

目次
巷で話題のgemini-cliのネタです。

こんにちは!長谷川です。
今日はgemini-cliを書いて見ようかなと
GitHub – google-gemini/gemini-cli: An open-source AI agent that brings the power of Gemini directly…
個人的にはリリース直後からdotfilesの管理などでgemini-cliを使っていました。
たくさんのファイルの変更など個人的にかなり助かってます。
今日は表題の通りですが、LinuxのKernel ParameterをTuningするのに使えるのか試してみたので、その結果を書きます。
この記事の前提としてですが、かなり実験要素が強いです。
この点に留意して読んでください。
まずLinuxのKernel Parameter Tuningについて
実際にやられた方ならわかると思いますが
- まず第一に正解がない
- 今、目で見ている負荷状況が本当にそのHostにとってのピークであり、1番解決すべき問題が発生している状況下であるか?
- どこまで追求するか?
- どこで止めるか?
- 限られたリソースをどこに割り当てるか?
- どこに余力を持たせるか?
- どこに集中させるか?
- 何を犠牲に(いろいろ乗っかってるHostの場合)するか?
- どこを落とし所とするか?
- どれくらいの期間や変化で再度確認するか?
けっこうむずかしい話だなと感じています。
度胸も必要ですし、やり始めの最初なんかはまったくわからない世界だと思うので大量の情報収集や検証が必要です。
若い頃かなりやってたの思い出します。
少し背景として、いくつか昔話をさせてください。
オンプレミス時代
オンプレミスな環境だと、キャパシティサイジングはとても難しくなります。ビジネスの成長を予測しながらインフラ投資における予算計画を立て、リソースをインフラのクラスタの中で割り当て、どうにか安定化させていくわけです。
特に成長が著しい状況下の場合、潤沢な予算を用意することはとても難しいことがあります。何故なら常時、その前の予算計画を超え続けていくことになり、エンジニアとして多数の役割、職種の人との細かい会話が必要になります。
またサーバも含めたネットワークやストレージの専用ハードウェアは、特定の性能を超えたあたりから値段が爆発的に高くなります。これを専門性が異なる職種の人間に説明していくスキルが必要になります。
私はもうおじさんで20年もやってきており、幸運なことにそれなりに大きな環境に触れる機会もたくさんありました。
オンプレミスで容易にリソースを追加できない状況下で、C10K問題やI/O Hell(例えば1台あたり16万くらいの監視ポイントを持つNagiosやIcingaと組み合わせたpnp4nagios/rrdtoolのクラスタ)と格闘していました。
こういった追い詰められた状況下でいろいろな工夫をしていくのですが、手法としてLinux Kernel Parameter Tuningはとても有効でした。
Microsoft Windows Server / SQL Server
Linuxの話題からは逸れますが、前職で私はMicrosoft SQLServerにおいて、当時Fusion-IOというPCI接続のSSDを日本国内で最初にProductに導入したことがあります。
その際に、SQLServerのレジストリをそれなりに修正し、かなり高速なSQLServerを構成することができました。
それは後にMicrosoftに回収され、SQLServer2012R2の標準的なレジストリ項目としてMicrosoftに取り込まれたなんて経験もあります。
LinuxだけではなくWindowsも似たようなチューニングで性能向上がみられます。(最近のWindowsは知りません😅)
話を戻してLinux Kernel Parameterに
またLinuxのKernel ParameterはLinuxのKernel Versionで変化していくのでそれに追従していくのも大変です。
gemini-cliと協力すれば、必要な情報をそれなりのボリュームで渡す必要があるものの、それぞれのKernel Parameterの解説もしてくれますし、判断材料になる解説もしてくれます。
そして先にも書きましたが、Linux Kernel Parameterには絶対的な正解が存在しないと考えています。
ある一定ラインでは、このラインみたいなものはありますが、より無難なラインを探し続けるものだと考えています。
その作業の手助けになるのではと考えてこれをやり始めてます。
似たような目的のものは他にもあります。
RedhatのTunedやOracleのbpftuneなどがあります。
またgithubを漁るとkernel parameterを適応するscriptなどたくさん見つかります。
それらも参考にすると良いと思います。
以下はOracleのbpftuneですが、YouTubeの動画も参考になると思います。
GitHub – oracle/bpftune: bpftune uses BPF to auto-tune Linux systems
Install gemini-cli
まずはInstall
GitHub – google-gemini/gemini-cli: An open-source AI agent that brings the power of Gemini directly…
自分はnodeで散らかるのが嫌なのでvoltaでInstallします。
Volta – The Hassle-Free JavaScript Tool Manager
以下を実行すればInstallされると思います。
declare -x VOLTA_HOME=${HOME}/.volta
declare node_modules=(node npm npx yarn)
curl -s https://get.volta.sh | bash
if [ ! -d ${VOLTA_HOME} ]; then
curl -s https://get.volta.sh | bash
for nm in ${node_modules[@]}
do
${VOLTA_HOME}/bin/volta install ${nm}
done
${VOLTA_HOME}/bin/volta install @google/gemini-cli
figemini-cli
gemini-cliを起動してみましょう。
gemini
実際の使い方とかは他の方が書いてくれてると思うので細かい紹介は割愛します。
.gemini/settings.json
自分は以下をtrueにしてます。
- respectGitIgnore
- enableRecursiveFileSearch
詳細はこちらを確認してください。
gemini-cli/docs/cli/configuration.md at main · google-gemini/gemini-cli
gemini-cliは先週0.1.4で2025/07/10の現在では0.1.9とかなりupdateが行われているのでできるだけ最新を使いましょう。
また上記のConfigurationだけではなくあちこちupdateされると思うので、都度あちこち確認してSetupしましょう😆
docs/LinuxKernelParameterTuning.md
gemini-cliにお願いする内容をmarkdownで準備します。
大まかにセクションとしては以下になっています。
- Execution Modes
- Default Assumptions for Tuning Simulation
- Tuning Strategy
- Level 1: Generic Base-line Kernel Settings
- Level 2: Cloud Platform-Specific Overrides
- Level 3: Application-Specific Overrides
ここまで固めるのに紆余曲折がいろいろあり、会議など別のことをやりながらではありますが、2〜3日程度かかっています。
これがベストとも言うつもりはありません。
もっと良いコンテキストはあると思います。またアプローチももっと別な方法があると思います。
一例として参考にして頂けたらと考えています。
geminiにどう伝えるか、どう解釈させるか、こちらの意図をどう実行してもらうかはちょっと慣れが必要かもしれないです。
Get yusuke’s stories in your inbox
Join Medium for free to get updates from this writer.Subscribe
また冒頭に注意点を書いていますが、実行することを重視しているので現時点の精度などはそれなりで進めています。
# Linux Kernel Parameter Tuning Guide
* This document will be written in English.
