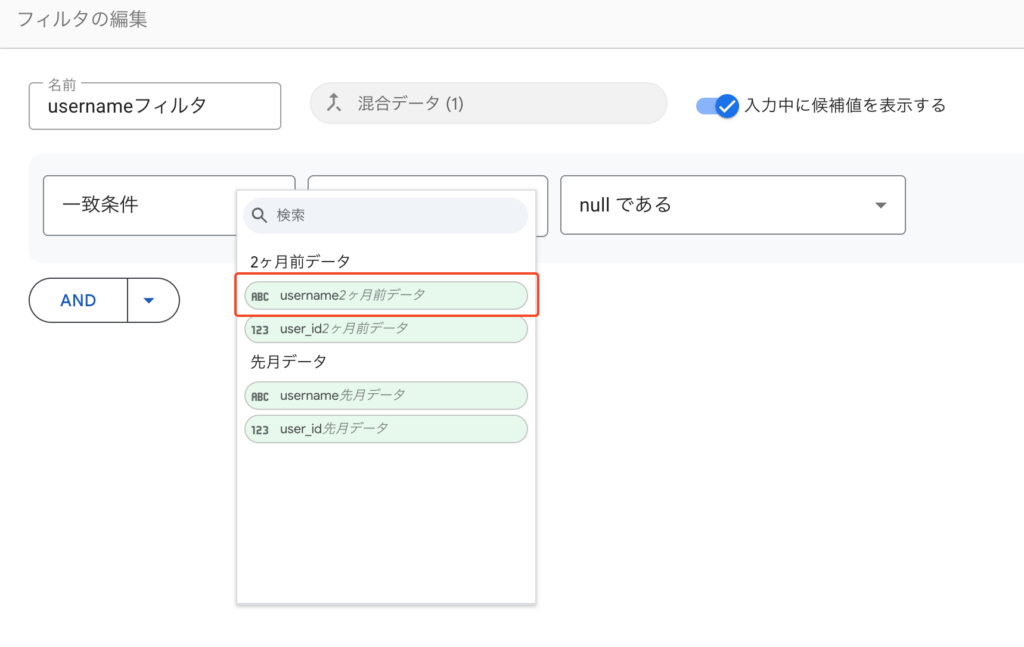
最後に、「先月のデータにしか存在しない(2ヶ月前にはいなかった)」ユーザーだけを特定しましょう。 クエリでは WHERE pp.user_id IS NULL (2ヶ月前のIDがNULLであること)という条件を使っていましたね。
Looker Studioにおいて、特定の値が「NULL(空)であるかどうか」の判定は標準機能でサポートされています。そのため、今回は計算フィールドのような工夫を使わずに、通常の「フィルタ」機能だけで実現できます。 手順は先ほどと似ていますが、今回は「データの統合」メニューの中ではなく、キャンバスに配置したテーブル、そのものにフィルタを追加します:
フィルタを適用すると、テーブルの表示はこのようになります:
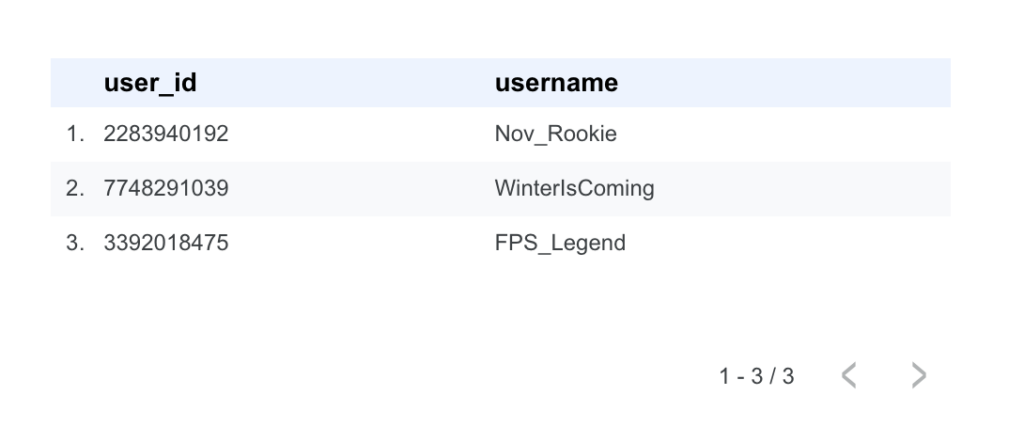
記事の冒頭で紹介したクエリの実行結果と比べてみると、まったく同じ結果になっていることが分かります。
これで、SQLクエリの内容を、Looker Studioの機能だけで完全に再現することができました!
まとめ
今回の記事では、動的なフィルタを実現するための回避策として「計算フィールド」を活用する方法や、データを比較するための「データの統合」の使い方について紹介しました。
あらかじめ計算フィールドで「判定用の中間データ」を作っておくというアプローチは、他にも様々な場面で応用できます。 例えば、「2つのカラムの値を比較して大きい方だけを取り出す」場合や、「正規表現にマッチするかどうかを判定してフィルタする」場合など、標準機能だけでは難しい複雑な条件でフィルタをかけたい時に非常に役立ちます。
この記事が、Looker Studioでのデータ加工に悩んでいる方の助けになれば嬉しいです。 エンジニアかどうかにかかわらず、誰もがもっと自由に、もっと簡単にデータを扱えるようになるといいですね!


