

目次
こんにちは、エンジニアの nishino です。
前回は Vertex AI を使うと MLOps の設計が簡単になる、というお話をさせていただきました。
今回は、前回の続きで Vertex AI が出した評価結果の読み解き方、解釈の仕方についてお伝えします。モデルをトレーニングするときに考えること、どう解釈して次に進むのか、その道しるべになると良いなと思っています。
Vertex AI に限定しない、機械学習の物体検出領域の評価全般に通ずる考え方になります。
▼ 前回の記事はこちら

まず利用するモデルを知ること
まず初めに Model Garden で利用するモデルの制約や特徴について確認するようにしましょう。モデルの正しい使い方が記載されているので、理解することでスムーズに進められるかと思います。
今回の記事では AutoML モデルをベースに進めていきます。一例として下記リンクから AutoML Vision Image Object Detection を確認ください。Best practices and limitations が掲載されており、トレーニングで利用するデータセット(画像)はこれらの制約に従う必要があります。
提供される評価指標
Google Cloud API ベースまたは Google Cloud コンソール(Vertex AI セクションでモデルレジストリページ)のどちらかからトレーニングが完了したモデルの評価を確認できます。
AutoML モデルを利用してオブジェクト検出のトレーニングをしたときに提供される評価指標一覧です。各指標の数値を見る前に2つのしきい値である Confidence(信頼度)と IoU(Intersection over Union、物体検出における評価指標の一つ)を決める必要があります。ミッションクリティカルで無く、特にこだわりがなければ便宜上0.75(4分の3)として設定することをおすすめします。実際にモデルを利用するときにどれだけの信頼度が欲しいのか、IoU によって各指標の望ましい数値が変わるので、これらを先に決める必要があります。
| 指標(英語) | 指標(日本語) | 備考 |
|---|---|---|
| Average precision(boundingBoxMeanAveragePrecision) | 平均適合率 | 信頼度と IoU しきい値のあらゆる組み合わせでの平均適合率 |
| Precision | 適合率(精度) | 正と予測したデータのうち、実際に正であるものの割合 |
| Recall | 再現率 | 真に正であるデータのうち、正と予測したものの割合 |
| f1Score | F値(F1スコア) | Google Cloud API から確認できる |
こちらは実際に実行してみたスクリーンショットです。
表示された数値やグラフの印象に左右されないよう薄いモザイクをかけています。
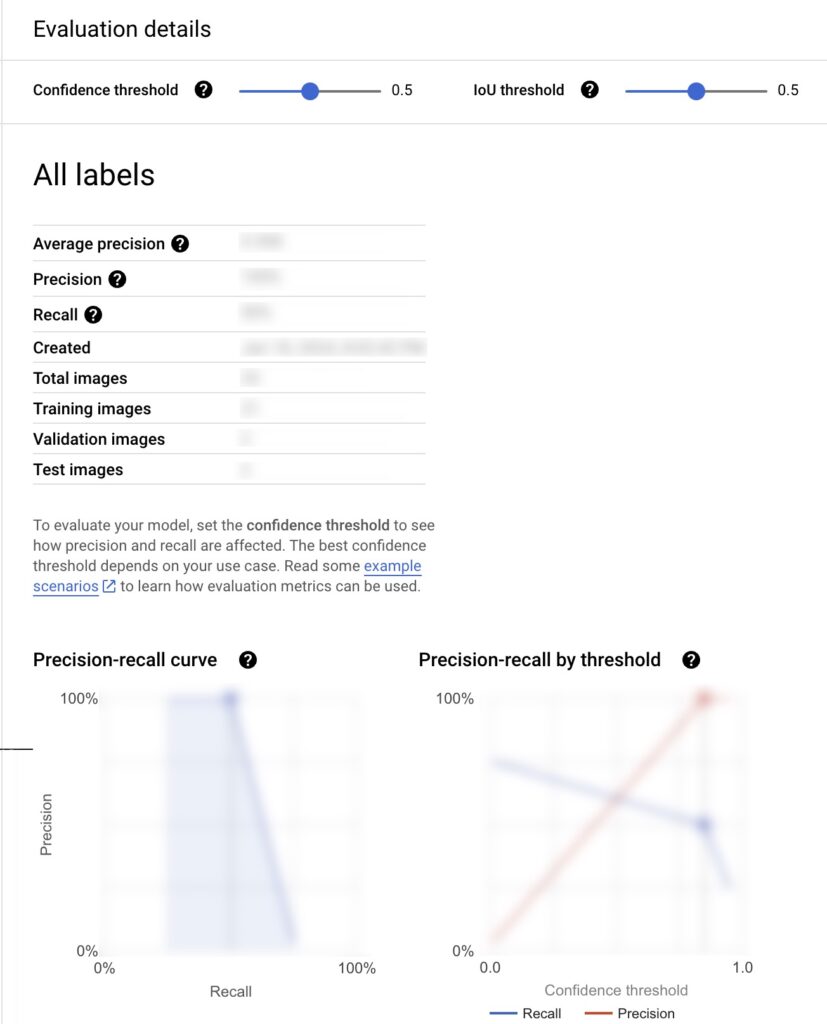
上記の評価ページにある各指標は下記のように解釈することができます。
見る順番としておすすめの順番に並べています。
- Average precision(平均適合率)
- Confidence threshold(信頼しきい値)
- IoU threshold
- Precision-recall curve(適合率と再現率の曲線)
- Precision(適合率)
- Precision-recall by threshold(しきい値ごとの適合率と再現率)
- Recall(再現率)
| おすすめの見る順番 | 指標 | 解釈 |
|---|---|---|
| 1 | Average precision(平均適合率) | こちらの数値は0~1で数値が低いとトレーニングに利用したデータを根本的に見直したほうがよさそう |
| 2 | Confidence threshold(信頼しきい値) | 推論時にどれだけの信頼度が必要なのか決めて設定しましょう |
| 3 | IoU threshold | 推論時の Bounding Box がどれだけの IoU になるべきか決めましょう |
| 4 | Precision-recall curve(適合率と再現率の曲線) | できる限り高い Precision を維持しつつ高い Recall もとれたらいいねという前提ですが実際はどうなのか可視化されている |
| 5 | Precision(適合率) | 高ければ高いほど良いですが、思ったよりも高すぎるときに学習に利用したデータがテストにも利用されていないか確認したほうがよい |
| 6 | Precision-recall by threshold(しきい値ごとの適合率と再現率) | 都合よく Precision も Recall が同時に高くなることはなく、指定した信頼度での Precision と Recall が可視化される |
| 7 | Recall(再現率) | 高ければ高いほど良い |
上記の結果を見てすべての指標が良ければいいのですが、良くない指標があったときは次の例のうちどちらが期待するモデルに近いか考えてみてください。
- 未検出は避けたくて、たとえ間違っていても検出扱いしたほうがマシ
- もっとも期待通りの検出結果を出してほしくて、間違った検出はなるべく見たくない
さて、期待が1に近ければ Precision が低くても Recall は高くあるべきです。期待が2に近ければ Recall が低くても Precision が高くあるべきです。
もしも何にも当てはまらないのであれば、データを見直してトレーニングをやりなおしたほうがよいと思います。その時はデータの特徴が極端に偏ってないか確認してください。データの量はもちろんあったほうが良いのですが特徴ないしカテゴリや種類別に見たときになるべく均等な数量のデータにすることが大切です。
MLOps 全体の設計についてはこちらのブログで紹介していますので、こちらもぜひご覧ください。