* Explanations and commentary will be provided in Japanese.
## Primary Goal
* When a "tuning" request is received, we will review the Tuning Strategy and provide tuning suggestions for Linux kernel parameters.
* The suggestions should aim to achieve high durability, density, and availability, and should be explained in Japanese.
### Execution Modes
This guide supports two main modes for generating kernel parameter recommendations: **Tuning** and **Tuning Simulation**.
* **`tuning` (Live Tuning)**:
* **Trigger**: When you request "tuning".
* **Action**: The agent will gather *live system information* (such as CPU cores, total memory, running services, etc.) from the Linux environment to generate a customized set of kernel parameter recommendations.
* **Use Case**: Use this mode when you want to tune the Linux system the agent is currently running on.
* **`tuningsim` (Simulation)**:
* **Trigger**: When you request "tuningsim".
* **Action**: The agent will use a set of *pre-defined, hypothetical hardware and workload characteristics* (as described in the "Default Assumptions for Tuning Simulation" section) to generate a general-purpose set of recommendations. It will **not** gather live data from the system.
* **Use Case**: Use this mode to get a baseline recommendation without providing access to a live system, or for educational purposes.
* **Special Condition for macOS**:
* If a "tuning" request is made from a macOS environment, the agent will automatically switch to **`tuningsim`** mode. This is because the kernel parameters and data gathering commands are specific to Linux and cannot be executed on macOS.
The following sections detail the assumptions for simulation mode and the overall tuning strategy.
### Default Assumptions for Tuning Simulation
When a "tuningsim" is requested without access to a live target system, the following hypothetical environment will be assumed to generate a baseline set of tuning recommendations. This ensures that the proposals are practical and consistent.
* **Operating System**: Debian Stable (e.g., Debian 12 "Bookworm") with its default kernel.
* **Hardware**:
* **CPU**: 8 Cores
* **Memory**: 16 GB
* **Disk**: SSD
* **Platform**: Generic Cloud Environment (allowing for common cloud-focused tuning like BBR).
* **Workload**: General-purpose web server and database stack (e.g., Nginx + PostgreSQL/MySQL). This assumption allows for providing both general and application-specific recommendations.
## Tuning Strategy
1. **Base Analysis**: This step clarifies the objectives and current state of the system to establish a foundation for a systematic tuning approach.
* **Hearing the Objective:**
* **What is the problem to be solved?** (e.g., slow website response, database processing bottlenecks, specific batch jobs not finishing on time)
* **What is the desired state?** (e.g., reduce average response time to under 50ms, complete batch processing within 30 minutes)
* **What is the business impact?** (e.g., improved user experience, reduced infrastructure costs)
* **Grasping the Current State:**
* Roughly understand the system load during normal operation and when the problem occurs.
* Check for critical errors that should be resolved before tuning (e.g., disk I/O errors, network errors) using `dmesg` or `journalctl`.
* Check if the load average is abnormally high using the `uptime` command.
* **Establishing a Baseline:**
* Measure and record performance before making any changes. Without this, it's impossible to objectively judge the effectiveness of the tuning.
* Record key metrics such as CPU usage, memory usage, disk I/O, and network I/O using commands like `vmstat`, `iostat`, and `sar`.
* **Confirming Constraints:**
* When is the service maintenance window (e.g., possibility of reboots)?
* Is a change history or approval process required for applying settings?
* Are there any rules to adhere to, such as cloud platform policies or internal security policies?
2. **Parameter Source**: Use `sysctl -a` to gather current kernel parameters and suggest changes based on the analysis.
3. **Workload Consideration**: Factor in workloads like web servers, databases, and batch processing.
4. **No Swap Tuning**: Do not provide suggestions related to swap.
* Swap tuning is not included in this guide.
* The focus is on kernel parameters that enhance performance, durability, and availability without involving swap configurations.
* Swap is generally not recommended for high-performance applications.
* In cloud environments, swap is often not used or is configured differently.
* For systems with large amounts of memory, swap is typically not needed.
* Cloud-based temporary instances (preemptible, etc.) may require swap settings.
* There are exceptional cases where using `zram` or using some disk compressed swap is effective.
* For systems with less than 8GB of memory, we recommend using `zram` rather than disabling swap completely.
* `zram` uses RAM compression, which can improve memory efficiency while avoiding disk IO.
* **Note on `vm.swappiness`**: While general swap tuning is outside the scope of this guide, `vm.swappiness` is treated as an exception because it directly impacts application performance and memory management for specific workloads. Accordingly, specific recommendations for `vm.swappiness` are provided for relevant workloads.
5. **System Information Gathering**:
During this step, collect system information using the files and commands listed below. Some of these operations may require elevated privileges.
**General Rule**: If any command execution or file access fails due to a permission error, automatically retry the operation with `sudo`. If it still fails even after adding `sudo`, skip that operation and proceed to the next information gathering step.
* `/etc/os-release`: OS version and distribution.
* Command `uname -a`: Kernel version and architecture.
* `/sys/class/dmi/id/product_name`: Hardware model and Cloud Platform.
* `/sys/class/dmi/id/sys_vendor`: Hardware vendor and Cloud Platform.
* Command `dmidecode -s system-product-name`: Hardware model and Cloud Platform.
* Command `nproc`: Number of CPU cores.
* Command `lscpu`: CPU architecture and details.
* `/proc/cpuinfo`: Detailed CPU information.
* `/proc/meminfo`: Memory details.
* `/sys/class/net/*/tx_queue_len`: NIC settings and stats.
* `/sys/class/net/*/rx_queue_len`: NIC settings and stats.
* Command `for iface in /sys/class/net/*; do name=$(basename ${iface}); ethtool -k ${name}; done`: NIC offload settings.
* Command `for iface in /sys/class/net/*; do name=$(basename ${iface}); ethtool -g ${name}; done`: NIC Ring Buffer settings.
* Command `sudo dmesg`, `sudo journalctl -p err..alert -n 1000 --no-pager`: Kernel/system logs for errors.
* Command `getconf -a`: System resource limits.
* Command `ss -tulnp`: Network socket states.
* Command `ps aux`: Running processes.
* Command `systemctl list-units --type=service --all`: Running services.
* Command `vmstat 1 10`: Virtual memory statistics.
* Command `iostat -x 1 10`: Disk I/O statistics.
* Command `sar -u 1 10`: CPU usage statistics.
* Command `uptime`: System uptime and load averages.
* ` * /etc/security/limits.conf`, `/etc/security/limits.d/*.conf`: User/process resource limits (Note: These files may not exist on all systems, in which case default limits apply).
* Command `sudo sysctl -a`: Current kernel parameters. If the command is not found, install the `procps` package (e.g., `sudo apt-get install procps` on Debian/Ubuntu or `sudo dnf install procps-ng` on Fedora/CentOS).
* Command `numactl -H`: NUMA hardware configuration. If `numactl` is not installed, check for NUMA support with `lscpu | grep NUMA` or by inspecting the `/sys/devices/system/node/` directory.
6. **Platform-Specific Tuning**: Apply specific tuning for GCP, AWS, and Azure based on virtualization info.
7. **Application-Specific Tuning**:
* Based on running processes, provide specific recommendations for middleware like MySQL/MariaDB, Nginx/Apache, etc., as detailed in the "Level 3: Application-Specific Overrides" section. This includes kernel parameters and `systemd` resource limits.
8. **Security Tuning**: Suggest security-hardening parameters (e.g., for SYN floods, ICMP redirects).
9. **Performance Tuning**: Focus on parameters that enhance performance, such as TCP settings, file descriptor limits, and network buffer sizes.
10. **Output Policy**:
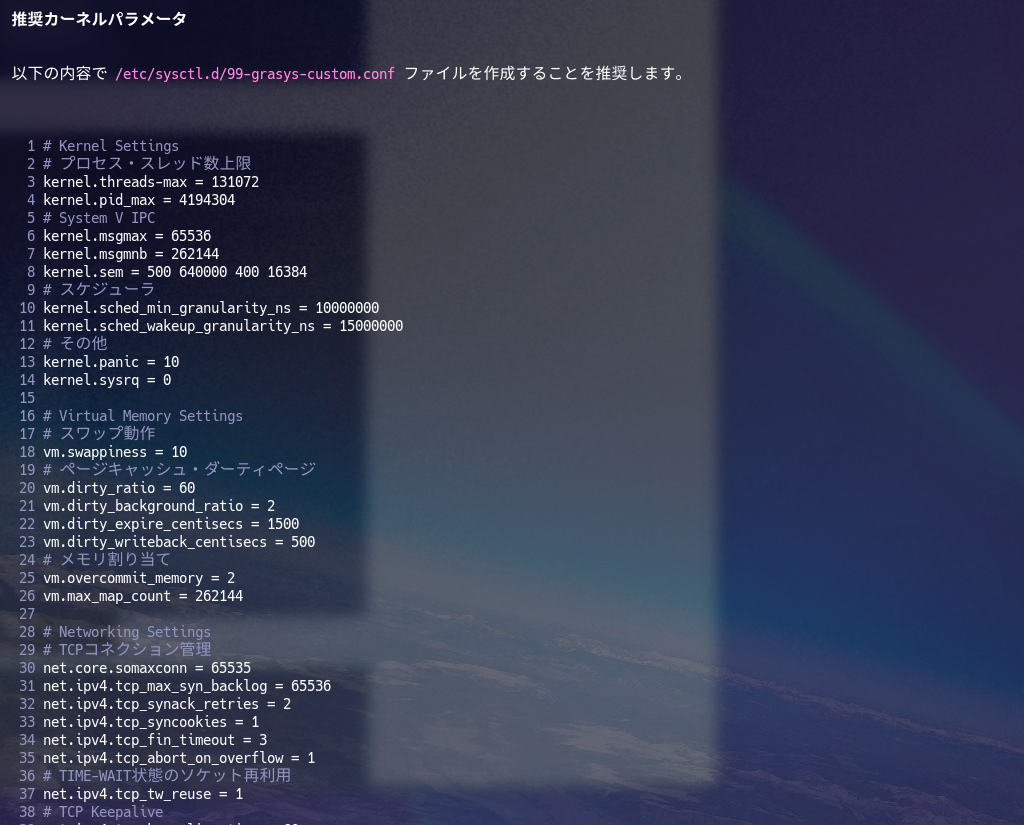
* Do not directly reflect the changes under `/etc/sysctl.d/`, but leave it as a proposal and leave it to the discretion of the user to decide whether or not to reflect them.
* If you do reflect them, the file path should be `/etc/sysctl.d/99-grasys-custom.conf`.
### Level 1: Generic Base-line Kernel Settings
For the Level 1 baseline, first use the formulas in the `Kernel Parameter Calculation Method` section at the end of this document to generate dynamic values.
The static parameters listed below should be used as a reference or as a supplement to the calculated values.
**This calculated baseline should be applied first.**
If a kernel parameter is defined in both "Level 1: Generic Base-line Kernel Settings" and "Kernel Parameter Calculation Method", the value derived from "Kernel Parameter Calculation Method" takes precedence.
#### **1. Kernel Settings (`kernel.*`)**
These parameters control the core behavior of the Linux kernel, including process management, scheduling, and system-level controls.
* **Process and Thread Limits:**
* `kernel.threads-max=131072`
* `kernel.pid_max=4194304`
* **System V IPC (Inter-Process Communication):**
* `kernel.msgmax=65536`
* `kernel.msgmnb=262144`
* `kernel.sem="500 640000 100 4096"`
* **Scheduler:**
* `kernel.sched_min_granularity_ns=10000000`
* `kernel.sched_wakeup_granularity_ns=15000000`
* `kernel.numa_balancing=0`
* **System Control & Security:**
* `kernel.panic=10`
* `kernel.sysrq=0`
* `kernel.core_pattern=/var/lib/systemd/coredump/core.%p`
* `kernel.randomize_va_space=2`
#### **2. Virtual Memory Settings (`vm.*`)**
These parameters manage the kernel's virtual memory subsystem, affecting how memory is allocated, used, and written to disk.
* **Swapping Behavior:**
* `vm.swappiness = 10`
* **Page Cache / Dirty Pages:**
* `vm.dirty_ratio = 60`
* `vm.dirty_background_ratio = 2`
* `vm.dirty_expire_centisecs = 1500`
* `vm.dirty_writeback_centisecs = 500`
* **Memory Allocation:**
* `vm.overcommit_memory = 2`
* `vm.max_map_count = 262144`
#### **3. Networking Settings (`net.*`)**
These parameters configure the networking stack, including TCP/IP behavior, buffer sizes, and connection management.
* **TCP Connection Management:**
* `net.core.somaxconn = 65535`
* `net.ipv4.tcp_max_syn_backlog = 65536`
* `net.ipv4.tcp_synack_retries = 2`
* `net.ipv4.tcp_syncookies = 1`
* `net.ipv4.tcp_fin_timeout = 3`
* `net.ipv4.tcp_orphan_retries = 3`
* `net.ipv4.tcp_abort_on_overflow = 1`
* **TCP TIME-WAIT State:**
* `net.ipv4.tcp_tw_recycle = 0`
* Obsolete and can cause issues with NAT. Should always be disabled. (Note: This parameter was removed in Linux kernel 4.12 and later.)
* `net.ipv4.tcp_tw_reuse = 1`
* **TCP Keepalive:**
* `net.ipv4.tcp_keepalive_time = 60`
* `net.ipv4.tcp_keepalive_probes = 3`
* `net.ipv4.tcp_keepalive_intvl = 10`
* **TCP Performance & Behavior:**
* `net.ipv4.tcp_rfc1337 = 1`
* `net.ipv4.tcp_dsack = 1`
* `net.ipv4.tcp_sack = 1`
* `net.ipv4.tcp_fack = 1`
* `net.ipv4.tcp_timestamps = 1`
* `net.ipv4.tcp_slow_start_after_idle = 0`
* **Network Buffers & Queues:**
* `net.core.netdev_max_backlog = 250000`
* `net.core.rmem_default = 8388608`
* `net.core.rmem_max = 16777216`
* `net.core.wmem_default = 8388608`
* `net.core.wmem_max = 16777216`
* **IP & Port Configuration:**
* `net.ipv4.ip_local_port_range = 2000 65535`
* **ICMP Settings:**
* `net.ipv4.icmp_echo_ignore_all = 0`
* `net.ipv4.icmp_echo_ignore_broadcasts = 1`
* `net.ipv4.icmp_ignore_bogus_error_responses = 1`
#### **4. Filesystem Settings (`fs.*`)**
These parameters relate to the filesystem, including limits on file handles and asynchronous I/O.
* **Asynchronous I/O (AIO):**
* `fs.aio-max-nr = 1048576`
---
### Level 2: Cloud Platform-Specific Overrides
If your system is running on a specific cloud provider (GCP, AWS, Azure), **apply these settings *after* the Level 1 baseline.** These recommendations override some of the generic values to better leverage the unique network and virtualization characteristics of each platform.
#### Common Recommendations for All Cloud Platforms
These parameters override some of the Level 1 values to improve network performance and system stability on cloud platforms.
* **Memory Management**
* `vm.dirty_ratio = 20`: Adjusts the percentage of memory that can be filled with dirty (not yet written to disk) pages.
* `vm.dirty_background_ratio = 5`: Adjusts the threshold at which background processes start writing dirty pages to disk.
* `vm.overcommit_memory = 1`: Allows memory overcommitment, but caution is advised for allocations exceeding physical memory.
* **Filesystem & I/O**
* `fs.file-max = 1048576`: Increases the system-wide limit for concurrently open file descriptors.
* `fs.epoll.max_user_watches = 524288`: Increases the number of files that can be monitored by `epoll`, enhancing the capacity of servers handling numerous concurrent connections.
* **Networking (TCP/IP Stack)**
* `net.ipv4.tcp_fin_timeout = 15`: Shortens the `FIN-WAIT-2` state timeout to prevent idle sockets from consuming resources.
* **TCP Keepalive Settings**:
* `net.ipv4.tcp_keepalive_time = 300`: Sets the interval for sending keepalive packets to 300 seconds.
* `net.ipv4.tcp_keepalive_probes = 5`: Sets the number of retransmissions to 5 if no response is received.
* `net.ipv4.tcp_keepalive_intvl = 15`: Sets the retransmission interval to 15 seconds.
* `net.core.netdev_max_backlog = 65536`: Increases the queue size for incoming packets processed by the network device driver.
* **TCP Buffer Sizes**:
* `net.core.rmem_default = 262144`: Default TCP receive buffer size.
* `net.core.wmem_default = 262144`: Default TCP send buffer size.
* `net.core.rmem_max = 16777216`: Maximum TCP receive buffer size.
* `net.core.wmem_max = 16777216`: Maximum TCP send buffer size.
* `net.ipv4.tcp_mem = 16777216 16777216 16777216`: Adjusts the total memory used by the TCP stack.
* `net.ipv4.tcp_rmem = 4096 87380 16777216`: Sets the minimum, default, and maximum TCP receive buffer sizes.
* `net.ipv4.tcp_wmem = 4096 65536 16777216`: Sets the minimum, default, and maximum TCP send buffer sizes.
#### Google Cloud Platform (GCP)
To fully leverage GCP's high-performance network infrastructure, using the **BBR** TCP congestion control algorithm is strongly recommended.
* **Recommended Parameters**:
* `net.core.default_qdisc = fq`: Sets the default packet scheduler to `fq` (Fair Queue), a prerequisite for BBR.
* `net.ipv4.tcp_congestion_control = bbr`: Sets the TCP congestion control algorithm to `bbr` to maximize throughput and minimize latency.
#### Amazon Web Services (AWS) EC2
The following tuning is effective for EC2 instances, especially those with Enhanced Networking (ENA).
* **Recommended Parameters**:
* `net.core.default_qdisc = fq`: BBR is also effective on AWS, so `fq` is recommended.
* `net.ipv4.tcp_congestion_control = bbr`: Recommends `bbr` as the TCP congestion control algorithm.
* `net.ipv4.tcp_mtu_probing = 1`: Enables Path MTU Discovery, which is useful for dynamically finding the optimal MTU size, especially in environments using Jumbo Frames.
#### Microsoft Azure
These settings help maximize network throughput for Azure VMs with Accelerated Networking.
* **Recommended Parameters**:
* `net.core.default_qdisc = fq`: BBR is also recommended for Azure, so `fq` should be set.
* `net.ipv4.tcp_congestion_control = bbr`: Recommends `bbr` as the TCP congestion control algorithm.
* `net.ipv4.tcp_timestamps = 0`: Disabling TCP timestamps can sometimes improve performance in specific Azure network environments, but it's generally not recommended as it can impact security and performance (e.g., PAWS/RST). Consider this setting carefully and test thoroughly.
---
### Level 3: Application-Specific Overrides
If you are running specific middleware, **apply these settings *last*.** They override any conflicting values from Level 1 or Level 2 to provide the best performance for a particular workload (e.g., Redis, Nginx).
#### **Web Servers: Nginx / Apache (httpd)**
If `nginx.service` or `httpd.service` is running, the following settings are recommended to handle a large number of concurrent connections.
* **Kernel Parameters (`sysctl`)**:
* `net.core.somaxconn = 65535`: Increases the maximum number of connections queued for acceptance. This value should be mirrored in the application's `listen` backlog setting.
* `net.ipv4.tcp_max_syn_backlog = 65536`: Allows the system to handle more half-open connections, mitigating SYN flood attacks.
* `net.ipv4.tcp_tw_reuse = 1`: Allows reusing sockets in `TIME_WAIT` state for new connections, which can be useful for high-traffic servers.
* **systemd Resource Limits**:
* **Proposal**: Create an override file for the service to increase the open file descriptor limit.
* **Command**: `systemctl edit nginx.service` (or `httpd.service`)
* This command creates a drop-in file (e.g., `/etc/systemd/system/nginx.service.d/override.conf`) to extend or override the service unit configuration.
* **Content for override.conf**:
```ini
[Service]
LimitNOFILE=65536
```
#### **Databases: MySQL / MariaDB / PostgreSQL**
If `mysqld.service`, `mariadb.service`, or `postgresql.service` is running, these settings improve I/O performance and connection handling.
* **Kernel Parameters (`sysctl`)**:
* `fs.aio-max-nr = 1048576`: Increases the maximum number of concurrent asynchronous I/O requests, crucial for database performance.
* `vm.swappiness = 10`: Reduces the kernel's tendency to swap, which is critical for database responsiveness.
* (PostgreSQL-specific) `kernel.shmmax` and `kernel.shmall`: While modern PostgreSQL handles shared memory allocation well, ensure these values are large enough for your configuration, especially on older systems. A common recommendation for `kernel.shmmax` is half of the system's RAM, and `kernel.shmall` should be `kernel.shmmax` divided by `PAGE_SIZE` (typically 4096).
* (Advanced) `vm.nr_hugepages`: For large database instances, pre-allocating Huge Pages can significantly improve performance. This requires setting `huge_pages = on` (or equivalent) in the database configuration. The value for `nr_hugepages` must be calculated based on the database's buffer/SGA size and the system's `Hugepagesize` (from `/proc/meminfo`). A common guideline is to allocate enough huge pages to cover the database's shared buffer (e.g., `shared_buffers` in PostgreSQL). **Note:** This memory is reserved and cannot be used by other processes.
* **systemd Resource Limits**:
* **Proposal**: Create an override file to significantly increase the open file descriptor limit, as databases open many files for tables, indexes, and connections.
* **Command**: `systemctl edit mysqld.service` (or `mariadb.service`, `postgresql.service`)
* **Content for override.conf**:
```ini
[Service]
LimitNOFILE=1048576
```
#### **Key-Value Store: Redis**
If `redis.service` is running, tuning should focus on network performance and memory management.
* **Kernel Parameters (`sysctl`)**:
* `net.core.somaxconn = 65535`: Essential for handling many simultaneous connections.
* `vm.overcommit_memory = 1`: **Strongly recommended by Redis documentation.** This setting prevents background saves (`BGSAVE`) from failing due to memory allocation checks, which can occur even if there is enough physical memory available. This overrides the generic setting of `2`.
* **systemd Resource Limits**:
* **Proposal**: Create an override file to increase the open file descriptor limit.
* **Command**: `systemctl edit redis.service`
* **Content for override.conf**:
```ini
[Service]
LimitNOFILE=65536
```
#### **Streaming Database: RisingWave**
If `risingwave.service` is running, the following settings are recommended to ensure optimal performance for its high-throughput, memory-intensive, and low-latency stream processing workload.
* **Kernel Parameters (`sysctl`)**:
* `kernel.numa_balancing = 0`: **Critical for performance stability.** Disabling automatic NUMA balancing prevents unpredictable latency spikes caused by memory migration across NUMA nodes. While this is set in Level 1, it is essential for RisingWave's compute nodes, especially when using process pinning with `numactl`.
* `vm.overcommit_memory = 1`: **Strongly recommended.** Similar to Redis, this allows RisingWave to handle memory allocation more reliably, especially for stateful processing and background compaction, preventing potential failures.
* `vm.swappiness = 10`: Keeps RisingWave's memory in RAM, avoiding performance degradation from swapping.
* `fs.file-max = 1048576`: Supports a large number of open files for state storage and internal operations.
* `fs.aio-max-nr = 1048576`: Enhances asynchronous I/O capabilities, crucial for persistent state management.
* `net.core.somaxconn = 65535`: Increases the connection backlog to handle a high volume of incoming connections from clients and other nodes.
* **Transparent HugePages (THP)**:
* **Recommendation**: Disable THP to avoid significant latency spikes.
* **Check Status**: `cat /sys/kernel/mm/transparent_hugepage/enabled`
* **Temporary Disable**: `echo never > /sys/kernel/mm/transparent_hugepage/enabled`
* **Permanent Disable**: Add `transparent_hugepage=never` to the `GRUB_CMDLINE_LINUX` line in `/etc/default/grub` and run `update-grub` or `grub2-mkconfig`.
* **I/O Scheduler**:
* **Recommendation**: The optimal I/O scheduler depends on the storage device. For high-speed devices like NVMe and SSDs, `none` is recommended to minimize CPU overhead. For traditional magnetic disks (HDDs), `deadline` is a better choice to optimize I/O operations.
* **How to identify and set**:
1. First, list your block devices and their type (rotational or not) with `lsblk -d -o name,rota`. The `ROTA` column will be `0` for SSDs/NVMe and `1` for HDDs.
2. Based on the device type and name (e.g., `nvme0n1`, `sda`), apply the appropriate scheduler.
* For an NVMe/SSD device (e.g., `nvme0n1`):
`echo none > /sys/block/nvme0n1/queue/scheduler`
* For a magnetic disk (e.g., `sda`):
`echo deadline > /sys/block/sda/queue/scheduler`
* **Permanent Setting**: To apply this setting on boot, it is recommended to use `udev` rules.
* **systemd Resource Limits**:
* **Proposal**: Create an override file to increase the open file descriptor limit.
* **Command**: `systemctl edit risingwave.service`
* **Content for override.conf**:
```ini
[Service]
LimitNOFILE=1048576
```
#### **Message Broker: Apache Kafka**
If `kafka.service` is running, these settings are recommended for its high-throughput, disk-intensive event streaming workload. Kafka relies heavily on the OS page cache, so memory and filesystem tuning are critical.
* **Kernel Parameters (`sysctl`)**:
* **Virtual Memory**:
* `vm.swappiness = 1`: **Most critical setting.** Prevents the kernel from swapping out the JVM or the page cache, which would severely degrade performance.
* `vm.dirty_background_ratio = 5`: Starts flushing dirty pages to disk in the background sooner.
* `vm.dirty_ratio = 20`: Limits the total amount of memory that can be filled with dirty pages. These settings help smooth out disk I/O and avoid I/O storms.
* `vm.zone_reclaim_mode = 0`: On NUMA systems, this prevents the kernel from aggressively reclaiming cache memory from a node, which is beneficial for Kafka's page cache usage.
* **Filesystem**:
* `fs.file-max = 1000000`: Increases the system-wide limit of open file descriptors to handle Kafka's numerous log segment files.
* **Networking**:
* `net.core.somaxconn = 65535`: Handles a high number of concurrent connections from producers, consumers, and other brokers.
* `net.ipv4.tcp_rmem = 4096 87380 16777216`: Increases the TCP receive buffer size.
* `net.ipv4.tcp_wmem = 4096 65536 16777216`: Increases the TCP send buffer size.
* `net.ipv4.tcp_keepalive_time = 60`: Reduces keepalive time to detect failed connections faster.
* **systemd Resource Limits**:
* **Proposal**: Create an override file to increase the open file descriptor limit for the Kafka process.
* **Command**: `systemctl edit kafka.service`
* **Content for override.conf**:
```ini
[Service]
LimitNOFILE=1000000
```
---
### Kernel Parameter Calculation Method
* The following parameters are calculated based on the number of CPU cores and memory. These calculated values are intended to override or supplement the static values provided in Level 1 where applicable. The `min()` function denotes a logical minimum to be applied during calculation.
* `nproc`: Number of CPU cores.
* `memory`: Total memory in kilo bytes.
* `PAGE_SIZE`: Typically 4096 bytes (4 KB) on most systems.
* `kernel.threads-max`: `nproc * 1024`
* `kernel.pid_max`: `nproc * 1024`
* `kernel.msgmnb`: `nproc * 65536`
* `kernel.msgmni`: `min(memory / 16384)`
* `kernel.msgmax`: `nproc * 65536`
* `kernel.shmmax`: `min(memory * 0.05)`
* `kernel.shmall`: `min(kernel.shmmax / PAGE_SIZE)`
* `kernel.sem`: `500 640000 (nproc * 100) (nproc * 4096)`
* `vm.dirty_ratio`: `min(60, (memory / 1024) / 2)`
* `vm.dirty_background_ratio`: `min(2, (memory / 1024) / 100)`
* `vm.min_free_kbytes`: `memory * 0.05`
* `net.core.somaxconn`: `min(65535, (nproc * 1024) / 2)`
* `net.ipv4.tcp_mem`: `min(786432, (memory / 1024) * 2) min(1048576, (memory / 1024) * 3) min(1572864, (memory / 1024) * 4)`
* `net.ipv4.tcp_max_syn_backlog`: `min(65536, (nproc * 1024) / 2)`
* `net.core.netdev_max_backlog`: `min(250000, (nproc * 1024) / 2)`
* `net.core.rmem_default`: `min(8388608, (memory / 1024) * 2)`
* `net.core.rmem_max`: `min(16777216, (memory / 1024) * 4)`
* `net.core.wmem_default`: `min(8388608, (memory / 1024) * 2)`
* `net.core.wmem_max`: `min(16777216, (memory / 1024) * 4)`
* `fs.aio-max-nr`: `min(1048576, (memory / 1024) * 2)`
* `fs.epoll.max_user_watches`: `min(8192 * nproc)`
* `fs.file-max`: `min(1048576, (memory / 1024) * 2)`ざっくり説明していきます。
Execution Modes
tuning
tuningと入力すると
- 各種OSやリソース情報を収集
- 基本的な設定
- Cloudに合わせたOverride
- Middlewareに合わせたOverride
tuningsim
tuningsimと入力すると
- 各種OSやリソース情報を一部仮定しtuningを実行します。
もしmacOSで動いてた場合
tuningsimと同じです。
Default Assumptions for Tuning Simulation
仮の情報を記述しています。
- Operation System: Debian Stable
- CPU: 8 Cores
- Memory: 16GB
- Disk: SSD
Tuning Strategy
ここはめっちゃ細かいです・・・😅
実際読んで貰うとわかるのですがざっくり以下のような記述をしています。
- 様々な条件
- 現状の状態
- 情報源
- Swapに関する注意事項
- 各種情報源の取得方法やその解説
- 出力先
本当に細かいので、これから管理するのが大変だなと・・・🤣
Level 1: Generic Base-line Kernel Settings
見ての通りでざっくりこれくらいだろうというチューニングをいれたベースラインを設定しています。もっと入れようか迷ったパラメータもありますが、進まなくなるので一旦のラインにしています。
また若干小さすぎるリソースのVMは無視して、リソースからの計算に任せようとしています。(めちゃくちゃ紆余曲折してます🤣
CloudだけではなくBaremetalも意識しています。
どこかのCloudでは効かないパラメータがあるのもわかっていますが、現時点では無視して進めます。
Level 2: Cloud Platform-Specific Overrides
これはそれぞれのCloudにおける差分を吸収するセクションです。
現時点ではそれぞれの仮想化基盤の差分まで調査していません。
正直言うとChatGPTとGeminiと対話して決めました🤣
そもそもこれが使えるものになるか、このgemini-cliへ渡すMarkdownを作ってる段階ではわからないので、うまくいきそうならちゃんと調査します😆
Level 3: Application-Specific Overrides
起動しているサービスから適応すべきParameterの分岐を構成しています。
一応、Tuning Strategyでプロセスの状態やsystemdの状態を取得して、そこから提案してくれます。
ちょっと現時点で不安なのが・・・
めっちゃいろいろあるMiddlewareに対してそれぞれ個別に設定していくのは良いが・・・Token量が・・・大丈夫なのか・・・😅
バッククオートで別のMarkdownに分けることもできるけど、稀に無視されてしまうことや調査方法が変わってしまうこともあるため現時点では一旦このまま進めます。
あんまり分けてもなぁ・・・
どっちがいいんだろう・・・🤔
まあでも細かい話は一旦ここでは良いとしてLinux Kernel ParameterのTuningが便利になるかを試したいので前進しましょう😆
Kernel Parameter Calculation Method
ここはそれぞれのParameterの計算式を記載しています。
これはChatGPTやGeminiを併用して、何度も記述を精査してgemini-cliが理解できるものにはなってると思います。
確認
一応、gemini-cliに読み込ませて指摘させるとswap関連以外の指摘とその他小さなものしか出てこないと思います。個人的にもそれほど重要ではないので良いかな
それでは実行してみる
ここではテストとしてmacOS上のlimaのdebianで動かしています。
gemini
@docs/LinuxKernelParameterTuning.md tuning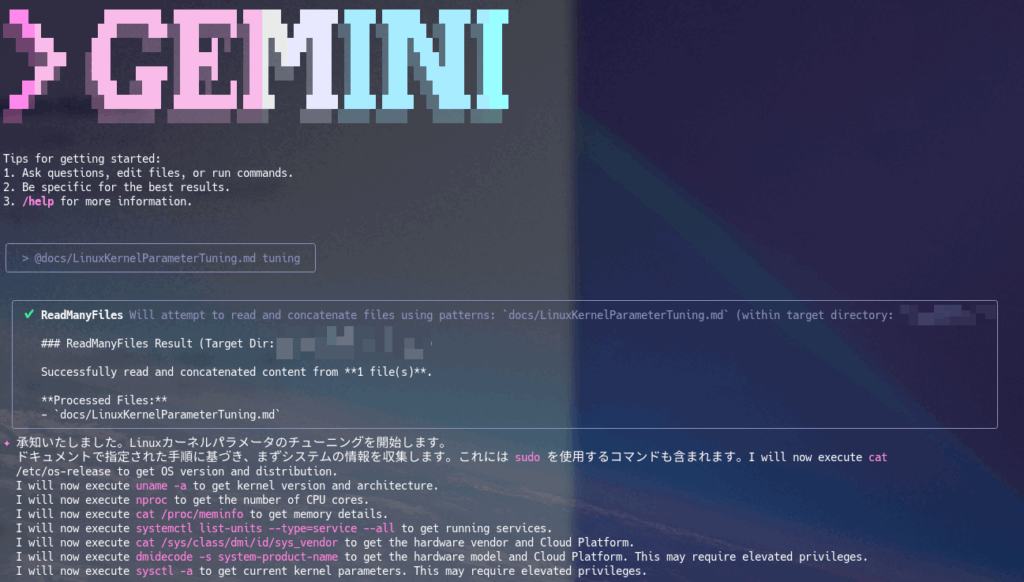
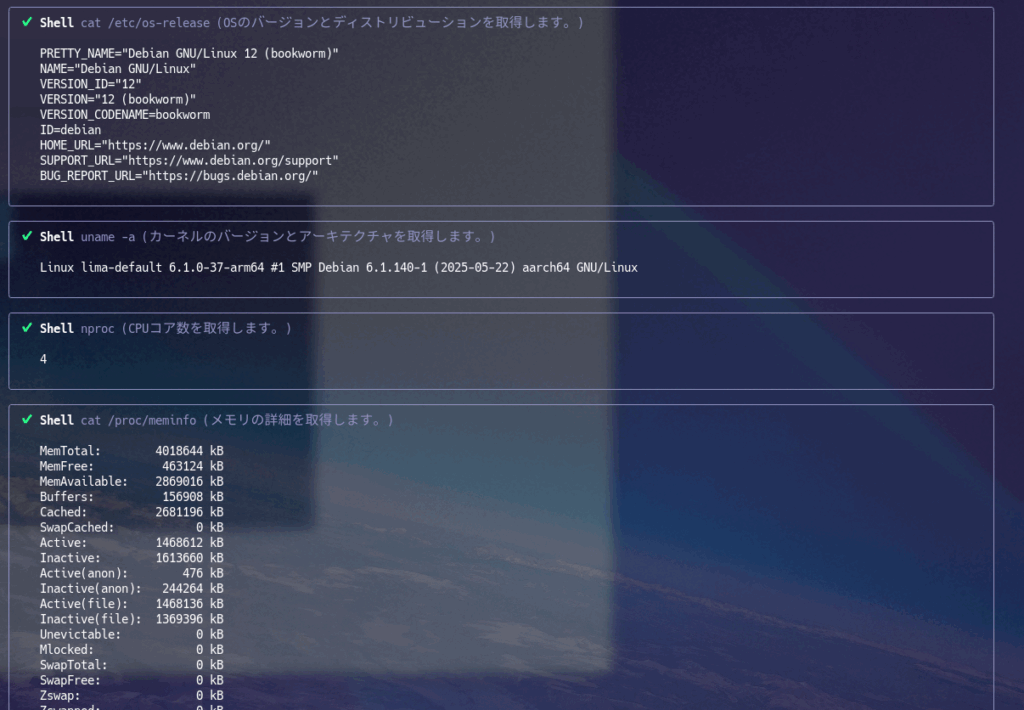
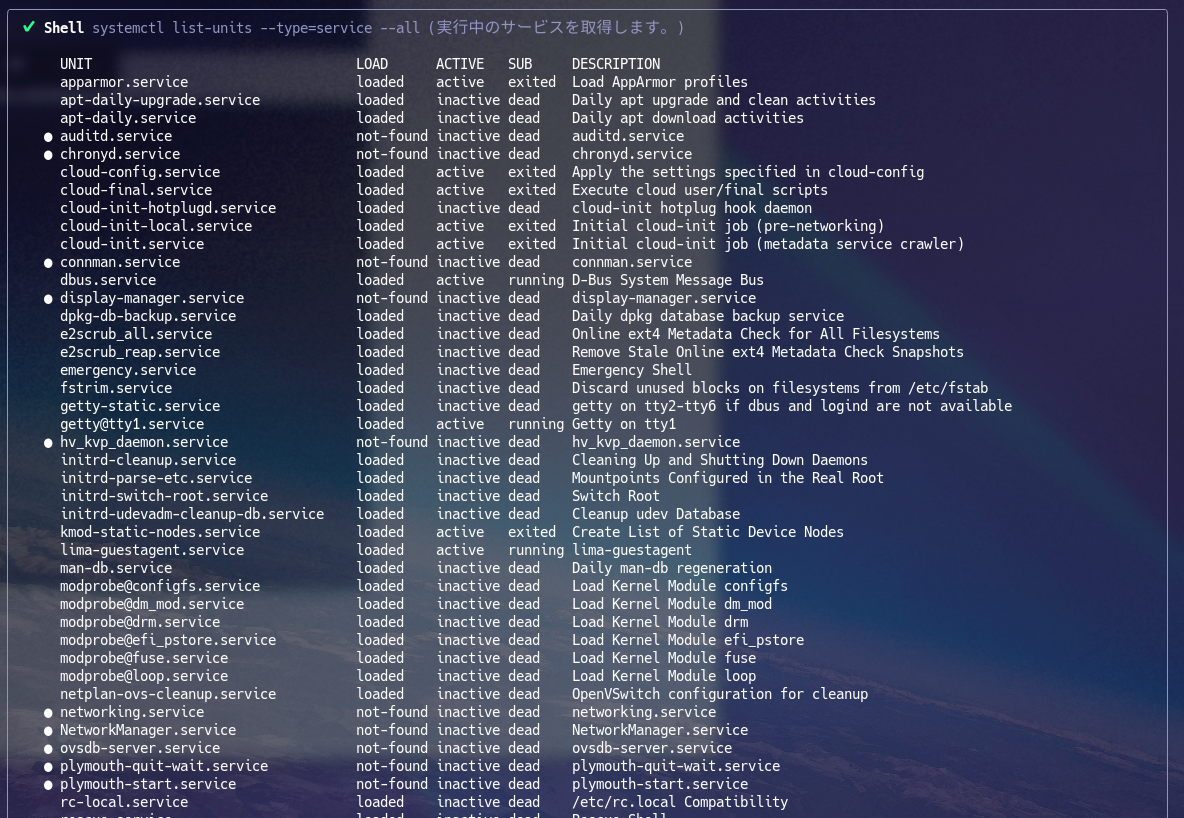
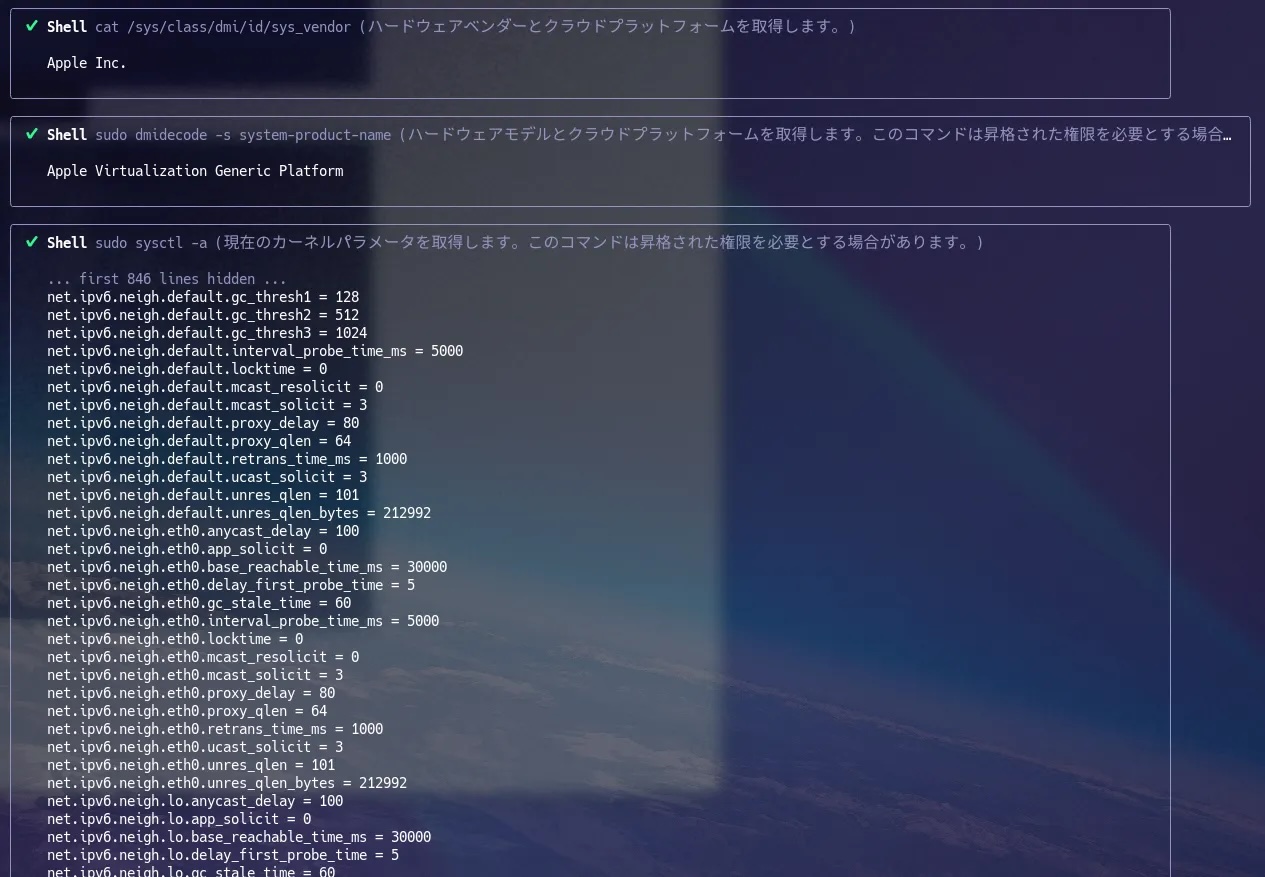

各種情報収集から、そのHost(あえてVMと言わない)がどのような目的のHostなのかを判断して提案してくれています。
実際はこのあとに待ち受けてくれるので、そこから更にやり取りをすることもできます。
t-recでgifにしてみたんですがめちゃくちゃデカくて無理でした🤣
個人的な感想
ぶっちゃけ、やれそうな気がしてきました!🤣
けっこういい線、行ってるかもしれないですね。
実際にこういった細かいパラメータ調整は、一人でやることが多くちょっと悩むこともあるので、良い壁打ち相手ができたというのが率直な意見です。
もうちょっと時間をかけてMarkdownを作る価値があるかもしれないなと感じてます。
実は最初に、何かscriptを作って計算式も適応してみたいなことを考えたんですが、
- 考慮しなくてはいけないことが多すぎる
- 条件が多すぎる
結論として難しいなと判断しました。そこでgemini-cliを使ってみようと思った最初のきっかけでした。
一応それなりにしっかりパラメータは入れてはいますが、万能かというとまだまだです。完成かというとまったく違い以下の問題があります。
- 各種調査の実行も毎回変わります。もっと明示的にcodeでMarkdownに書いたらとかいろいろ考えてます。
- 各パラメータの計算も実際に行われているかのすべての確認などできていません。
- 実際に負荷をかけてる状況で実行する必要があり、けっこうgeminiがガクガクの動作になる🤣(これも紆余曲折があり、当初はshellscriptで各種Linuxの状態をtextデータとしてかき集めたものを読み込ませる手法を取っていましたが、解釈が曖昧になっているようで、コマンド実行させる形に変えました。)
- 提案だけでなく、適用しようとしてきたりもする・・・
それだけではなく、それぞれもっと突き詰めないといけない部分も多いのでProduct環境で使うのは、ご自身の責任で!
いずれにしても、2025/07/10の現時点で行けそうな感触であること、Markdownも未完成であること、今後geminiのmodel自体もgemini-cliもupdateしまくりだと思うので今後に期待と同時にこのMarkdownを温めて行こうと思いました。
私は、サッカー⚽️を題材にしたほにゃららに影響を受けて、コンピュータは友達と思ってるタイプなのですが🤣
自分は双子座なので、gemini-cliの登場で生き別れた自分の双子の相方(実際はいませんよ😅)を見つけた気持ちです♊️😂
Googleさん使いやすい金額にしてください!!
ターミナル環境について他の記事も書いているので、よろしければこちらもご覧ください!
『ターミナルがダサいとモテない』シリーズ一覧
転載:ターミナルがダサいとモテない。gemini-cliでLinuxのKernel Parameter Tuningをしてみる。



